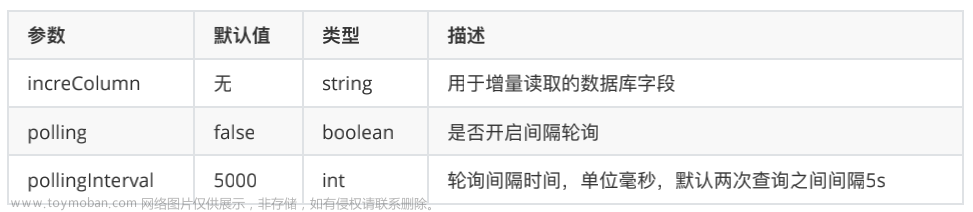
随着信息时代的蓬勃发展,企业对实时数据处理的需求逐渐成为推动业务创新和发展的重要驱动力。在这个快速变化的环境中,许多企业选择将 Oracle 数据库同步到 Kafka,以满足日益增长的实时数据处理需求。本文将深入探讨这一趋势的背后原因,并通过一个真实的客户案例来强调实时性在业务场景中的重要性。
为什么:理解 Oracle - Kafka 的实时同步需求
先来看一个典型的业务场景。实时库存管理需要迅速响应库存变化,以确保及时的补货和订单处理。通过将 Oracle 数据同步到 Kafka,可以实现实时捕获库存变更,并将这些变更事件传递给下游业务,如订单系统、报表系统等。如此一来,企业得以更加灵活、实时地管理库存,从而提高供应链效率。
为什么要同步至 Kafka?
再结合 Oracle 以及 Kafka 的自身特性,我们不难总结出 Oracle 到 Kafka 数据同步背后的实际需求,这通常涉及到满足实时数据需求、支持大规模数据处理、构建事件驱动体系结构以及提高整体系统性能等。以下是一些常见原因总结:
-
实时数据流:作为一个分布式消息队列系统,Kafka 能够提供高吞吐量和低延迟的实时数据处理。通过将 Oracle 数据库同步到 Kafka,可以实现对数据的实时捕获和处理,使得企业能够更快地响应数据变化。
-
高可用性:Kafka 通过分布式来实现高可用性,一个 Kafka 集群通常包含多个 Broker,每个 Broker 负责存储一部分的数据副本,这样即使某个 Broker 出现故障,其他 Broker 也可以继续工作,从而保证服务的可用性。
-
可扩展性:Kafka 基于其分布式架构、消费者组、分区和副本机制、水平扩展能力、高并发处理能力和容错性等方式实现了可扩展性,从而能够处理大规模的消息数据,满足高吞吐量和高并发的需求。
-
高效查询: Kafka 凭借顺序写入、索引、二分查找和内存缓存等技术,得以高效处理大规模的消息流,并保持高性能和低延迟,从而实现高效的数据读取。
-
高并发写入: Kafka 的设计理念注重高并发的数据写入,采用了多种技术,如零拷贝技术、批量处理、消息压缩、异步处理等,提高了数据传输的效率和处理的速度,能够处理大规模的数据流。充分利用 Kafka 的高并发写入能力,有助于业务系统处理大量的写入请求,适用于需要高吞吐量的业务,比如日志记录、事件溯源等。
-
解耦数据生产者和消费者:Kafka 的消息队列模型有助于解耦数据生产者和消费者之间的关系,可以使数据库的变更与实际数据使用者(应用程序、分析系统等)之间形成松耦合,从而提高整个系统的灵活性。
-
支持事件驱动架构:通过将 Oracle 数据同步到 Kafka,可以构建基于事件的架构。数据库的变更可以作为事件流式传输,触发系统中其他组件的动作,从而实现更灵活、敏捷的业务流程。
-
数据集成: Kafka 作为中间件,能够协调不同系统之间的数据流,可以轻松实现与其他数据源和目标的集成,促使系统更好地适应复杂的数据处理和交换需求。
为什么需要实时?
