导读
本文介绍了 TiDB 中 MVCC(多版本并发控制)机制的原理和相关排查手段。 TiDB 使用 MVCC 机制实现事务,在写入新数据时不会直接替换旧数据,而是保留旧数据的同时以时间戳区分版本。 当历史版本堆积过多时,会导致读写性能下降。 为了解决这个问题,TiDB 使用 Garbage Collection(GC)定期清理不再需要的旧数据。 文章从 TiDB 中 MVCC 版本的生成原理、数据写入过程和 TiDB 版本堆积常见排查手段等方面进行了详细介绍 。
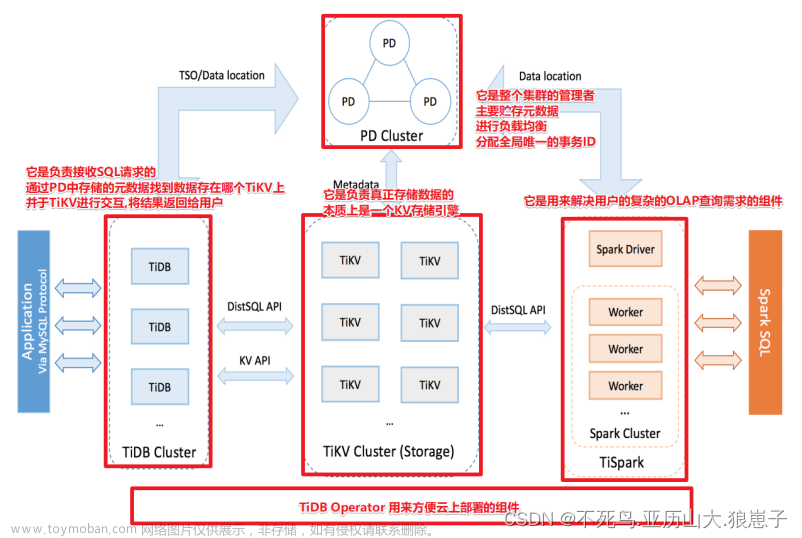
TiDB 的事务的实现采用了 MVCC(多版本并发控制)机制,当新写入的数据覆盖旧的数据时,旧的数据不会被替换掉,而是与新写入的数据同时保留,并以时间戳来区分版本。 Garbage Collection(GC)的任务便是清理不再需要的旧数据。
如上所述,TiDB 底层使用的是单机存储引擎 rocksdb, 为了实现分布式事务接口,TiDB 又采用 MVCC 机制,基于 rocksdb 实现了高可用分布式存储引擎 TiKV。也就是当新写入(增删改)的数据覆盖到旧数据时,旧数据不会被替换掉,而是与新写入的数据同时保留,并以时间戳来区分版本。当这些历史版本堆积越来越多时,就会引出一系列问题,最常见的便是读写变慢。TIDB 为了降低历史版本对性能的影响,会定期发起 Garbage Collection(GC) ( https://docs-archive.pingcap.com/zh/tidb/v7.2/garbage-collection-overview ) 清理不再需要的旧数据。
本文作为 TiDB GC 的前序文章,我们将详细介绍一下这些旧版本数据是如何堆积起来的,以及如何排查确认当前版本数据的堆积已经对集群性能构成了影响。
TiDB 中的 MVCC 版本的生成原理

- 在 TIDB 层,我们最初收到的是一个关系型表的数据,TiDB 会将这个关系型表数据转化成 key-value,同时调用分布式事务接口,将 key-value 数据写入到 TiKV。
- 在 TIKV 层,我们采用 MVCC 机制提供了分布式事务接口,最终所有的写入都会转化成一条 MVCC key-value 格式写入到 raftstore. 说到 MVCC 格式的 key-value, 无非就是每一个 key 上都有一个版本号,代表其提交的先后顺序。后面我们将这类格式的数据统一称为 MVCC key-value 对。
- 在 raftstore 层,则最终将数据以 key-value 的形式,写入到 rocksdb 中。(注意,rocksdb( https://docs.pingcap.com/tidb/stable/rocksdb-overview ) 本身基于 LSM 架构实现,所以它也有 MVCC 的概念,本文不做详细介绍,只对 TiDB 相关的内容点到为止)
数据写入过程
下面我们举个例子来详细讲讲在 TiDB 集群中,一个具体的写入过程。
当我们在 TiDB 中,执行以下 SQL 时:
insert into students set name="Bob",age=12,score=99 1.1 TiDB 侧 SQL table 转为 Key-Value

