1.背景介绍
数据仓库是企业在现代数字时代中非常重要的技术基础设施之一。随着数据的规模不断扩大,传统的关系型数据库已经无法满足企业对数据处理和分析的需求。因此,企业需要寻找更高效、更灵活的数据仓库解决方案。Neo4j是一种基于图的数据库管理系统,它可以帮助企业构建高性能、可扩展的数据仓库。在本文中,我们将讨论如何使用Neo4j构建企业级别的数据仓库,以及其核心概念、算法原理、代码实例等方面的内容。
2.核心概念与联系
2.1 Neo4j的核心概念
2.1.1 图数据库
图数据库是一种特殊类型的数据库,它使用图结构来存储、组织和查询数据。图数据库的核心组成部分包括节点(nodes)、边(edges)和属性(properties)。节点表示数据中的实体,如人、公司、产品等;边表示实体之间的关系,如购买、工作、出生等;属性则用于描述节点和边的详细信息。
2.1.2 节点、边和关系
在Neo4j中,数据以节点和边的形式存储。节点表示实体,边表示实体之间的关系。例如,在一个社交网络中,人(节点)之间可能存在关注(边)关系。
2.1.3 路径和查询
Neo4j使用Cypher查询语言来查询图数据。Cypher语言允许用户以简洁的语法表示查询,包括查找特定路径和查找满足特定条件的节点和边。例如,可以查找两个人之间的共同朋友路径,或者查找所有工作在同一公司的人。
2.2 Neo4j与传统数据仓库的区别
2.2.1 数据模型
传统数据仓库使用关系型数据库来存储数据,数据以表格形式组织。而Neo4j使用图数据库来存储数据,数据以节点、边和属性的形式组织。这种不同的数据模型使得Neo4j更适合处理复杂的关系数据,而传统数据仓库更适合处理结构化的数据。
2.2.2 查询能力
Neo4j的查询能力与传统数据仓库相比更强大。Cypher语言允许用户以简洁的语法表示复杂的查询,而传统数据仓库的查询语言通常更复杂。此外,Neo4j可以快速查找特定路径,而传统数据仓库需要进行复杂的连接操作。
2.2.3 扩展性
Neo4j具有很好的扩展性,可以通过简单地添加更多硬件来扩展。而传统数据仓库的扩展性受限于数据库的设计和架构。
3.核心算法原理和具体操作步骤以及数学模型公式详细讲解
3.1 核心算法原理
Neo4j的核心算法原理包括图数据结构、图算法和Cypher查询语言。图数据结构用于存储和组织数据,图算法用于处理图数据,Cypher查询语言用于查询图数据。
3.1.1 图数据结构
图数据结构包括节点、边和属性。节点表示数据中的实体,边表示实体之间的关系,属性用于描述节点和边的详细信息。图数据结构可以用以下数学模型公式表示:
$$ G = (V, E) $$
其中,$G$ 表示图,$V$ 表示节点集合,$E$ 表示边集合。
3.1.2 图算法
图算法是用于处理图数据的算法。常见的图算法包括短路算法、连通性算法、最大匹配算法等。这些算法可以用来解决各种实际问题,如路径查找、组件分析、流量分配等。
3.1.3 Cypher查询语言
Cypher查询语言是Neo4j的查询语言,用于查询图数据。Cypher语言允许用户以简洁的语法表示查询,包括查找特定路径和查找满足特定条件的节点和边。
3.2 具体操作步骤
3.2.1 创建节点和边
在Neo4j中,可以使用以下步骤创建节点和边:
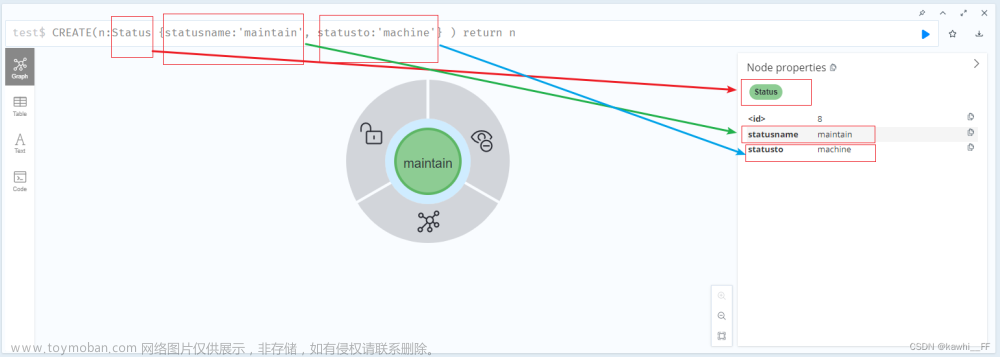
- 创建节点:使用CREATE命令创建节点,并为节点设置属性。例如,创建一个人节点:
$$ CREATE (p:Person {name: 'Alice', age: 30}) $$
- 创建边:使用CREATE命令创建边,并为边设置属性。例如,创建一个工作关系边:
$$ CREATE (p1)-[:WORK_AT]->(p2) $$
3.2.2 查询节点和边
可以使用MATCH命令查询节点和边。例如,查找所有年龄大于30的人:
$$ MATCH (p:Person) WHERE p.age > 30 RETURN p $$
3.2.3 更新节点和边
