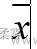平均值在计量专业和统计学中有着广泛的应用如:描述数据集中趋势、比较不同组数据、评估数据的代表性、决策和判断、回归分析概率统计与财务分析等。此外,在计量专业中,平均值还被广泛应用于各种测量和校准过程中,以确保测量结果的准确性和可靠性。例如,在实验室测量中,多次测量的平均值可以提高测量的精度;在质量控制中,通过计算产品的平均质量水平来评估生产过程的稳定性等。
算数平均数(Mean):
算术平均值为所有数值相加后除以数值的个数,它反映了数据的一般水平。其中,简单平均数(算术平均数)是把所有数值相加,然后用总数除以数值的个数。这种方法假设每个数值具有相同的权重或重要性。简单平均数是反映一组数据的一般水平的重要指标,它利用了所有数据的信息,并且在数学上是使误差平方和达到最小的统计量。
x
ˉ
=
x
1
+
x
2
+
x
3
+
.
.
.
+
x
n
n
=
Σ
i
=
1
n
x
i
n
\bar{x}=\frac{x_{1}+x_{2}+x_{3}+...+x_{n}}{n}=\frac{\Sigma^{n}_{i=1}x_{i}}{n}
xˉ=nx1+x2+x3+...+xn=nΣi=1nxi 衍生公式(如计算方差时用到):
V
a
r
i
a
n
c
e
=
1
n
∑
i
=
1
n
(
x
i
−
A
M
)
2
Variance = \frac{1}{n} \sum_{i=1}^{n} (x_i - AM)^2
Variance=n1∑i=1n(xi−AM)2
A
M
=
1
n
∑
i
=
1
n
x
i
AM = \frac{1}{n} \sum_{i=1}^{n} x_i
AM=n1∑i=1nxi,其中 :
*
n
n
n :数据的数量
*
x
i
x_i
xi :每个数据点。
建立样品数据:
name <- c("大天二", "陈浩南", "刘亦菲", "山鸡", "蕉皮", "洪满天",
"刘华强", "马大脚", "奥利给", "大金刚", "马里奥", "GGBond",
"菲菲", "刘老二")
gender <- c("男", "女", "男", "女", "女", "男", "男", "女",
"男", "男", "女", "女", "男", "女")
stat <- c(11, 12, 15, 85, 76, 45, 78, 99, 64, 10, 73, 74, 82, 72)
math <- c(44, 67, 82, 91, 45, 23, 1, 98, 23, 45, 24, 30, 75, 69)
econ <- c(99, 85, 79, 68, 49, 79, 88, 92, 93, 94, 89, 84, 46, 77)
student_data <- data.frame(姓名=name, 性别=gender, 统计学=stat,数学=math, 经济学=econ)
print(student_data)

计算统计学的平均分数:
simple_mean <- mean(student_data$统计学)
print(simple_mean)
# 输出: 56.85714
平均值在以下情况下可以作为最佳估约值:
- 数据分布均匀:当数据集中的数值分布相对均匀,没有明显的极端值时,平均值能够较好地代表整体数据的中心趋势。
- 大样本量:当样本量足够大时,平均值受个别极端值的影响会相对较小,因此更能准确地反映数据的整体情况。
- 对称分布:对于对称分布的数据集(如正态分布),平均值是描述数据中心位置的最佳选择。
但需要注意的是,在数据存在极端值或分布严重偏斜的情况下,平均值可能不是最佳的估约值(比如存在系统误差)。在这种情况下,中位数或众数可能更能代表数据的中心趋势。因此,在选择使用平均值作为估约值时,需要综合考虑数据的分布特点和具体应用场景。
加权算数平均值
在计算平均数时,给每个数据赋予一个权重,以反映数据的重要性。每个数据与其对应的权重相乘,然后将所得的乘积求和,再除以所有权重的总和。加权平均数能够更准确地反映数据的实际重要性,特别是在数据点的重要性或频率不均匀分布的情况下。
x
ˉ
=
m
1
f
1
+
m
2
f
2
+
m
3
f
3
+
.
