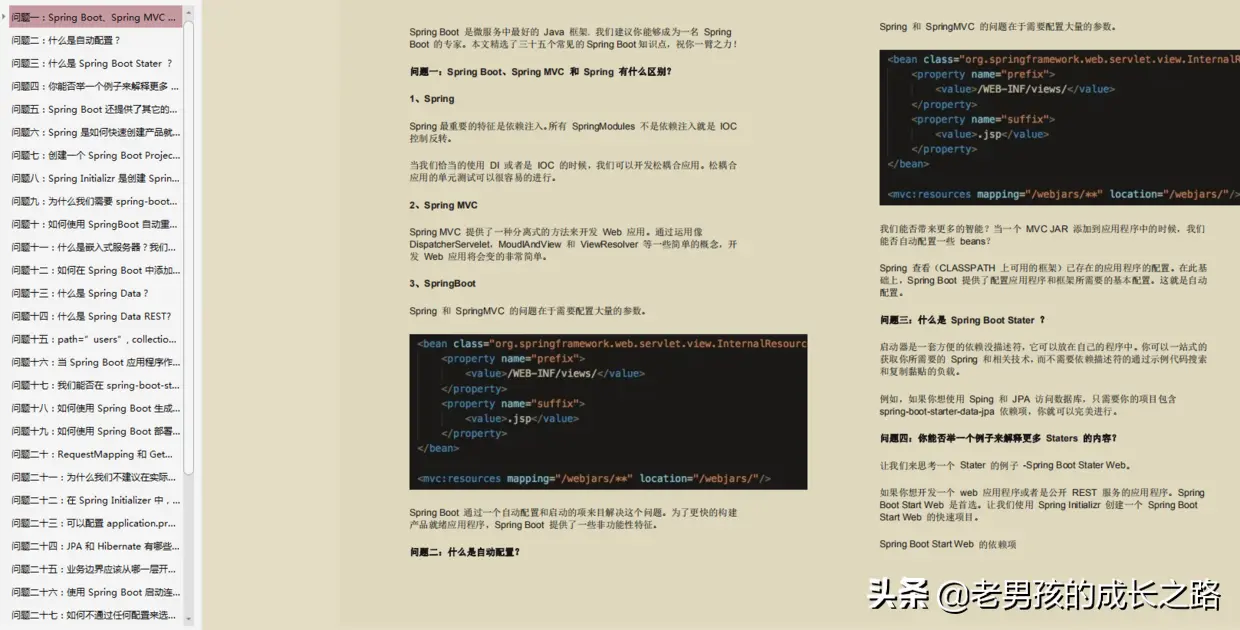
1. Spark VS Hadoop区别?

2. Hadoop的基于进程的计算和Spark基于线程方式优缺点?
Hadoop中的MR中每个map/reduce task都是一个java进程方式运行,好处在于进程之间是互相独立的,每个task独享进程资源,没有互相干扰,监控方便,但是问题在于task之间不方便共享数据,执行效率比较低。比如多个map task读取不同数据源文件需要将数据源加载到每个map task中,造成重复加载和浪费内存。而基于线程的方式计算是为了数据共享和提高执行效率,Spark采用了线程的最小的执行单位,但缺点是线程之间会有资源竞争。
3. Spark四大特点
- 速度快
- 易于使用
- 通用性强
- 支持多种运行方式
4. Spark的架构角色

5. Spark运行模式
-
Local模式
- Local模式可以限制模拟Spark集群环境的线程数量, 即Local[N] 或Local[*]
- 其中N代表可以使用N个线程,每个线程拥有一个cpu core。如果不指定N,则默认是1个线程(该线程有1个core)。通常Cpu有几个Core,就指定几个线程,最大化利用计算能力。
-
Standalone模式
StandAlone 是完整的Spark运行环境,其中:
- Master角色以Master进程存在, Worker角色以Worker进程存在
- Driver和Executor运行于Worker进程内, 由Worker提供资源供给它们运行

-
SparkOnYarn模式
- Master角色由YARN的ResourceManager担任
- Worker角色由YARN的NodeManager担任
- Driver角色运行在YARN容器内或提交任务的客户端进程中
- 真正干活的Executor运行在YARN提供的容器内

【注】Spark On YARN是有两种运行模式的,一种是Cluster模式一种是Client模式
Cluster模式即:Driver运行在YARN容器内部, 和ApplicationMaster在同一个容器内
Client模式即:Driver运行在客户端进程中, 比如Driver运行在spark-submit程序的进程中
6. Job\State\Task的关系?
一个Spark程序会被分成多个子任务(Job)运行, 每一个Job会分成多个State(阶段)来
运行, 每一个State内会分出来多个Task(线程)来执行具体任务
7. Python On Spark 执行原理
PySpark宗旨是在不破坏Spark已有的运行时架构,在Spark架构外层包装一层Python API,借助Py4j实现Python和Java的交互,进而实现通过Python编写Spark应用程序,其运行时架构如下图所示。
8. RDD
8.1 什么是RDD?
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,代表一个不可变、可分区、里面的元素可并行计算的集合。
Resilient:RDD中的数据可以存储在内存中或者磁盘中
8.2 RDD的特性
- RDD是有分区的,RDD的分区是RDD数据存储的最小单位
- RDD的方法会作用在其所有的分区上
- RDD之间是有依赖关系(RDD有血缘关系)
9. RDD算子
9.1 算子是什么?
分布式对象的API,叫做算子
9.2 算子分类
-
Transformation:转换算子
定义:RDD的算子,返回值仍旧是一个RDD的,称之为转换算子
特性:这类算子是lazy 懒加载的。如果没有action算子,Transformation算子是不工作的 -
Action:行动算子
定义:返回值不是rdd的就是action算子

9.3 Spark 的转换算子 (8 个)
9.4 Spark 的行动算子 (5 个)
10. groupByKey和reduceByKey的区别

groupByKey执行流程:
reduceByKey执行流程:
11. 宽窄依赖

12. Spark是怎么做内存计算的?DAG的作用?Stage阶段划分的作用?

Spark执行流程: 文章来源:https://www.toymoban.com/news/detail-846810.html
文章来源:https://www.toymoban.com/news/detail-846810.html
13. Spark为什么比Mapreduce快?
- Spark算子丰富,Map reduce算子匮乏,Mapreduce很难处理复杂的任务,要想解决复杂的任务,需要写多个MapReduce程序进行串联,多个MR串联通过磁盘交互数据
- Spark可以执行内存迭代,算子之间形成DAG并基于依赖划分阶段后,在阶段内形成内存迭代管道。但是MapReduce的Map和Reduce之间的交互依旧是通过磁盘来交互的
14. Spark Shuffle
DAG中的宽依赖就是Spark中的Shuffle过程 文章来源地址https://www.toymoban.com/news/detail-846810.html
文章来源地址https://www.toymoban.com/news/detail-846810.html
到了这里,关于Spark面试重点的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!