可以使用SET命令更新节点和边的属性。例如,更新Alice的年龄:
$$ SET p.age = 31 $$
3.2.4 删除节点和边
可以使用DELETE命令删除节点和边。例如,删除Alice的节点:
$$ DELETE p $$
4.具体代码实例和详细解释说明
4.1 创建节点和边
4.1.1 创建人节点
CREATE (p:Person {name: 'Alice', age: 30})
4.1.2 创建公司节点
CREATE (c:Company {name: 'Google', industry: 'Technology'})
4.1.3 创建工作关系边
CREATE (p1)-[:WORK_AT]->(p2)
4.2 查询节点和边
4.2.1 查找所有年龄大于30的人
MATCH (p:Person) WHERE p.age > 30 RETURN p
4.2.2 查找所有工作在同一公司的人
MATCH (p1:Person)-[:WORK_AT]->(c:Company)-[:WORK_AT]->(p2:Person) RETURN p1, p2
4.3 更新节点和边
4.3.1 更新Alice的年龄
SET p.age = 31
4.3.2 更新Google的行业
SET c.industry = 'Internet'
4.4 删除节点和边
4.4.1 删除Alice的节点
DELETE p
4.4.2 删除工作关系边
MATCH (p1:Person)-[:WORK_AT]->(p2:Person) DELETE p1-[:WORK_AT]->p2
5.未来发展趋势与挑战
未来,Neo4j将继续发展,以满足企业需求的不断变化。主要发展趋势包括:文章来源:https://www.toymoban.com/news/detail-845547.html
- 提高性能和扩展性:随着数据规模的增加,Neo4j需要不断优化性能和扩展性,以满足企业需求。
- 增强安全性:随着数据安全性的重要性日益凸显,Neo4j需要不断提高安全性,以保护企业数据。
- 集成AI和机器学习:随着人工智能和机器学习技术的发展,Neo4j可以与这些技术集成,以提供更高级的分析和预测功能。
- 支持更多数据源:Neo4j可以继续扩展支持的数据源,以满足企业不同类型数据的需求。
挑战包括:文章来源地址https://www.toymoban.com/news/detail-845547.html
- 数据安全和隐私:随着数据规模的增加,数据安全和隐私问题日益重要,需要不断解决。
- 数据质量:随着数据来源的增加,数据质量问题可能变得更加严重,需要不断监控和处理。
- 技术难度:随着数据规模和复杂性的增加,技术难度也会增加,需要不断研究和优化。
6.附录常见问题与解答
- Q:Neo4j与传统关系型数据库有什么区别? A:Neo4j与传统关系型数据库的主要区别在于数据模型和查询能力。Neo4j使用图数据模型,更适合处理复杂的关系数据,而传统关系型数据库使用表格数据模型,更适合处理结构化的数据。Neo4j的查询能力更强大,可以快速查找特定路径,而传统关系型数据库需要进行复杂的连接操作。
- Q:Neo4j如何扩展? A:Neo4j可以通过简单地添加更多硬件来扩展,例如添加更多CPU、内存和磁盘。此外,Neo4j还支持分布式部署,可以将数据分布在多个节点上,以实现更高的性能和扩展性。
- Q:Neo4j如何保证数据安全? A:Neo4j提供了多种数据安全功能,例如访问控制列表(ACL)、数据加密和审计日志。这些功能可以帮助企业保护数据安全,并满足各种安全标准和法规要求。
- Q:Neo4j如何处理大规模数据? A:Neo4j可以通过多种方法处理大规模数据,例如使用索引、缓存和优化查询。此外,Neo4j还支持分布式部署,可以将数据分布在多个节点上,以实现更高的性能和扩展性。
到了这里,关于使用Neo4j构建企业级别的数据仓库的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!