1. 概述
分布式系统中,有一些需要使用全局唯一ID的场景,这种时候为了防止ID冲突可以使用36位的UUID,但是UUID有一些缺点,首先他相对比较长,另外UUID一般是无序的。有些时候我们希望能使用一种简单一些的ID,并且希望ID能够按照时间有序生成。而Twitter的snowflake解决了这种需求,最初Twitter把存储系统从MySQL迁移到Cassandra,因为Cassandra没有顺序ID生成机制,所以开发了这样一套全局唯一ID生成服务。
该项目地址为:https://github.com/twitter/snowflake 是用 Scala实现的
参考:
-
C# 分布式自增ID算法snowflake(雪花算法) - 五维思考 - 博客园 (cnblogs.com)
-
C#雪花Id_c# 雪花id-CSDN博客
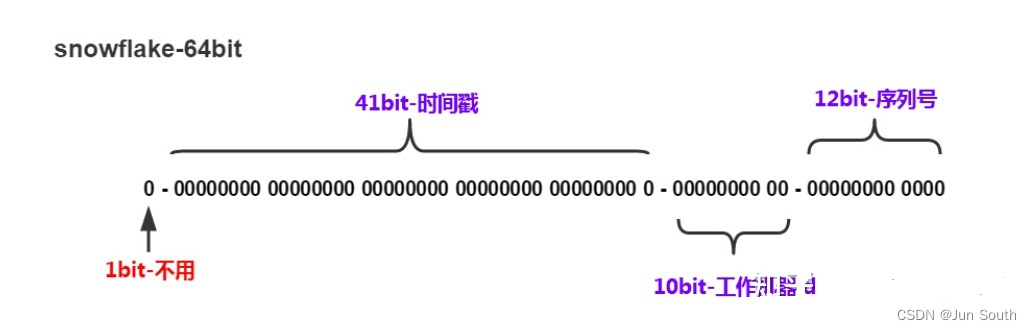
2. 结构
| 第1位 | 第2位 | 第3位 | 第4位 | 第5位 |
|---|---|---|---|---|
| 位数 | 时间戳(ms) | 数据中心ID(DatacenterId ) | 工作节点ID (MachineId ) | 自增序列号 |
| 0 | 0000000000 | 0000000000 | 0000000000 | 000000000000 |
- 第1位:未使用
- 第2位:接下来的41位为毫秒级时间(41位的长度可以使用69年),用毫秒级的时间戳来表示自1970年1月1日 00:00:00 GMT以来的时间。
- 第3-4位:用来区分不同的数据中心
datacenterId和machineId,可根据实际情况分配,最多可容纳1024个数据中心(2^10=10位的长度最多支持部署1024个节点),也可以设置成5位,最大节点是32个。 - 最后12位是毫秒内的计数(12位的计数顺序号支持每个节点每毫秒产生4096个
ID序号)
一共加起来刚好64位,为一个Long型。(转换成字符串长度为18)
snowflake生成的ID整体上按照时间自增排序,并且 整个分布式 系统内不会产生ID碰撞(由datacenter和machineId作区分),并且效率较高。据说:snowflake每秒能够产生26万个ID。
注意:
- 在实际使用中,需要根据不同的分布式环境配置合适的数据中心ID和工作节点ID,以保证生成的雪花Id的唯一性和顺序性。
- 其中
dataCenterId和workerId分别是数据中心和工作节点的标识,该生成器依赖于数据中心ID和工作节点ID两个参数进行初始化。具体的生成过程是根据当前时间戳、数据中心ID、工作节点ID和自增序列号,通过位运算组合生成一个64位的唯一标识。
3. 代码
3.1 IdWorker.cs
using System;
/// <summary>
/// Twitter的分布式自增ID雪花算法
/// </summary>
public class IdWorker
{
//起始的时间戳
private static long START_STMP = 1480166465631L;
//每一部分占用的位数
private static int SEQUENCE_BIT = 12; //序列号占用的位数
private static int MACHINE_BIT = 5; //机器标识占用的位数
private static int DATACENTER_BIT = 5;//数据中心占用的位数
//每一部分的最大值
private static long MAX_DATACENTER_NUM = -1L ^ (-1L << DATACENTER_BIT);
private static long MAX_MACHINE_NUM = -1L ^ (-1L << MACHINE_BIT);
private static long MAX_SEQUENCE = -1L ^ (-1L << SEQUENCE_BIT);
//每一部分向左的位移
private static int MACHINE_LEFT = SEQUENCE_BIT;
private static int DATACENTER_LEFT = SEQUENCE_BIT + MACHINE_BIT;
private static int TIMESTMP_LEFT = DATACENTER_LEFT + DATACENTER_BIT;
private long datacenterId = 1; //数据中心
private long machineId = 1; //机器标识
private long sequence = 0L; //序列号
private long lastStmp = -1L;//上一次时间戳
#region 单例:完全懒汉
private static readonly Lazy<IdWorker> lazy = new Lazy<IdWorker>(() => new IdWorker());
public static IdWorker Singleton { get { return lazy.Value; } }
private IdWorker() { }
#endregion
public IdWorker(long cid, long mid)
{
if (cid > MAX_DATACENTER_NUM || cid < 0) throw new Exception($"中心Id应在(0,{MAX_DATACENTER_NUM})之间");
if (mid > MAX_MACHINE_NUM || mid < 0) throw new Exception($"机器Id应在(0,{MAX_MACHINE_NUM})之间");
datacenterId = cid;
machineId = mid;
}
/// <summary>