与此同时,数据同步的实时性在这个过程中被不断强调,还是举几个简单的例子:
-
实时报表和监控系统: 对于需要实时监控和报表展示的业务,如运营监控、性能监控等,及时获取数据库中的数据变更是关键。通过实时同步到 Kafka,保障这些监控系统的数据时刻处于最新状态。
-
事件驱动架构: 许多现代应用采用事件驱动架构,通过发布-订阅模型进行系统集成。在这种情况下,实时同步数据到 Kafka 是保证事件的及时传播和处理的关键。
-
用户体验: 在需要实时交互和响应的应用中,用户期望看到最新的数据状态。例如,在在线协作或实时通讯应用中,用户需要实时看到其他用户的操作和变更。
至此,我们已经大致了解了 Oracle 到 Kafka 数据实时同步的重要性,下面再来看一些常见的同步方案。
怎么做:数据同步方案对比
手动方案:配合开源工具
实现 Oracle 到 Kafka 数据实时同步的手动方案涉及多个步骤,包括设置 Oracle 数据库、配置 Kafka 环境,以及编写同步程序。下面是一个简单的手动方案示例,主要涉及使用 Debezium 开源工具实现 Oracle 数据库到 Kafka 的实时同步。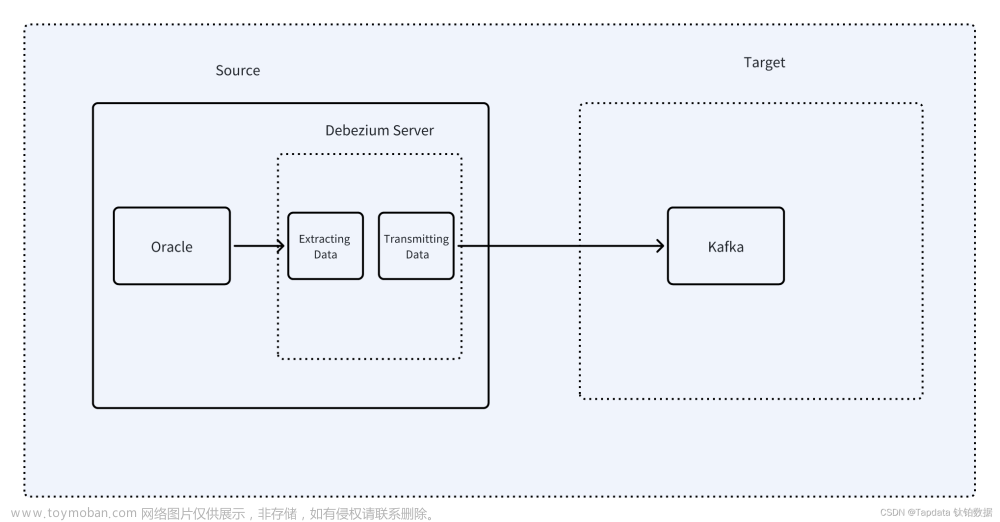
步骤一:准备工作
- 安装 Oracle 数据库: 确保已安装并正确配置 Oracle 数据库。
- 安装 Kafka: 安装 Kafka 并启动 ZooKeeper 服务,作为 Kafka 的依赖。
- 安装并配置 Debezium: Debezium 是一个开源的变更数据捕获工具,用于监听数据库变更并将其发送到 Kafka。下载并配置 Debezium Connector for Oracle。(https://debezium.io/)
步骤二:配置 Oracle 数据库
- 启用归档日志: 在 Oracle 数据库中,确保归档日志已启用,这是 Debezium 监听变更的必要条件。
sqlCopy code
ALTER SYSTEM SET LOG_ARCHIVE_DEST_1='LOCATION=/archivelog';
ALTER SYSTEM SET LOG_ARCHIVE_FORMAT='arch_%t_%s_%r.arc';
- 创建 CDC 用户: 创建一个专用于 Change Data Capture (CDC) 的用户,并授予必要的权限。
sqlCopy code
CREATE USER cdc_user IDENTIFIED BY cdc_password;
GRANT CONNECT, RESOURCE, CREATE VIEW TO cdc_user;
- 启用 CDC: 启用 Oracle 的 CDC 特性,并指定 CDC 用户。
sqlCopy code
EXEC DBMS_CDC_PUBLISH.CREATE_CHANGE_SET('MY_CHANGE_SET', 'CDC_USER');
EXEC DBMS_CDC_PUBLISH.ALTER_CHANGE_SET('MY_CHANGE_SET', 'ADD');
EXEC DBMS_CDC_PUBLISH.CREATE_CAPTURE('MY_CAPTURE', 'CDC_USER');
EXEC DBMS_CDC_PUBLISH.ALTER_CAPTURE('MY_CAPTURE', 'ADD');
EXEC DBMS_CDC_PUBLISH.CREATE_CHANGE_TABLE('MY_CHANGE_TABLE', 'CDC_USER', 'MY_CAPTURE', 'MY_CHANGE_SET');
步骤三:配置 Debezium 连接器
- 配置 Debezium Connector: 创建一个 JSON 配置文件,指定 Oracle 连接信息、监控的表等信息。
jsonCopy code
{"name": "oracle-connector", // 服务注册连接器时分配给连接器的名称。
"config": {"connector.class": "io.debezium.connector.oracle.OracleConnector", // Oracle连接器类的名称
"database.server.name": "my-oracle-server", //为连接器捕获更改的 Oracle 数据库服务器标识并提供命名空间的逻辑名称
