本文介绍作者如何爬取雪球网(https://xueqiu.com/)沪深股市沪深一览中的上市公司日k线走势图并截图保存至本地~
欢迎关注作者公众号,追踪更多更新更有价值的内容。
一、前言
1.1 项目介绍
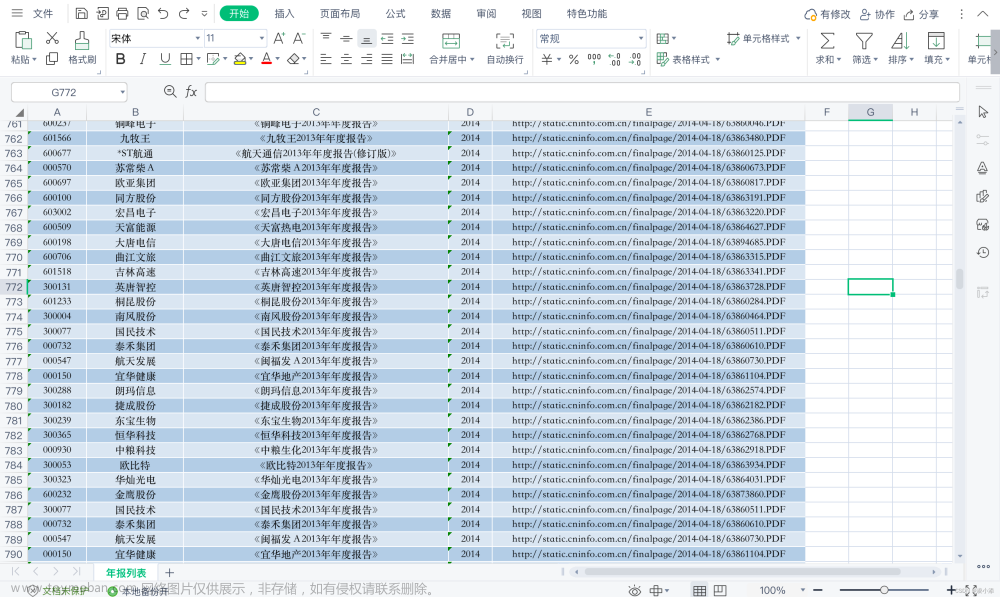
项目用于获取雪球网沪深股市沪深一览列表中(图1)上市公司的日K线图(图2)。

图1 沪深股市-沪深一览

图2 日K图
以便从中获取走势向上的公司股票。
1.2 项目地址
项目gitee地址:https://gitee.com/shawn_chen_rtz/stock_daily_trend.git
1.3 环境准备
需要安装依赖requests、selenium模块,通过pip命令。
pip install requests==2.27.1pip install selenium==3.141.0
二、代码详解
2.1 获取股票名称和股票代码
创建方法获取列表股票名称和代码,
import requests
def get_stocks():
sh_sz = []
for i in range(1, 11):
url = "https://stock.xueqiu.com/v5/stock/screener/quote/list.json?page=" + str(
i) + "&size=60&order=desc&orderby=percent&order_by=percent&market=CN&type=sh_sz"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 \
(KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36",
"Cookie": "xqat=52dfb79aed5f2cdd1e7c2cfc56054ac1f5b77fc3"
}
try:
datas = requests.get(url, headers=headers).json()['data']['list']
except KeyError:
print("可能cookie中的xqat失效,请替换")
for data in datas:
sh_sz.append({'name': data['name'], 'code': data['symbol']})
return sh_sz这里需要注意,请求的地址是https://stock.xueqiu.com/v5/stock/screener/quote/list.json?page=" + str(i)+"&size=60&order=desc&orderby=percent&order_by=percent&market=CN&type=sh_sz,其中str(i)是通过for循环变量i来控制获取分页数据,例子中暂时硬编码为1~10页的数据。当然也可以参数化,把分页数量当做方法get_stocks()的入参,可以自行优化。
另外需要注意的是,需要设置请求头headers,否则不会返回正确响应结果。其中尤其重要的是"Cookie"的设置,必不可少。"Cookie"的值可以通过浏览器访问雪球网站获取。

get_stocks()方法返回字典列表变量sh_sz。
2.2 根据股票代码获取日K线图
思路:根据遍历获取的sh_sz,取其中的股票代码拼成股票详情链接,利用selenium访问链接,关闭登录弹窗后,点击日K线,再对当前浏览窗口进行截图保存处理;
同时支持Win与Linux环境的执行,可设置无头模式执行;支持日志记录。
代码实现,如下,
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.chrome.options import Options
import time
import logging
from get_stocks import get_stocks
LOG_FORMAT = "%(levelname)s %(asctime)s - %(message)s"
logging.basicConfig(filename='stock_snapshot.log', level=logging.INFO, filemode='a', format=LOG_FORMAT)
logger = logging.getLogger()
# linux webdriver路径
# driver_path = "/usr/bin/chromedriver"
# Windows webdriver路径
driver_path = "D:\webdriver\chromedriver.exe"
# 是否设置为无头浏览模式
head_less = True
if head_less:
chrome_options = Options()
chrome_options.add_argument("--headless")
chrome_options.add_argument("--no-sandbox")
driver = webdriver.Chrome(driver_path, chrome_options=chrome_options)
else:
driver = webdriver.Chrome(driver_path)
stocks = get_stocks()
for stock in stocks:
driver.maximize_window()
driver.get(f"https://xueqiu.com/S/{stock['code']}")
# 关闭掉登录提示窗
login_win = driver.find_element_by_class_name("modal__login")
action = ActionChains(driver)
action.move_to_element(login_win).perform()
close = login_win.find_element_by_class_name('close')
driver.execute_script('arguments[0].click();', close)
# 切换日线
chart_period_ls = driver.find_elements_by_class_name("chart-period-list")
for chart in chart_period_ls:
if chart.text.strip() == "日K":
# chart.click()
driver.execute_script('arguments[0].click();', chart)
time.sleep(0.6)
driver.set_window_size(1200, 820)
driver.get_screenshot_as_file(f"{stock['name']}.png")
logger.info(f"{stock['name']}日线走势图片保存成功")重点在于登录提示窗的关闭、日K线的点击与图片快照保存,都是通过Python selenium模块实现。而selenium是一种支持多编程语言的自动化测试框架,关于其详细介绍,请访问其官方网站https://www.selenium.dev/。
三、执行结果
3.1 执行结果
执行项目,

在项目目录下生成一系列股票日K线快照。除此之外还有很多的功能值得增加、扩展。欢迎留言~文章来源:https://www.toymoban.com/news/detail-846451.html
可以关注作者微信公众号,追踪更多有价值的内容! 文章来源地址https://www.toymoban.com/news/detail-846451.html
文章来源地址https://www.toymoban.com/news/detail-846451.html
到了这里,关于利用Python和Selenium获取雪球网沪深上市公司日k线走势图的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!