滑动窗口大致分为两类:一类是窗口长度固定的,即left和right可以一起移动;另一种是窗口的长度变化(例如前五道题),即right疯狂移动,left没怎么动,这类题需要观察单调性(即指针)等各方面因素综合思考
长度最小的子数组
长度最小的子数组
题目解析
- 子数组需要为连续的区间
- 需要在满足条件的前提下长度最短
算法原理
-
暴力解法:暴力枚举出所有子数组的和
-
枚举子数组左右区间,枚举子数组时间复杂度为O(n2),遍历求和是O(n)。所以时间复杂度是O(n3)

-
在都为大于0的数的情况下,加的数越多,和越大,所以这里牵扯到了单调性。
-
先固定一个left左区间,用一个sum统计以left为左区间所有数的和,即让right开始移动,此时相比于暴力解法剩去了一趟遍历,此时优化成O(n2)

-
当right移动到2时,sum此时已经大于target,说明已经找到了复合的子数组,此时记录长度,并让right继续移动,继续枚举直至全部枚举完

-
-
但随着right向后移动,虽然sum可以一直增长满足条件,但是len已经在不断增长,不符合题意,所以right在移动到2的时候就可以停下来了
3. **之后left继续移动到下一个数字3,此时我们会让right重新回到3的位置,但此时我们发现,在left处于2时,随着right的移动图示中红框的部分我们其实已经知道了,即用当时所求的sum减2即8-2=6即可,这样也剩去了接下来的遍历枚举,并且right也不需要回到原来的位置。**
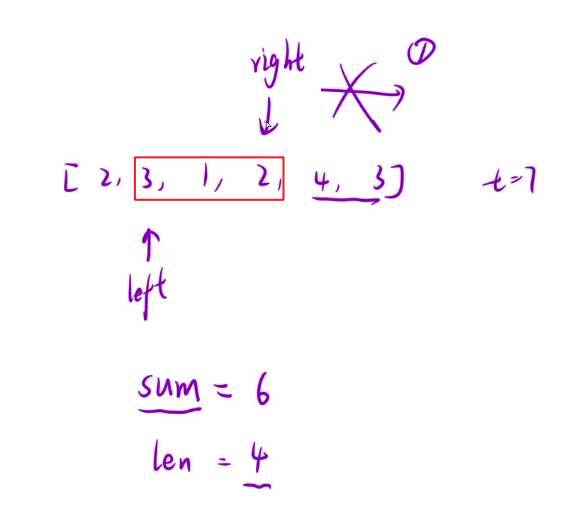<br />
- 优化——利用单调性,使用”同向双指针“进行优化(同向双指针又叫做滑动窗口)
滑动窗口一般是用来维护信息,即本题中我们通过[left,right]这个区间维护这个区间的sum。当做题用暴力解法时发现两个指针同向移动不回退时,可以用滑动窗口。
-
初始化窗口,先定义两个指针left,right让其充当窗口的左端点右端点

-
进窗口
- 初始化完之后,right进入窗口,sum开始更新为2,然后开始做判断
-
判断是否出窗口
- 让sum与target作比较,如果sum<target,不出窗口(先让right移动到合适的位置,即使sum>target)。让数字继续进窗口,即让3继续进,更新sum,再与target进行比较。直至right移动到2时,sum>target,此时找到了区间,更新结果len,令len=4.更新完之后出窗口,即left右移。left移动到3时,判断发现sum<target,此时继续进窗口,即right右移。如此循环
(b,c一直循环)

更新结果这一步,需要结合实际题目具体分析,有时候需要进窗口的时候更新结果,有的时候需要出窗口时更新结果,此题出窗口前更新结果。
滑动窗口的正确性:利用单调性,规避掉了很多没有必要的枚举
时间复杂度:从代码角度看,好像是两层循环嵌套,时间复杂度似乎也是O(n2),但是实际情况我们对窗口进行操作时,left、right每次只移动了一步(即我们的两个指针不回退),最多两个一共移动n+n次,即时间复杂度为O(n)
代码实现
class Solution {
public:
int minSubArrayLen(int target, vector<int>& nums)
{
int n=nums.size(),sum=0,len=INT_MAX;//因为len最终是要取最小值的,如果初始化为0,会影响。
for(int left = 0,right = 0;right<n;right++)
{
sum += nums[right]; //进窗口
while(sum >= target) //判断
{
len = min(len,right-left+1);
sum -= nums[left]; //出窗口
left++;
}
}
return len == INT_MAX?0:len; //如果测试用例没有结果,就返回0
}
};
无重复字符的最长字串
无重复字符的最长子串
题目解析
- 子串和子数组都是连续的一串
算法原理
-
暴力枚举+哈希表(判断字符是否重复出现)开始遍历使,将每个字母都存入哈希表里,开始移动并记录长度,对比表里是否有重复的字母。时间复杂度O(n2)