在 TiDB 层,我们有以上关系型表,上面这一行数据最终会变成三对 key-value(详细原理 https://book.tidb.io/session1/chapter3/tidb-kv-to-relation.html ),分别对应:
- 主键对需要保证 key 唯一性:主键值 => 本行所有列数据
- 唯一索引按 key 有序排列加速查询速度:name 列:唯一索引 => 主键
- 非唯一索引按 key 有序排列提升查询性能:age 列:索引+主键 => 空值
1.2 TiKV 侧 MVCC 版本写入
在 TiKV 层,分布式事务接口在收到对应的 key-value 对后,会转成对应的 MVCC key-value 写入到 raftstore. 这里我们不展开分布式事务的具体实现逻辑,只用最简单的乐观锁模型( TiDB 最佳实践系列(三)乐观锁事务 - 知乎 )来举例。
Prewrite 接口完毕后:
其中锁 Lock CF(无版本号)如下:
- t{table-id}r1=> start_ts,primary_key,ttl,PUT
- t{table-id}i{indexID}_Bob=>start_ts,primary_key,ttl,PUT
- t{table-id}i{indexID}_12_1=>start_ts,primary_key,ttl,PUT
数据 Default CF(mvcc 版本号 start_ts 在 key 的后缀里)如下:
- t{table-id}r1_{start_ts}=> {Bob,12,99}
- t{table-id}i{indexID}Bob{start_ts}=>1
- t{table-id}i{indexID}_12_1{start_ts}=>null
具体实现中,会有一个优化,即当 value 值不是很大时,不会将数据单独放在 Default CF 里面(这里不展开具体介绍)。
Commit 接口调用完毕之后:
以主键对为例子,数据会发生如下变化:
Write CF 里面写入:
- t{table_id}{commit_ts}=>start_ts
Lock CF 中对应 key 被删除(注意这里是 rocksdb 的一次删除,rocksdb 底层 LSM 也是 mvcc, 即删除对 rocksdb 也是写入一个新版本):
- t{table-id}r1=> start_ts,primary_key,ttl,PUT
综上,我们 以 主键所在 key 为例 ,展开 讲讲这个 key 随着增删改 mvcc 版本的变迁。
transaction 1: insert set id=1

transaction 2: update where id=1
update 之后,在 raftstore 里面留下的 mvcc 信息如下:

也就是说,update 并没有直接去更新上一次写入的内容,而是重新写了一份数据到底层。
transaction 3: delete id=1
那如果我们 delete id=1 的这一行数据呢?从下面我们可以看到,delete 也是通过写入一个新版本到底层。

综上,当我们对 id=1 依次做了 insert/update/delete 之后,对于 TiDB 客户端来说,这一行数据已经删除,但是对于存储底层来说,此时在 raftstore 层留下了以下多个 mvcc 版本。

可以看到,同一行数据会随着增删改的次数,积累越来越多的版本,这里历史的 mvcc 版本如果不及时清理,不光物理磁盘空间无法释放,更会对读写产生性能影响,所以我们需要 GC 来对这些旧版本数据进行回收。
TiDB 版本堆积常见排查手段
如前文所说,当 MVCC 版本出现堆积时,会对读写造成性能影响,此时,我们就需要对 GC 参数及状态进行判断,加速旧版本数据的回收,提升集群读写性能。
那么,在实际的业务场景中,如何判断我们的 MVCC 数据版本是否出现堆积,并对当前集群读写性能造成了影响呢?
2.1 Slow log 视角(具体慢 SQL 视角)
如前文所说,MVCC 版本堆积最直接的影响是读写变慢,所以我们从 slow log( https://docs-archive.pingcap.com/zh/tidb/v7.2/identify-slow-queries ) 可以来排查 SQL 执行慢的原因是否是 mvcc 历史版本是否堆积过多。
tidb slow log: scan_detail: {total_process_keys: 1139428, total_process_keys_size: 433849330, total_keys: 1139434, rocksdb: {delete_skipped_count: 0, key_skipped_count: 2278852,....上面摘取的一段日志是 slow log 里面,与 TiDB mvcc 版本数量有关的几个字段:
- total_process_keys: 本次查询扫描的有用的用户 key 个数。不包含已删除的版本及 rocksdb 里面 tombstone 的版本
- total_keys :本次查询总共扫的 mvcc 版本个数
当 total_keys > total_process_keys*6 时,代表着查询范围内的平均每个 key 的 mvcc 版本是 6 以上,需要注意 GC 的相关参数是否合理,检查 GC 的状态是否正常。
Rocksdb 相关指标 (rocksdb 里面的 mvcc):
- delete_skipped_count: rocksdb 里面被标记为删除的 key. 当这个值比较大时,意味着 rocksdb 需要做 compaction 了
- key_skipped_count( https://github.com/facebook/rocksdb/blob/9f1c84ca471d8b1ad7be9f3eebfc2c7e07dfd7a7/include/rocksdb/perf_context.h#L84 ): 实际读取过程中,rocksdb 读取迭代器中执行 next 的个数,代表着实际数据的读取量
下面我们举个例子来加深理解 slow log 里面的这些字段。(注意后续所有的例子 SQL 中,查询语句需要加上“explain analyze( https://docs.pingcap.com/tidb/stable/sql-statement-explain-analyze )” 才能看到具体的 mvcc 扫描详情)
Step 1:创建表结构

- total_process_keys 是 0,因为它是一张空表。
- total_keys =1 因为我们在查询之前并不知道这张表是否为空,需要拿出符合条件的第一个 MVCC 版本才能确认这条 mvcc 不是本表数据。
Step 2:插入一条 ID=1 的新数据