.
.
+
m
k
f
k
f
1
+
f
2
+
f
3
+
.
.
.
+
f
k
=
Σ
i
=
1
k
m
i
f
i
n
\bar{x}=\frac{m_{1}f_{1}+m_{2}f_{2}+m_{3}f_{3}+...+m_{k}f_{k}}{f_{1}+f_{2}+f_{3}+...+f_{k}}=\frac{\Sigma_{i=1}^{k}m_{i}f_{i}}{n}
xˉ=f1+f2+f3+...+fkm1f1+m2f2+m3f3+...+mkfk=nΣi=1kmifi *
x
ˉ
\bar{x}
xˉ:表示加权平均值。
* m i m_i mi:表示第 i i i个测量值或数据点。
* f i f_i fi:表示与第 i i i个测量值相关联的权重(或称为频数)。
* k k k:表示测量值的数量。
* n n n:表示所有权重的总和,即 n = f 1 + f 2 + f 3 + . . . + f k n = f_1 + f_2 + f_3 + ... + f_k n=f1+f2+f3+...+fk。
* Σ i = 1 k \Sigma_{i=1}^{k} Σi=1k:表示从 i = 1 i=1 i=1到 i = k i=k i=k的求和符号。
* m 1 f 1 + m 2 f 2 + m 3 f 3 + . . . + m k f k m_{1}f_{1} + m_{2}f_{2} + m_{3}f_{3} + ... + m_{k}f_{k} m1f1+m2f2+m3f3+...+mkfk:这部分是测量值与对应权重的乘积之和。它表示了每个测量值根据其权重对总和的贡献。
* f 1 + f 2 + f 3 + . . . + f k f_{1} + f_{2} + f_{3} + ... + f_{k} f1+f2+f3+...+fk:这是所有权重的总和,也称为 n n n。它用于标准化上述乘积之和,以确保加权平均值在合理的范围内。
因此,加权平均值 x ˉ \bar{x} xˉ是测量值与权重乘积之和除以权重之和。这反映了每个测量值根据其权重对平均值的贡献。
在计量专业中加权算数平均值的计算公式为:
x w = Σ i = 1 m W i x i Σ i = 1 m W i = Σ i = 1 m W i Σ i = 1 m W i x i = Σ i = 1 m w i x i x_{w}=\frac{\Sigma^{m}_{i=1}W_{i}x_{i}}{\Sigma_{i=1}^{m}W_{i}}=\Sigma_{i=1}^{m}\frac{W_{i}}{\Sigma_{i=1}^{m}W_{i}}x_{i}=\Sigma^{m}_{i=1}w_{i}x_{i} xw=Σi=1mWiΣi=1mWixi=Σi=1mΣi=1mWiWixi=Σi=1mwixi * x w x_{w} xw:加权算数平均值
* W i W_{i} Wi:第 i i i次测量结果的权
* x i x_{i} xi:第i次的测量结果
* m m m:测量次数
* w i w_{i} wi:归一化的权,即 Σ i m w i = 1 \Sigma^{m}_{i}w_{i}=1 Σimwi=1