- 优化,当left在d位置时,开始遍历,right移动到a(三角形位置)时,记录长度,此时left再移动时,跳过与三角形位置相同的字母时,再让right开始移动。(这样right也不用回退,可以省去大量重复且无用的枚举)

-
滑动窗口( 时间复杂度O(n),空间复杂度O(1) )
- 初始化窗口,定义两个指针,充当窗口的两个端点
- 进窗口,让字符进入哈希表
- 判断,出窗口:当窗口内出现重复字符时,left移动,当left跳过与right相同字母的位置时,将哈希表中与right重复的字母删除,将字母频次变为1。

代码实现
class Solution {
public:
int lengthOfLongestSubstring(string s) {
int hash[128] = {0}; //用数组模拟哈希表
int left = 0,right = 0,n=s.size();
int ret = 0;
while(right<n)
{
hash[s[right]]++; //进入窗口
while(hash[s[right]] > 1) //判断
{
hash[s[left++]]--; //出窗口,哈希表--,然后移动left, ++
}
ret = max(ret,right-left+1); //判断
right++; //让下一个元素进入窗口
}
return ret;
}
};
最大连续1的个数
最大连续1的个数
题目解析
题目中翻转指的是可以把0变为1。
转化:找出最长的子数组,0的个数不超过k个
算法原理
-
暴力枚举+zero计数器
- 固定一个起点,向后枚举出所有子数组,找出符合条件的子数组(即0的个数不超过k),比较长度
-
开始优化——滑动窗口
-
固定left为第一个位置,移动right,当数字是1时,忽略1,如果是0,计数。当zero统计的数字大于k时right不动。移动left,当left越过一个0,在开始继续移动right

-
固定left为第一个位置,移动right,当数字是1时,忽略1,如果是0,计数。当zero统计的数字大于k时right不动。移动left,当left越过一个0,在开始继续移动right
- 滑动窗口三步走
- 初始化窗口
- 进窗口:向右移动right,碰到1无视,碰到0计数器+1
- 出窗口&判断:zero>k,不合法,出窗口(left移动,遇到1无视,遇到0,计数器-1,直至zero<k时更新结果)

代码实现
class Solution {
public:
int longestOnes(vector<int>& nums, int k) {
int ret = 0;
for( int left = 0,right = 0,zero = 0;right < nums.size(); right++)
{
if(nums[right] == 0) zero++; //进窗口
while(zero > k) //判断
if(nums[left++] == 0) zero--; //出窗口
ret = max(ret,right-left+1); //更新结果
}
return ret;
}
};
将x减到0的最小操作数
将x减到0的最小操作数
题目解析
- 题目中给的数组所有的元素都是大于1的,如果有的数小于等于1,单调性不存在,是无法使用滑动窗口的
- 每次从数组最左边或者最右边删掉一个数,删完之后在新的数组中进行后续操作

算法原理
- 正难则反,正常情况下是在左边选一个区间,右边选一个区间,让这两个区间的和等于x,就可以满足。但是正面作战不利,我们可以反过来,在中间部分找一个连续的区间,使他们和为sum-x也行。(这里的sum是整个数组的和)。
- 题目还要求操作次数最短,即找的两边的区间长度需要最短,那换言之就是使中间的区间长度最长即可。

-
暴力枚举:固定left和right,用sum标记[left,right]所指的这段区域的和,判断sum和target之间的关系,如果sum<target,right++;直至right移动到使sum>target的位置,right不动,开始移动left。
-
滑动窗口
- 初始化窗口。
- 进窗口:sum±nums[right]。
- 出窗口&判断:sum>target, 出窗口sum-=nums[left]; left++; 然后判断出窗口如此循环,直至sum==target,更新结果。
- 更新的结果只是子数组的长度len,不要忘记n-len才是我们最终想要求的结果。