可以看到,插入完成后再查询时:
- total_process_keys =1, 表中当前一共有一行数据(id=1)
- total_keys =2, 扫完 id=1 的 key 后,还要往后扫一个 key 才能确认此表中已经没有数据
Step 3:更新 ID=1 的这行数据

更新完后再查询时:
- total_process_keys =1 因为确实这张表中只有一行数据
- total_keys = 3, 因为 id=1 这行数据有两个版本, 也就是本次更新增加了一个版本
Step 4:删除 ID=1 所在行

删除后执行查询时:
- total_process_keys =0:删除了 id=1 这行数据后,表里面没有数据了
- total_keys = 3+1:而删除 id=1 给这行数据增加了一个版本,所以 total_keys 比上一次多了 1 个
Step 5:插入一条 ID=2 的新数据

请尝试自行分析。
2.2 Grafana (集群)视角
因为 slow log 默认只记录 300 ms 以上的 SQL 读取细节,怎么看整个集群 mvcc 读取状态呢?这就需要我们从 grafana 级别来宏观分析了。
分布式事务 mvcc
监控地址:tikv-details->coprocessor-details-> Total Ops Details(TableScan/IndexScan)

如图所说:
Ops 具体分两种:
- Table scan:代表着按 table 主键查询
- Index scan:代表着按索引查询
具体监控值分两类:
- processed_keys:代表查询后实际用户可见的 key 个数,与 slow-log 中的 total_processed_keys 概念一致
- next/seek/..:代表本次查询在 TiKV 迭代器中每个指令的调用次数,一般 next 居多。所有指令总调用次数接近于 slow log 里面 total_keys
同样的,如果从上图中看到 processed_keys 所在的线如果远远小于 next, 则说明 mvcc 版本冗余对当前的读取已经构成性能影响。
Rocksdb 层看 MVCC
tikv-details->coprocessor->total rocksdb perf statistics:

这里 delete_skipped 主要是指 rocksdb 里面的 tombstone, 对应于 slow log 里面的 delete_skipped_count。
2.3 Region 视角(热点更新表视角)
在实际业务中,我们往往对某些 table 或者 table 中的某些行更新比较频繁,从集群角度看,就只有这些 table 涉及到的 region 的数据版本堆积比较严重。
同时 TiDB 在设计时,要求同一个 key 所在的所有 mvcc 版本数据只能落在一个 region 里面,所以如果 TiDB 中某一行数据更新过于频繁,会导致版本堆积过多而出现大 region 的情况(大于 1 G)。那么在遇到大 region 时,我们如何判断是否出现了这种情况呢?
tikv-ctl( https://docs.pingcap.com/tidb/stable/tikv-control#print-some-properties-about-region )工具提供了命令来查看具体 region 内 mvcc 数据的分布:
tiup ctl:v6.5.0 tikv --host 127.0.0.1:20160 region-properties -r 6493
Starting component `ctl`: /home/tidb/.tiup/components/ctl/v6.5.0/ctl tikv --host 127.0.0.1:20160 region-properties -r 6493
mvcc.min_ts: 442383585748713474
mvcc.max_ts: 442383589195644931
mvcc.num_rows: 410870
mvcc.num_puts: 410870
mvcc.num_deletes: 0
mvcc.num_versions: 410870
mvcc.max_row_versions: 1
writecf.num_entries: 410870
writecf.num_deletes: 0
writecf.num_files: 1
writecf.sst_files: 053983.sst
defaultcf.num_entries: 0
defaultcf.num_files: 0
defaultcf.sst_files:
region.start_key: 7480000000000000ffe75f728000000000ff3f028e0000000000fa
region.end_key: 7480000000000000ffe75f728000000000ff454f410000000000fa
region.middle_key_by_approximate_size: 7480000000000000ffe75f728000000000ff42250e0000000000faf9dc567895dbfffe其中我们重点关注 mvcc 为前缀的为 mvcc 相关数据:文章来源:https://www.toymoban.com/news/detail-846487.html
- mvcc.min_ts:这个 region 里面的所有版本中最小(最老)的 tso
- mvcc.min_ts:本 region 数据中最新的 mvcc 版本 的 tso
- mvcc.num_rows:用户可见的 key 个数(包含已删除的)= mvcc.num_put+mvcc.num_delete
- mvcc.num_put:用户可见的 key 个数(不包含已删除的)
- mvcc.num_delete:用户可见的已删除的 key 数
- mvcc.num_version:用户可见的 mvcc 版本个数
- mvcc.max_row_versions:本 region 中版本数最多的那个 key 拥有的版本数量
Rocksdb 的相关指标不详细展开,只需要关注到 *cf.num_deletes 比较高时,可以通过 手动 compaction ( https://docs.pingcap.com/tidb/stable/tikv-control#compact-data-of-each-tikv-manually )指定 CF 来解决。文章来源地址https://www.toymoban.com/news/detail-846487.html
到了这里,关于TiDB MVCC 版本堆积相关原理及排查手段的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!