"database.hostname": "your-oracle-host", //oracle实例地址
"database.port": "your-oracle-port", //oracle数据库端口
"database.user": "cdc_user", //oracle数据库用户
"database.password":"cdc_password", //oracle数据库密码
"database.dbname":"your-oracle-database",//要从中捕获更改的数据库的名称
"database.out.server.name":"oracle-server", // kafka主题
"table.include.list": "CDC_USER.MY_TABLE",//orcle中表进行数据监测输出数据
"schema.history.internal.kafka.bootstrap.servers": "192.3.65.195:9092",//此连接器用于将 DDL 语句写入和恢复到数据库历史主题的 Kafka 代理列表
"schema.history.internal.kafka.topic": "schema-changes.inventory" // 连接器写入和恢复 DDL 语句的数据库历史主题的名称
}
}
- 启动 Debezium Connector: 使用 Kafka Connect 启动 Debezium Connector。
bashCopy code
bin/connect-standalone.sh config/worker.properties config/debezium-connector-oracle.properties
步骤四:验证同步
- 插入数据: 在 Oracle 数据库中插入一些数据。
sqlCopy code
INSERT INTO CDC_USER.MY_TABLE (ID, NAME) VALUES (1, 'John Doe');
- 检查 Kafka 主题: 检查 Kafka 中是否有与表变更相关的消息。
bashCopy code
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic my-oracle-server.CDC_USER.MY_TABLE --from-beginning
此处应该能够看到与插入操作相关的 JSON 消息。
以上只是一个简单的示例,实际情况可能会更加复杂,具体的配置和操作可能取决于 Oracle 和 Debezium 版本的不同。在生产环境中,请务必遵循相关安全和最佳实践。
经典方案:配合 Oracle 官方工具 OGG
使用 Oracle GoldenGate (OGG) 实现 Oracle 到 Kafka 数据实时同步的方案同样包含多个步骤,以下是一个基本示例,以 OGG Classic Replicat 为例。请注意,具体配置仍然会因 Oracle GoldenGate 版本的不同而有所变化。
步骤一:准备工作
- 安装 Oracle GoldenGate: 安装并配置 Oracle GoldenGate 软件。
- 安装 Kafka: 安装 Kafka 并启动 ZooKeeper 服务,作为 Kafka 的依赖。
步骤二:配置 Oracle 数据库
- 启用归档日志: 确保 Oracle 数据库的归档日志已启用。
sqlCopy code
ALTER SYSTEM SET LOG_ARCHIVE_DEST_1='LOCATION=/archivelog';
ALTER SYSTEM SET LOG_ARCHIVE_FORMAT='arch_%t_%s_%r.arc';
步骤三:配置 OGG Extract 和 Pump
- 创建 OGG Extract: 配置 OGG Extract 用于捕获变更数据。
bashCopy code
cd $OGG_HOME
./ggsci
GGSCI> ADD EXTRACT ext1, TRANLOG, BEGIN NOW
GGSCI> ADD EXTTRAIL /trail/et, EXTRACT ext1
GGSCI> ADD EXTRACT dpump, EXTTRAILSOURCE /trail/et