代码实现
class Solution {
public:
int minOperations(vector<int>& nums, int x) {
int sum = 0;
for(int a:nums) sum += a;
int target = sum-x;
//细节问题:如果有小于0的元素,单调性不存在
if(target < 0) return -1;
int ret = -1; //防止有小于0的元素
for(int left = 0,right = 0,temp = 0;right < nums.size();right++) //temp代替sum
{
temp+=nums[right]; //进窗口
while(temp > target ) //判断
temp -= nums[left++]; //出窗口
if(temp == target)
ret = max(ret,right-left+1);
}
if(ret == -1) return ret;
else return nums.size()-ret;
}
};
水果成篮
水果成篮
题目解析
- 只能装两种水果
- 可以从任意位置开始,但是必须每一棵数上都要采摘
- 所摘的水果需要和当前篮子中的水果一致,采摘完之后向右移动
- 如果这棵树和篮子中的水果不一致,要立即停止采摘
转化:找出一个最长的子数组,且子数组中的水果种类不能超过两种
算法原理
-
暴力枚举+哈希表:把所有子数组都找出来,哈希表统计种类。

- 固定left,开始让right向右移动,统计kind,当kind大于2的时候,让right停下来,此时思考right是否需要回退(如图所示情况,不需要回退)right可以随着left++后跟着右移。这时可以使用滑动窗口

- 滑动窗口
- 初始化窗口:left = 0;right = 0;
- 进窗口:将right所指的元素放进哈希表里,hash[fruit[right]]++
- 出窗口&判断:判断条件hash.length>2 left右移,但此时如果我们哈希表里只存储种类的话,left移动到哪里才能停下来呢?所以哈希表里还要再存储一个数量,当这个数字对应的数量为0时,把它erase掉。

代码实现
class Solution {
public:
int totalFruit(vector<int>& fruits) {
unordered_map<int,int>hash; //统计窗口内出现的水果数量
int ret = 0;
for(int left = 0,right = 0;right<fruits.size();right++)
{
hash[fruits[right]]++; //进窗口
while(hash.size() > 2)
{
//出窗口
hash[fruits[left]]--; //left位置对应的水果数量--
if(hash[fruits[left]] == 0)
hash.erase(fruits[left]);
left++;
}
ret = max(ret,right-left+1);
}
return ret;
}
};
这里因为我们频繁的向哈希表中插入数据,所以时间复杂度不是很好。观察题目要求的数据后(数据范围有限),我们可以用数组模拟哈希表。

class Solution
{
public:
int totalFruit(vector<int>& f)
{
int hash[100001] = { 0 }; // 统计窗⼝内出现了多少种⽔果
int ret = 0;
for(int left = 0, right = 0, kinds = 0; right < f.size(); right++)
{
if(hash[f[right]] == 0) kinds++; // 维护⽔果的种类
hash[f[right]]++; // 进窗⼝
while(kinds > 2) // 判断
{
// 出窗⼝
hash[f[left]]--;
if(hash[f[left]] == 0) kinds--;
left++;
}
ret = max(ret, right - left + 1);
}
return ret;
}
};

找到字符串中所有字母的异位词(固定滑动窗口)
找到字符串中所有字母的异位词
题目解析
-
异位词指相同字母重新组合排列产生的新字符串
-
返回这些子串的起始位置

算法原理
- 如何快速判断两个字符串是异位词
- 分别给两个字符串排序,检查两个是否相等。但是时间复杂度是O(nlogn+n)
- 用哈希表:分别遍历记录字符串字母对应位置出现的次数

