【官方框架地址】
github地址:https://github.com/ultralytics/ultralytics
【算法介绍】
Yolov8是一种先进的深度学习算法,用于目标检测任务,特别是针对图像中物体的实时检测。它是Yolov3和Yolov4之后的又一重要迭代,带来了诸多改进和新特性。本文将详细介绍Yolov8算法的原理、特点、实现细节以及与其他目标检测算法的比较。
一、Yolov8算法原理
Yolov8采用了一种称为"You Only Look Once"(YOLO)的实时目标检测方法。与传统的目标检测方法不同,YOLO将目标检测视为一个回归问题,将图像划分为网格,每个网格预测固定数量的边界框,并识别其中存在的物体。Yolov8在YOLO系列算法的基础上,引入了新的技术来提高准确性和效率。
二、Yolov8特点
高效性:Yolov8采用了轻量级的网络结构,降低了计算复杂度,实现了高效的实时目标检测。
高精度:通过引入新的损失函数和训练技巧,Yolov8在各种数据集上实现了高精度的目标检测。
多尺度特征融合:Yolov8采用了多尺度特征融合策略,提高了对不同大小目标的检测能力。
上下文信息利用:Yolov8利用了上下文信息来提高检测性能,使得模型能够更好地理解图像内容。
强大的锚框设计:Yolov8采用了强大的锚框设计,提高了预测边界框的准确性。
三、Yolov8实现细节
网络结构:Yolov8采用了轻量级的网络结构,包括卷积层、池化层和上采样层等。这种网络结构能够快速处理输入图像,并生成物体的边界框和类别信息。
损失函数:Yolov8采用了新的损失函数,包括坐标损失、置信度损失和类别损失等。这些损失函数共同作用,使得模型能够学习到更准确的边界框位置和类别信息。
多尺度特征融合:为了提高对不同大小目标的检测能力,Yolov8采用了多尺度特征融合策略。通过在不同尺度的特征图上进行预测,模型能够更好地处理不同大小的物体。
训练技巧:为了提高模型的训练效率和准确性,Yolov8采用了一系列训练技巧,包括数据增强、使用混合精度训练和使用标签平滑等。这些技巧有助于提高模型的泛化能力。
锚框设计:Yolov8采用了强大的锚框设计,根据不同的场景和任务需求,设计了多种不同大小的锚框。这些锚框能够帮助模型更好地预测物体的边界框位置。
四、与其他目标检测算法的比较
与传统的目标检测算法(如Faster R-CNN和SSD)相比,Yolov8具有更高的实时性和准确性。与YOLO系列的其他版本(如YOLOv3和YOLOv4)相比,Yolov8在准确性和效率上均有所提升。此外,与基于Transformer的目标检测算法(如DETR和Sparse Transformer)相比,Yolov8具有更快的速度和更高的准确性。
总之,Yolov8是一种高效、准确的目标检测算法,具有广泛的应用前景。它的出现为实时目标检测任务提供了新的解决方案,推动了相关领域的发展。
【效果展示】
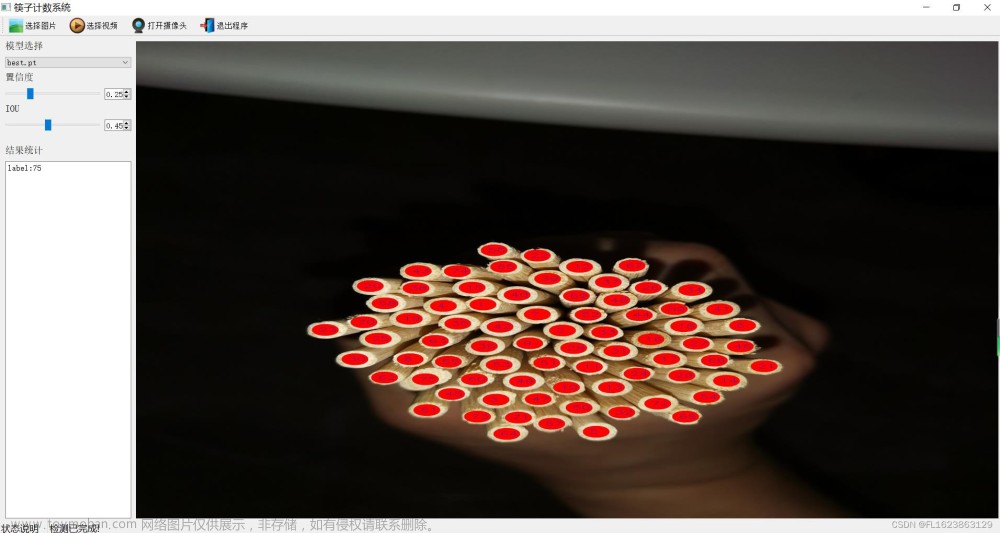
【实现部分代码】
def start_camera(self, camera_index=0):
self.signal.emit('正在检测摄像头中...','camera')
cap = cv2.VideoCapture(camera_index)
self.camera_open = True
while self.camera_open:
ret, frame = cap.read()
if not ret:
self.action_2.setText('打开摄像头')
self.camera_open = False
self.signal.emit('摄像头检测已停止!', 'camera')
break
result_lists = self.detector.inference_image(frame, False, self.dsb_conf.value(), self.dsb_iou.value())
frame = self.detector.draw_image(result_lists, frame)
res = self.get_result_str(result_lists)
self.signal.emit(res, 'res')
frame = cv2.cvtColor(frame, cv2.COLOR_RGB2BGR)
img = QImage(frame.data, frame.shape[1], frame.shape[0], QImage.Format_RGB888)
self.picture.setPixmap(QPixmap.fromImage(img))
time.sleep(0.001)
cap.release()
self.action_2.setText('打开摄像头')
self.camera_open = False
self.signal.emit('摄像头检测已停止!', 'camera')
self.picture.setPixmap(QPixmap(""))
【模型数据集】
模型采用yolov8n模型,数据集为210张筷子计数数据集,数据集详情介绍如下:
图片数量(jpg文件个数):210
标注数量(xml文件个数):210
标注数量(txt文件个数):210
标注类别数:1
标注类别名称:["label"]
每个类别标注的框数:
label 框数 = 14872
总框数:14872
使用标注工具:labelImg
数据集下载地址:
https://download.csdn.net/download/FL1623863129/88703672
【视频演示】
https://www.bilibili.com/video/BV1A94y1u7CV/?vd_source=989ae2b903ea1b5acebbe2c4c4a635ee
【源码下载】
https://download.csdn.net/download/FL1623863129/88715467
【测试环境】
anaconda3+python3.8文章来源:https://www.toymoban.com/news/detail-846140.html
yolov8环境
文章来源地址https://www.toymoban.com/news/detail-846140.html
到了这里,关于[python]使用pyqt5搭建yolov8 竹签计数一次性筷子计数系统的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!