/// 产生下一个ID
/// </summary>
/// <returns></returns>
public long nextId()
{
long currStmp = getNewstmp();
if (currStmp < lastStmp) throw new Exception("时钟倒退,Id生成失败!");
if (currStmp == lastStmp)
{
//相同毫秒内,序列号自增
sequence = (sequence + 1) & MAX_SEQUENCE;
//同一毫秒的序列数已经达到最大
if (sequence == 0L) currStmp = getNextMill();
}
else
{
//不同毫秒内,序列号置为0
sequence = 0L;
}
lastStmp = currStmp;
return (currStmp - START_STMP) << TIMESTMP_LEFT //时间戳部分
| datacenterId << DATACENTER_LEFT //数据中心部分
| machineId << MACHINE_LEFT //机器标识部分
| sequence; //序列号部分
}
private long getNextMill()
{
long mill = getNewstmp();
while (mill <= lastStmp)
{
mill = getNewstmp();
}
return mill;
}
private long getNewstmp()
{
return (long)(DateTime.UtcNow - new DateTime(1970, 1, 1, 0, 0, 0, DateTimeKind.Utc)).TotalMilliseconds;
}
}
3.2 IdWorkerTest.cs (测试)
使用
IdWorker idworker = IdWorker.Singleton;
Console.WriteLine(idworker.nextId());
测试文章来源:https://www.toymoban.com/news/detail-846552.html
using System;
using System.Collections.Generic;
using System.Linq;
using System.Runtime.InteropServices;
using System.Text;
using System.Threading.Tasks;
namespace Test.Simple
{
public static class IdWorkerTest
{
public static void Test()
{
/***
*
* 两种测试方法,均为500并发,生成5000个Id:
* Machine1() 模拟1台主机,单例模式获取实例
* Machine5() 模拟5台主机,创建5个实例
*/
Machine1();
Machine2();
Machine5();
}
public static void Machine1()
{
int cid = 1;
int mid = 15;
Console.WriteLine("雪花ID -- IdWorkerTest -- 模拟1台主机( 数据中心{0} - 机器节点{1}): ", cid, mid);
IdWorker idworker = new IdWorker(cid, mid);
Console.WriteLine(idworker.nextId());
cid = 2;
mid = 10;
Console.WriteLine("雪花ID -- IdWorkerTest -- 模拟1台主机( 数据中心{0} - 机器节点{1}): ", cid, mid);
idworker = new IdWorker(cid, mid);
Console.WriteLine(idworker.nextId());
}
public static void Machine2()
{
Console.WriteLine("雪花ID -- IdWorkerTest -- 模拟1台主机 : ");
for (int j = 0; j < 500; j++)
{
Task.Run(() =>
{
IdWorker idworker = IdWorker.Singleton;
for (int i = 0; i < 10; i++)
{
Console.WriteLine(idworker.nextId());
}
});
}
}
public static void Machine5()
{
Console.WriteLine("雪花ID -- IdWorkerTest -- 模拟5台主机 : ");
List<IdWorker> workers = new List<IdWorker>();
Random random = new Random();
for (int i = 0; i < 5; i++)
{
workers.Add(new IdWorker(1, i + 1));
}
for (int j = 0; j < 500; j++)
{
Task.Run(() =>
{
for (int i = 0; i < 10; i++)
{
int mid = random.Next(0, 5);
Console.WriteLine(workers[mid].nextId());
}
});
}
}
}
}
在这里插入图片描述

结束文章来源地址https://www.toymoban.com/news/detail-846552.html
到了这里,关于C# 分布式自增ID算法snowflake(雪花算法)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!