GGSCI> ADD RMTTRAIL /trail/rt, EXTRACT dpump
- 配置 OGG Pump: 配置 OGG Pump 用于将捕获的变更数据传输到 Kafka。
bashCopy code
GGSCI> ADD EXTRACT pump1, EXTTRAILSOURCE /trail/rt, BEGIN NOW
GGSCI> ADD RMTTRAIL /trail/pt, EXTRACT pump1
GGSCI> ADD REPLICAT rep1, EXTTRAIL /trail/pt, SPECIALRUN
步骤四:配置 OGG Replicat 和 Kafka
- 编辑 OGG Replicat 参数文件: 编辑 Replicat 参数文件,配置连接信息和目标 Kafka 主题。
plaintextCopy code
REPLICAT rep1
USERID ogguser, PASSWORD oggpassword
ASSUMETARGETDEFS
MAP source_table, TARGET kafka_topic, COLMAP (...)
- 启动 OGG Replicat: 启动 Replicat 进程。
bashCopy code
./ggsci
GGSCI> START REPLICAT rep1
步骤五:验证同步
- 插入数据: 在 Oracle 数据库中插入一些数据。
sqlCopy code
INSERT INTO source_table (ID, NAME) VALUES (1, 'John Doe');
- 检查 Kafka 主题: 检查 Kafka 中是否有与表变更相关的消息。
bashCopy code
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic kafka_topic --from-beginning
新一代数据实时平台工具:低成本、更简单
以 Tapdata 为例,作为中国的 “Fivetran/Airbyte”, Tapdata 是一个以低延迟数据移动为核心优势构建的现代数据平台,内置 100+ 数据连接器,拥有稳定的实时采集和传输能力、秒级响应的数据实时计算能力、稳定易用的数据实时服务能力,以及低代码可视化操作等。典型用例包括数据库到数据库的复制、将数据引入数据仓库或数据湖,以及通用 ETL 处理等。
Tapdata 是一个专注于实时数据同步的工具,拥有强大且稳定的数据管道能力,可以用来替换类似于 OGG/DSG 这样的同步工具,将数据从 Oracle 、MySQL 这样的数据库同步到同构或者异构类型的数据目标。
以下是详细的操作教程(演示版本为 Tapdata Cloud):
步骤一:Tapdata 安装与部署
-
注册并登录 Tapdata Cloud
-
安装并部署 Tapdata: 访问 Tapdata 官方网站,获取操作指引,完成 Tapdata Agent 的安装与部署。
注册 Tapdata Cloud,即刻开启您的实时数据之旅
申请试用 Tapdata 本地部署版本
步骤二:配置数据源和目标
- 新建 Oracle 数据源:进入 Tapdata Cloud 连接管理页面,创建数据源 Oracle 的连接并测试通过。



- 新建数据目标 Kafka:重复上述操作,在数据源列表中找到 Kafka,参考连接配置帮助创建 Kafka 为数据目标的连接并测试通过:

步骤三:配置 Kafka
1.创建 Kafka Topic: 在 Kafka 中创建一个 Topic,用于接收从 Oracle 同步过来的数据。
bashCopy code
bin/kafka-topics.sh --create --topic my_oracle_topic --bootstrap-server localhost:9092 --partitions 1 --replication-factor 1
步骤四:开启同步任务
- 新建数据同步任务:通过拖拉拽的方式,在 Tapdata 的可视化操作界面中,连接数据源和目标,快速创建 Oracle - Kafka 的数据同步任务
- 启动同步任务: 点击源节点与目标节点,分别选择待同步表和目标表后即可启动任务,Tapdata 将开始捕获 Oracle 数据库的数据及变更,并将其发送到 Kafka。