- 暴力解法:固定不同的位置依次放入哈希表遍历,将结果与p进行比较,如果相等返回起始位置

- 滑动窗口:我们发现,在我们进行第二次开始将子串放入哈希表时,中间部分“ba”是一样的,只有c和e不同,所以我们第二次遍历时只需要将c删掉换成e即可,以此类推。即left和right一起移动
- 初始化窗口:left = 0;right = 0;
- 进窗口:
- 判断&出窗口:这里判断条件当right右移之后,我们的窗口变大了,为了保持和p的len一致,我们只需要让left移动一步即可,这样也就让窗口整体移动了。此时出窗口只需要出一次,不需要再和之前的题一样循环判断
- 更新结果:仅需判断hash1和hash2是否一样就行。因为窗口小的话是一定不会符合题意的,所以这时候不需要更新结果,只需要在窗口大小一致的时候检查更新结果即可
这里也可以利用数组模拟哈希表,因为题目中说都是小写字母,那么我们可以设置一个大小为26的数组,在数组为0的位置放a,为1的位置放b…让里面存储的值表示出现的次数,这样我们在判断hash1和hash2时只需要比较26次。这里的时间复杂度为O(n)

- 优化更新结果的条件:利用count统计窗口里有效字符的个数
-
进窗口维护:当right进入窗口,统计第一个字符为c,此时记录c的次数为1,P中的c也出现了一次,(当窗口中的c出现次数小于等于P中,此时能相互匹配,这时c为有效字符),令count++,right移动下一个位置c,这时c出现了两次,但是P中只出现了一次,即不是有效字符,count不变,right继续往下移动到a…此时count等于3(P的长度),则此时窗口中全是字母的异位词,返回left的位置即可。

-
出窗口维护:当窗口大于P的长度时,需要移动left即出窗口删掉字符,left移动到第二个c之前我们可以观察此时窗口中c的次数为2大于P中的,即为无效字符,所以count不需要变化。left移动到第二个c之后,c变为一次,此时是P的异位词,输出起始位置。同理left移动到字符b时(此时c仅一次,小于等于P),c为有效字符,改变count的值为2,这时只需要判断count是否等于P的长度就能从而决定我们是否要更新结果。

-
代码实现
class Solution {
public:
vector<int> findAnagrams(string s, string p)
{
vector<int> ret;
int hash1[26] = { 0 }; // 统计字符串 p 中每个字符出现的个数
for(auto ch : p) hash1[ch - 'a']++;
int hash2[26] = { 0 }; // 统计窗⼝⾥⾯的每⼀个字符出现的个数
int m = p.size();
for(int left = 0, right = 0, count = 0; right < s.size(); right++)
{
char in = s[right];
// 进窗⼝ + 维护 count
++hash2[in - 'a'];
if(hash2[in - 'a'] <= hash1[in - 'a']) count++;
if(right - left + 1 > m) // 判断
{
char out = s[left++];
// 出窗⼝ + 维护 count
if(hash2[out - 'a'] <= hash1[out - 'a']) count--;
hash2[out - 'a']--;
}
// 更新结果
if(count == m) ret.push_back(left);
}
return ret;
}
};
串联所有单词的子串
串联所有单词的子串
题目解析
- 字符串数组words中所有子串长度相同(这点十分重要,否则该题时间复杂度很高)
- 例如,如果 words = [“ab”,“cd”,“ef”], 那么 “abcdef”, “abefcd”,“cdabef”, “cdefab”,“efabcd”, 和 “efcdab” 都是串联子串。 “acdbef” 不是串联子串,因为他不是任何 words 排列的连接。
- 返回所有串联子串在 s** **中的开始索引。你可以以 任意顺序 返回答案。
算法原理
先将s的字符串按照w中长度的进行划分:
- hash存储:用hash<string,int>存储,即string存储字符串,int存储字符串出现的次数。
- left与right指针移动:移动的步长,是单词的长度。
- 滑动窗口执行的次数:如图所示(紫色、绿色、蓝色 从0、1、2三个位置分别开始划分滑动),再往下划分的情况与第一种情况相比只是少了第一个字、符,所以结果会重复,故一共三次,即为len次(w的长度)。

