一、前言
预训练模型提供的是通用能力,对于某些特定领域的问题可能不够擅长,通过微调可以让模型更适应这些特定领域的需求,让它更擅长解决具体的问题。
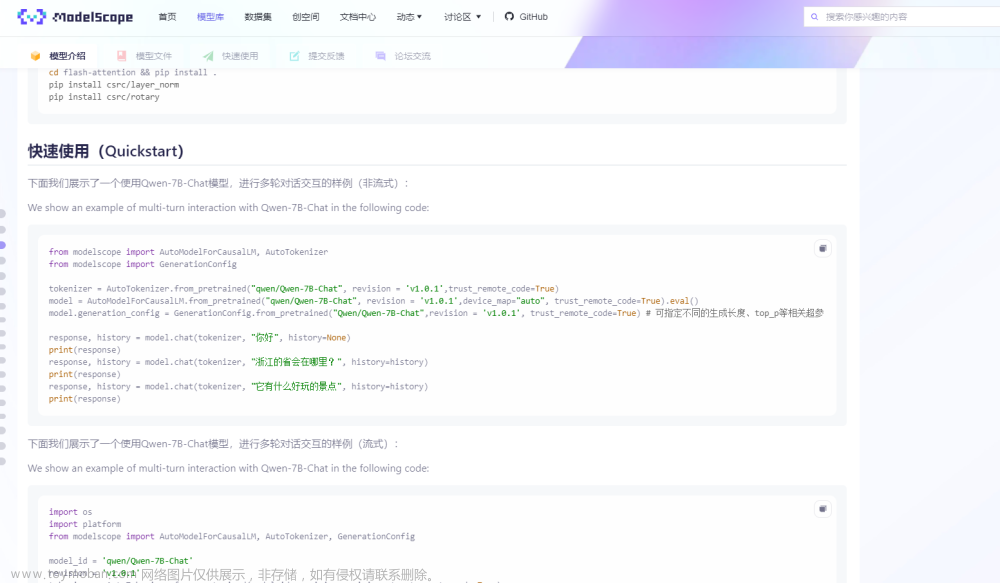
本篇是开源模型应用落地-qwen-7b-chat-LoRA微调(一)进阶篇,学习通义千问最新1.5系列模型的微调方式。
二、术语介绍
2.1. LoRA微调
LoRA (Low-Rank Adaptation) 用于微调大型语言模型 (LLM)。 是一种有效的自适应策略,它不会引入额外的推理延迟,并在保持模型质量的同时显着减少下游任务的可训练参数数量。文章来源:https://www.toymoban.com/news/detail-845699.html
2.2. Qwen1.5
Qwen1.5 is the beta version of Qwen2, a transformer-based decoder-only language model pretrained on a large amount of data. In comparison with the previous released Qwen, the improvements include:文章来源地址https://www.toymoban.com/news/detail-845699.html
- 6 model sizes, including 0.5B, 1.8B, 4B, 7B, 14B, and 72B;
- Significant performance improvement in human preference for chat models;
- Mul
到了这里,关于开源模型应用落地-qwen1.5-7b-chat-LoRA微调(二)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!