在计算 x w x_{w} xw时,各测量结果 x i x_{i} xi所占的比重,用权 W i W_{i} Wi表示。 W i W_{i} Wi越大, x i x_{i} xi越可信赖,则加权平均计算中 x i x_{i} xi的权应该相应的越大。由于最终对加权算术平值起作用的归一化的权 w i w_{i} wi,所以,对于一组权( W 1 , W 2 , . . . , W n , W_{1},W_{2},...,W_{n}, W1,W2,...,Wn,),每个 W i W_{i} Wi都放大或缩小同样倍数,并不影响加权平均中的实际权重。 假设几个实验室分别对同一被测量在相同环境等测量条件下的测得值为 x i x_{i} xi,其标准不确定度为 u i u_{i} ui,且评定数值合理;各实验室均为独立测量;而且这组独立测量数据之间是兼容的;此时,权的计算公式为: W i = 1 u i 2 W_{i}=\frac{1}{u^{2}_{i}} Wi=ui21 即加权平均的权与每个参与计算的测量值的试验标准偏差的二次方成反比。 假设有三个实验室对同一被测量进行了独立测量,测得的数值和标准不确定度如下:
实验室1:测得值 (
x
1
x_{1}
x1 = 10.5 ),标准不确定度 (
u
1
u_{1}
u1 = 0.5 )
实验室2:测得值 (
x
2
x_{2}
x2 = 10.2 ),标准不确定度 (
u
2
u_{2}
u2 = 0.3 )
实验室3:测得值 (
x
3
x_{3}
x3 = 10.7 ),标准不确定度 (
u
3
u_{3}
u3 = 0.4 )
我们要计算这组测量值的加权算术平均值
W
i
=
1
u
i
2
W_{i} = \frac{1}{u_{i}^{2}}
Wi=ui21 来计算每个测量结果的权:
实验室1的权
W
1
=
1
0.
5
2
=
4
W_{1} = \frac{1}{0.5^{2}} = 4
W1=0.521=4
实验室2的权
W
2
=
1
0.
3
2
≈
11.1111
W_{2} = \frac{1}{0.3^{2}} \approx 11.1111
W2=0.321≈11.1111
实验室3的权
W
3
=
1
0.
4
2
=
6.25
W_{3} = \frac{1}{0.4^{2}} = 6.25
W3=0.421=6.25
接下来计算归一化的权
w
i
w_{i}
wi:
总权
Σ
W
i
=
4
+
11.1111
+
6.25
=
21.3611
\Sigma W_{i} = 4 + 11.1111 + 6.25 = 21.3611
ΣWi=4+11.1111+6.25=21.3611
实验室1的归一化权
w
1
=
4
21.3611
≈
0.1872
w_{1} = \frac{4}{21.3611} \approx 0.1872
w1=21.36114≈0.1872
实验室2的归一化权
w
2
=
11.1111
21.3611
≈
0.5202
w_{2} = \frac{11.1111}{21.3611}\approx 0.5202
w2=21.361111.1111≈0.5202
实验室3的归一化权
w
3
=
6.25
21.3611
≈
0.2926
w_{3} = \frac{6.25}{21.3611} \approx 0.2926
w3=21.36116.25≈0.2926
最后,我们根据加权算术平均值的公式计算 (
x
w
x_{w}
xw ):
1.
x
w
=
Σ
i
=
1
m
w
∗
i
x
i
=
w
1
x
1
+
w
2
x
2
+
w
3
x
3
x_{w} = \Sigma_{i=1}^{m} w*{i} x_{i} = w_{1} x_{1} + w_{2} x_{2} + w_{3} x_{3}
xw=Σi=1mw∗ixi=w1x1+w2x2+w3x3)
2.
x
w
∗
≈
0.187210.5
+
0.5202
∗
10.2
+
0.2926
∗
10.7
x_{w}* \approx 0.1872 10.5 + 0.5202 *10.2 + 0.2926* 10.7
xw∗≈0.187210.5+0.5202∗10.2+0.2926∗10.7)
3.