代码实现
class Solution {
public:
vector<int> findSubstring(string s, vector<string>& words) {
vector<int>ret;
unordered_map<string,int> hash1; //保存world单词出现的次数
for(auto&s :words) hash1[s]++;
int len = words[0].size(),m = words.size();
for(int i = 0; i < len; i++) //执行len次
{
unordered_map<string,int> hash2; //维护窗口内单词的频次
for(int left = i,right = i,count = 0; right+len <= s.size();right+=len)
{
//进窗口+维护count
string in = s.substr(right,len); //将要进窗口的字符串裁出来,从right位置开始,长度为len的子串
hash2[in]++;
if(hash1.count(in) && hash2[in] <= hash1[in]) count++;
/*这里hash1中不一定有in,hash[]的特性是如果没有in会再重新创建一个,
较消耗时间复杂度。所以可以先加一个判断条件hash1.count(in)*/
//判断
if(right-left+1 > len*m) //当大于words的总长度时,移动窗口
{
//出窗口+维护count
string out = s.substr(left,len);
//这里同理
if(hash1.count(out) && hash2[out] <= hash1[out]) count--;
hash2[out]--; //出窗口,即哈希表里的字符数--
left+=len; //left移动
}
//更新结果
if(count == m) ret.push_back(left);
}
}
return ret;
}
};
最小覆盖子串
最小覆盖子串
题目解析
- 在s中找一个连续的子字符串,使其能涵盖t中所有字符即可,s中子字符串出现的次数大于t中也可以
- 返回符合条件的子串,所以需要标记起始位置

算法原理
- 暴力解法+哈希表:枚举出所有符合条件的子串,找出最优。
- 分别在hash1和hash2中统计字符出现的次数,在每一次的遍历中,比较hash2中出现的次数是否大于等于hash1中出现的次数即可。
- 选一个位置作为起点left,然后定义right从left位置开始遍历,直到找到符合要求的最短的区间,然后right停止,此时让left向右移动
- 当left移动前的位置不是题中复合要求的字母时,结果没影响,right不需要动
- 当left移动前的位置是题中复合要求的字母时,此时就不符合要求,为了保证符合要求,right右移继续找。
- 经分析过后发现right不需要回退,left和right都是一起向右移动,即滑动窗口。

- 滑动窗口+哈希表
- 初始化窗口
- 进窗口
- 判断&出窗口:当hash2中的字符出现次数大于hash1中的字符时,即窗口合法时我们出窗口。
- 更新结果:这里的更新结果在出窗口之前。因为更新结果我们需要的是符合区间的起始位置和最短长度,所以要在出窗口之前获取

- 优化:在判断那里,我们比较两个hash出现的字符次数时,需要分别遍历两个哈希表,是非常消耗时间的,并且我们判断还不止一次。
- 这里的count和之前的不是很一样,这里的count记录有效字符的种类。即我们只看出现的A是否成立,B是否成立,C是否成立,而不再统计ABC分别出现的次数,因为该题A出现三次(大于t中的1次)成立,出现四次也成立,但这里我们只能算作一次(在同一段子字符串中可能出现多次,见题目解析),所以不能再用加和的方式去标记。
- 进窗口+维护:进窗口之后,当两个出现的次数相等时,count++(注意:这里不能像之前那样在大于等于的时候让count++,因为这样会重复统计)
- 出窗口+维护:出窗口之前,当此时出现的次数相等时,count–,(A:0->1->0)因为出窗口之后没了a有效字符的种类数减少了
- 判断条件:我们这里count是统计有效字符的种类,所以这里要比较count和hash1的长度(t的长度)
因为这里都是字符,所以我们可以定义数组来模拟hash文章来源:https://www.toymoban.com/news/detail-845968.html

文章来源地址https://www.toymoban.com/news/detail-845968.html
代码实现
class Solution {
public:
string minWindow(string s, string t) {
int hash1[128] = {0}; //统计t中出线的频次
int kind = 0;//统计有效字符种类
for(auto ch:t)
{
if(hash1[ch] == 0) kind++;
hash1[ch]++;
}
int hash2[128] = {0}; //统计窗口内每个字符出现的频次
int minlen = INT_MAX, begin = -1;
for(int left = 0,right = 0,count = 0;right<s.size();right++)
{
char in = s[right];
hash2[in]++;
if(hash2[in] == hash1[in]) count++; //进窗口+维护
while(count == kind) //判断条件
{
if(right-left+1 < minlen) //更新结果
{
minlen = right - left + 1;
begin = left;
}
char out = s[left];
left++;
if(hash2[out] == hash1[out]) count--;
hash2[out]--;
}
}
if(begin == -1) return "";
else return s.substr(begin,minlen);
}
};
到了这里,关于算法——滑动窗口的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!










