📝个人主页:五敷有你
🔥系列专栏:算法分析与设计
⛺️稳中求进,晒太阳

算法具体介绍
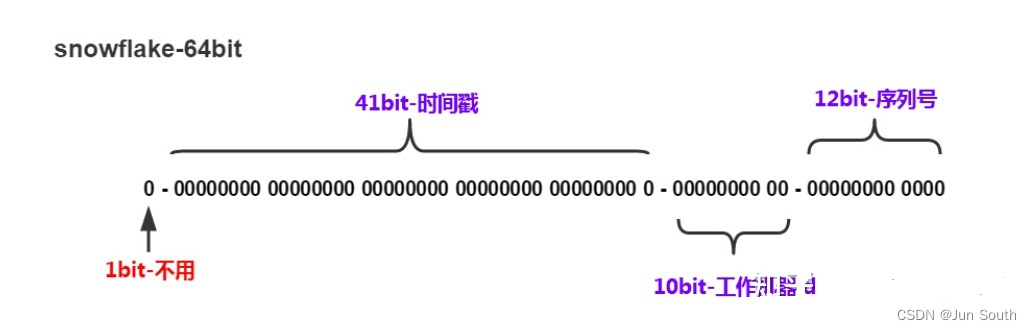
雪花算法是 64 位 的二进制,一共包含了四部分:
- 1位是符号位,也就是最高位,始终是0,没有任何意义,因为要是唯一计算机二进制补码中就是负数,0才是正数。
- 41位是时间戳,具体到毫秒,41位的二进制可以使用69年,因为时间理论上永恒递增,所以根据这个排序是可以的。
- 10位是机器标识,可以全部用作机器ID,也可以用来标识机房ID + 机器ID,10位最多可以表示1024台机器。
- 12位是计数序列号,也就是同一台机器上同一时间,理论上还可以同时生成不同的ID,12位的序列号能够区分出4096个ID。

优化
由于41位是时间戳,我们的时间计算是从1970年开始的,只能使用69年,为了不浪费,其实我们可以用时间的相对值,也就是以项目开始的时间为基准时间,往后可以使用69年。获取唯一ID的服务,对处理速度要求比较高,所以我们全部使用位运算以及位移操作,获取当前时间可以使用System.currentTimeMillis()。
时间回拨问题
在获取时间的时候,可能会出现时间回拨的问题,什么是时间回拨问题呢?就是服务器上的时间突然倒退到之前的时间。
- 人为原因,把系统环境的时间改了。
- 有时候不同的机器上需要同步时间,可能不同机器之间存在误差,那么可能会出现时间回拨问题。
解决方案文章来源:https://www.toymoban.com/news/detail-846493.html
- 回拨时间小的时候,不生成 ID,循环等待到时间点到达。
- 上面的方案只适合时钟回拨较小的,如果间隔过大,阻塞等待,肯定是不可取的,因此要么超过一定大小的回拨直接报错,拒绝服务,或者有一种方案是利用拓展位,回拨之后在拓展位上加1就可以了,这样ID依然可以保持唯一。但是这个要求我们提前预留出位数,要么从机器id中,要么从序列号中,腾出一定的位,在时间回拨的时候,这个位置
+1。
由于时间回拨导致的生产重复的ID的问题,其实百度和美团都有自己的解决方案了,有兴趣可以去看看,下面不是它们官网文档的信息:文章来源地址https://www.toymoban.com/news/detail-846493.html
- 百度UIDGenerator:https://github.com/baidu/uid-generator/blob/master/README.zh_cn.md
- UidGenerator是Java实现的, 基于Snowflake算法的唯一ID生成器。UidGenerator以组件形式工作在应用项目中, 支持自定义workerId位数和初始化策略, 从而适用于docker等虚拟化环境下实例自动重启、漂移等场景。 在实现上, UidGenerator通过借用未来时间来解决sequence天然存在的并发限制; 采用RingBuffer来缓存已生成的UID, 并行化UID的生产和消费, 同时对CacheLine补齐,避免了由RingBuffer带来的硬件级「伪共享」问题. 最终单机QPS可达600万。
- 美团Leaf:https://tech.meituan.com/2019/03/07/open-source-project-leaf.html
- leaf-segment 方案
- 优化:双buffer + 预分配
- 容灾:Mysql DB 一主两从,异地机房,半同步方式
- 缺点:如果用segment号段式方案:id是递增,可计算的,不适用于订单ID生成场景,比如竞对在两天中午12点分别下单,通过订单id号相减就能大致计算出公司一天的订单量,这个是不能忍受的。
- leaf-segment 方案
-
- leaf-snowflake方案
- 使用Zookeeper持久顺序节点的特性自动对snowflake节点配置workerID
- 1.启动Leaf-snowflake服务,连接Zookeeper,在leaf_forever父节点下检查自己是否已经注册过(是否有该顺序子节点)。
- 2.如果有注册过直接取回自己的workerID(zk顺序节点生成的int类型ID号),启动服务。
- 3.如果没有注册过,就在该父节点下面创建一个持久顺序节点,创建成功后取回顺序号当做自己的workerID号,启动服务。
- 使用Zookeeper持久顺序节点的特性自动对snowflake节点配置workerID
-
- 缓存workerID,减少第三方组件的依赖
- 由于强依赖时钟,对时间的要求比较敏感,在机器工作时NTP同步也会造成秒级别的回退,建议可以直接关闭NTP同步。要么在时钟回拨的时候直接不提供服务直接返回ERROR_CODE,等时钟追上即可。或者做一层重试,然后上报报警系统,更或者是发现有时钟回拨之后自动摘除本身节点并报警
- leaf-snowflake方案
到了这里,关于分布式唯一ID 雪花算法的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!