x
w
≈
10.3978
x_{w} \approx 10.3978
xw≈10.3978
所以,这组测量值的加权算术平均值约为 10.3978。
# 定义测量值和标准不确定度
x <- c(10.5, 10.2, 10.7)
u <- c(0.5, 0.3, 0.4)
# 计算权值
W <- 1 / (u^2)
# 计算归一化权值
w <- W / sum(W)
# 计算加权算术平均值
x_w <- sum(w * x)
print(x_w) # 输出加权算术平均值
# 输出: 10.40247
公式变形:
x
ˉ
=
Σ
i
=
1
k
m
i
f
i
n
\bar{x} = \frac{\Sigma_{i=1}^{k}m_{i}f_{i}}{n}
xˉ=nΣi=1kmifi,其中:
*
Σ
i
=
1
k
m
i
f
i
\Sigma_{i=1}^{k}m_{i}f_{i}
Σi=1kmifi表示所有
m
i
m_i
mi和
f
i
f_i
fi乘积的和
*
n
n
n是所有权重的总和。
这种表示方法更为简洁,且更通用。
计算完实验室数据后继续上述代码,计算学生成绩表的加权平均数,以经济学成绩作为权重
weighted_mean_stat <- weighted.mean(student_data$统计学, student_data$经济学)
print(weighted_mean_stat)
# 输出:54.58645
计算每个科目的简单平均数和加权平均数
# 初始化一个数据框来存储结果
results <- data.frame(Subject=character(), SimpleMean=numeric(), WeightedMean=numeric())
subjects <- c("统计学", "数学", "经济学")
for (subject in subjects) {
simple_mean <- mean(student_data[[subject]])
weighted_mean <- weighted.mean(student_data[[subject]], student_data$经济学)
results <- rbind(results, data.frame(Subject=subject, SimpleMean=simple_mean, WeightedMean=weighted_mean))
}
print(results)

使用ggplot2绘制气泡图
library(ggplot2)
student_data$性别 <- as.factor(student_data$性别)
ggplot(student_data, aes(x = 统计学, y = 数学, color = 性别, size = 经济学)) +
geom_point(alpha = 0.7) + # alpha用于设置点的透明度
scale_size(range = c(1, 10)) + # 设置气泡的最小和最大尺寸
theme_minimal() + # 使用简洁的主题
ggtitle("学生成绩气泡图") + # 设置图表标题
xlab("统计学成绩") + # 设置x轴标签
ylab("数学成绩") + # 设置y轴标签
guides(size = guide_legend(title = "经济学成绩"))

几何平均值(Geometric Mean):
计算公式:
G
M
=
(
∏
i
=
1
n
x
i
)
1
n
GM = (\prod_{i=1}^{n} x_i)^{\frac{1}{n}}
GM=(∏i=1nxi)n1,其中:文章来源:https://www.toymoban.com/news/detail-846572.html
- ∏ \prod ∏ :连乘
- * n n n :数据的数量
- *
x
i
x_i
xi :每个数据点。
几何平均值常用于计算平均增长率或复利等情况,在计量专业中使用几何平均值可以有效的消除系统误差。
在计量专业中最常见的就是等臂天平测量。
geometric_mean <- function(x) {
if(all(x > 0)) {
return(prod(x)^(1/length(x)))
} else {
stop("所有数值必须为正数")
}
}
values <- c(12.5, 12.2, 12.1, 12.3, 12.2)
geom_mean <- geometric_mean(values)
print(geom_mean)
# 输出: 12.25925
调和平均值(Harmonic Mean):
计算公式:
H
M
=
n
∑
i
=
1
n
1
x
i
HM = \frac{n}{\sum_{i=1}^{n} \frac{1}{x_i}}
HM=∑i=1nxi1n,其中:文章来源地址https://www.toymoban.com/news/detail-846572.html
- n n n :数据的数量
-
x
i
x_i
xi :每个数据点。
调和平均值常用于计算平均速率或成本等情况。
以下数据为一组气体流量计的实时流量记录:
harmonic_mean <- function(x) {
if(all(x > 0)) {
return(length(x) / sum(1/x))
} else {
stop("所有数值必须为正数")
}
}
values <- c(400.38, 400.41, 400.11, 400.35, 400.44, 400.19)
harm_mean <- harmonic_mean(values)
print(harm_mean)
# 输出: 400.3133
到了这里,关于R语言实现:统计学及计量专业中的多种平均值计算方式的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!