我的SD-WebUI 可以实现照片说话,也就是SadTalker。看了一下有新的版本,不需要之前那么多模型了。那么让我们看看如何在SD-WebUI 中安装使用 SadTalker 吧。
什么是SadTalker:
SadTalker 是西安交通大学开源的一个基于Stable Diffusion的插件,它能够通过输入图片和音频文件生成会说话或唱歌的数字人视频。
项目地址:
https://github.com/OpenTalker/SadTalker

使用SadTalker,我们需要准备以下硬件条件:
-
一台配备GPU的电脑主机:NVIDIA GeForce RTX 3060显卡(推荐12GB显存以上)、Intel i5 CPU(推荐 i5以上CPU)。
-
Stable Diffusion:这是SadTalker运行的基础平台,推荐使用秋叶的绘世一键包。
-
安装ffmpeg软件:这是一个用于处理视频和音频文件的工具。安装后,需要在系统的环境变量Path中添加ffmpeg的bin路径。(资源可以在文末自取)
如何安装使用:
1. SadTalker插件安装:
首先,我们运行“A绘世启动器.exe”

在左边的“版本管理” 中找到“安装新扩展” 搜索 “SadTalker” 下载安装。

稍等片刻,弹出安装成功。

到此处,SadTalker插件本体已经安装成功了。
2. 模型安装:
我们来到官方提供的链接中下载模型

将上面4个模型文件下载到checkpoints文件夹下,需要自己创建一个checkpoints文件夹。
再将下载的gfpgan 文件放到SadTalker 目录下。

到此处,我们的模型安装完毕啦。(模型资源可以在文末自取)
3. 安装ffmpeg:
下载ffmpeg软件包,将其解压到C盘。

然后将其完整路径添加到系统环境变量,注意是bin目录。

然后我们可以“win+r” 输出“cmd”

调出控制台输入“ffmpeg -version” 出现详细信息就表示ffmpeg安装成功。
4. 运行SadTalker:
打开“A绘世启动器.exe” 启动器,一键启动WebUI。


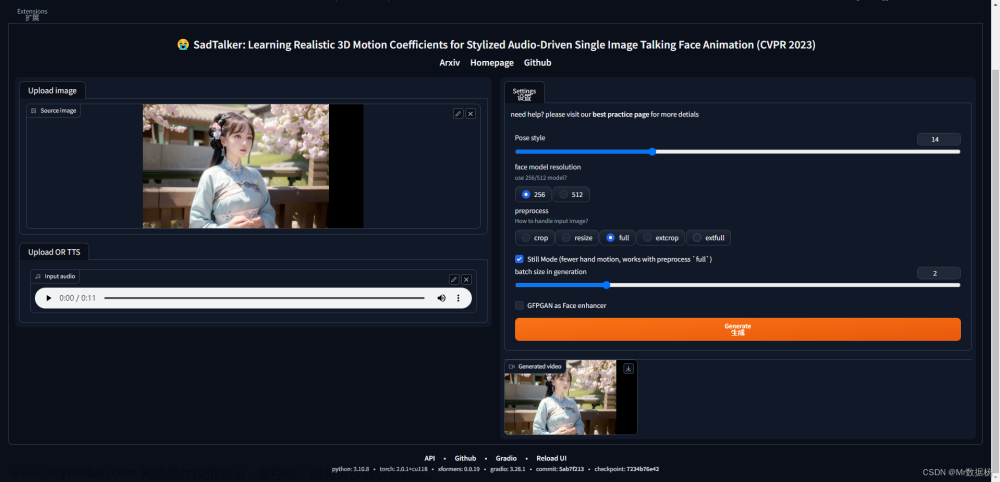
等待安装完成,会自动运行Web。找到上面的“SadTalker”页签。

上传一张图片,和音频文件。

调整参数,点击“生成”。我后台爆显存了,关了面部增强又跑了一遍。
好了,到此我们已经完成了SadTalker在WebUI中的安装和使用,文末扫码相关资源自动获取,
总结:
通过上述步骤,我们成功地在SD-WebUI中安装并使用了SadTalker插件。尽管安装过程涉及多个步骤,但只要按照指导仔细操作,即使是没有太多技术背景的用户也能够顺利完成。SadTalker的实用性在于它能够将静态图片与音频结合,创造出仿佛人物在说话或唱歌的动态视频,这在娱乐、教育甚至广告领域都有广泛的应用前景。
写在最后
AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。
感兴趣的小伙伴,赠送全套AIGC学习资料和安装工具,包含AI绘画、AI人工智能等前沿科技教程,模型插件,具体看下方。
一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!
三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。

四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例文章来源:https://www.toymoban.com/news/detail-846783.html
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。 文章来源地址https://www.toymoban.com/news/detail-846783.html
文章来源地址https://www.toymoban.com/news/detail-846783.html
若有侵权,请联系删除 到了这里,关于SD-WebUI-SadTalker:让照片说话,数字人使用方法的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!