步骤五:验证同步
- 插入数据: 在 Oracle 数据库中插入一些数据。
sqlCopy code
INSERT INTO my_table (id, name) VALUES (1, 'John Doe');
- 检查 Kafka Topic: 使用 Kafka 命令行工具检查同步的数据是否已经到达 Kafka Topic。
bashCopy code
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic my_oracle_topic --from-beginning
如何选:综合对比,选择与自身需求更加匹配的方案
面对如此多的数据同步方案,在做调研时往往涉及多方考虑。综合来看,各个类型的方案各有优劣:
① 手动配置方案
优势:
- 定制性: 完全自定义的配置允许满足特定业务场景的要求。
- 无额外成本: 不需要额外的软件许可费用。
劣势:
- 复杂性: 需要手动处理所有步骤,可能会增加配置和管理的复杂性
- 维护难度: 对于复杂的同步需求,手动配置可能导致维护难度增加。
- 时间成本: 手动配置需要更多的时间和技术经验。
② 官方工具 OGG
优势:
- 成熟稳定: OGG 是 Oracle 提供的官方工具,经过多年的发展和改进,具有稳定性和成熟性。
- 可视化管理:OGG 提供了管理界面,简化了配置和监控过程。
劣势:
- 资金成本: 付费工具且价格较高,需要一定的成本投入。
- .学习成本: 具有一定的学习门槛,尤其是对于初学者而言。
③ Tapdata 方案
优势:
- 简化配置: Tapdata 提供了简化的配置界面,降低了配置复杂性,无论是操作还是维护都更加简单
- 实时监控: 提供实时监控和报警功能,方便管理和维护。
- 低延迟: Tapdata 强调低延迟,根据任务的 tps 对任务进行拆分,适用于对实时性要求较高的场景。
- 云原生:支持云版本,对云上生态融合更友好
劣势:
- 资金成本:Tapdata 本地部署版本,以及 Tapdata Cloud 到达一定链路数时需要支付额外费用。
- 资源占用:需要占用少量的数据库资源进行日志解析
考虑因素:
- 根据需求选择: 根据具体需求和团队技能,选择适合的方案。手动配置适合对配置有深入理解的团队,OGG适合对稳定性和功能有更高要求的场景,而 Tapdata 则适用于希望快速配置和低延迟的场景。
- 成本和效率权衡: 考虑购买费用、学习曲线和配置效率之间的权衡。
- 生态整合: 考虑工具的生态整合,特别是与已有系统和工具的集成。
总体而言,将 Oracle 数据实时同步到 Kafka 为企业提供了更灵活、高效、实时的 数据处理和分析能力,有助于构建现代化的数据架构,适应迅速变化的业务环境。通过选择适合自身业务需求的同步方案,如 Debezium、OGG、Tapdata,并合理配置优化,企业可以更好地满足实时数据处理的需求,提升业务的竞争力和应变能力。在这其中,Tapdata 以其低延迟、易用性、可扩展性和实时监控等特点,为企业实现 Oracle 到 Kafka 的实时同步提供了可靠的解决方案。
产品优势:文章来源:https://www.toymoban.com/news/detail-846690.html
- 开箱即用与低代码可视化操作
- 内置 100+ 数据连接器,稳定的实时采集和传输能力
- 秒级响应的数据实时计算能力
- 稳定易用的数据实时服务能力
【相关阅读】文章来源地址https://www.toymoban.com/news/detail-846690.html
- Tapdata Connector 实用指南:云原生数仓场景之数据实时同步到 Databend
- Tapdata Connector 实用指南:如何将 CRM 数据从 Salesforce 实时同步到 MongoDB 等其他库
- Tapdata Connector 实用指南:实时数仓场景之数据实时同步至 ClickHouse
- Tapdata Connector 实用指南:数据入仓场景之数据实时同步到 BigQuery
到了这里,关于Debezium vs OGG vs Tapdata:如何实时同步 Oracle 数据到 Kafka 消息队列?的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!