1.一致性哈希是什么
一致性哈希算法就很好地解决了分布式系统在扩容或者缩容时,发生过多的数据迁移的问题。
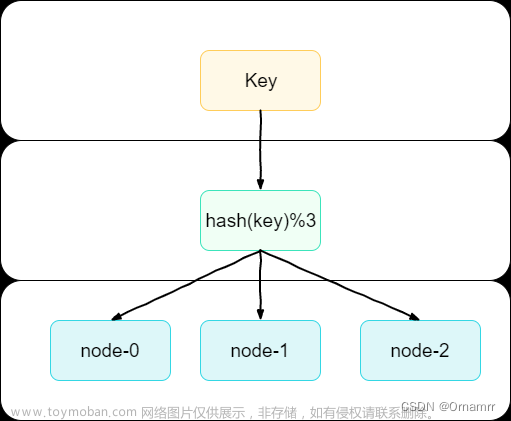
一致哈希算法也用了取模运算,但与哈希算法不同的是,哈希算法是对节点的数量进行取模运算,而一致哈希算法是对 2^32 进行取模运算,是一个固定的值。
一致性哈希要进行两步哈希:
第一步:对存储节点进行哈希计算,也就是对存储节点做哈希映射,比如根据节点的 IP 地址进行哈希;
第二步:当对数据进行存储或访问时,对数据进行哈希映射;
一致性哈希是指将【存储节点】和【数据】都映射到一个首尾相连的哈希环上。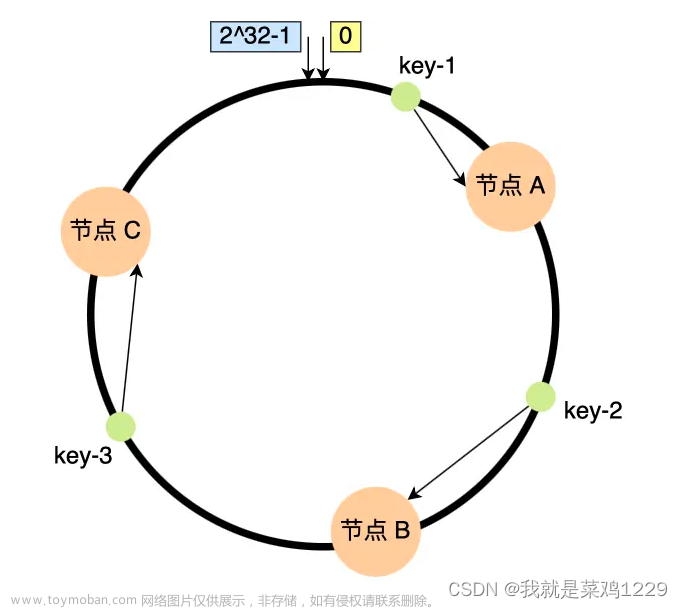
- 首先,对key进行哈希计算,确定此key在换上的位置
- 然后,从这个位置沿着顺时针方向走,遇到的第一节点就上存储key的节点
2. 使用的场景是什么
在负载均衡问题中,不同的负载均衡算法,对应的就是不同的分配策略,适应的业务场景也不同。
- 最简单的方式,引入一个中间的负载均衡层,让它将外界的请求「轮流」的转发给内部的集群。
- 考虑到每个节点的硬件配置有所区别,我们可以引入权重值,将硬件配置更好的节点的权重值设高,然后根据各个节点的权重值,按照一定比重分配在不同的节点上,让硬件配置更好的节点承担更多的请求,这种算法叫做加权轮询。

但是,加权轮询算法是无法应对「分布式系统(数据分片的系统)」的,因为分布式系统中,每个节点存储的数据是不同的。
比如一个分布式 KV(key-valu) 缓存系统,某个 key 应该到哪个或者哪些节点上获得,应该是确定的,不是说任意访问一个节点都可以得到缓存结果的。
3. 使用哈希算法的问题
哈希算法能够对同一个关键字进行哈希计算,每次计算都是相同的值,这样就可以将某个key确定到一个节点了,可以满足分布式系统的负载均衡需求。
存在的致命问题:如果节点数量发生了变化,也就是在对系统做扩容或者缩容时,必须迁移改变了映射关系的数据,否则会出现查询不到数据的问题。
要解决这个问题的办法,就需要我们进行迁移数据,比如节点的数量从 3 变化为 4 时,要基于新的计算公式 hash(key) % 4 ,重新对数据和节点做映射。
假设总数据条数为 M,哈希算法在面对节点数量变化时,最坏情况下所有数据都需要迁移,所以它的数据迁移规模是 O(M),这样数据的迁移成本太高了。
4.一致性哈希算法进阶
4.1 一致性哈希算法存在的问题
一致性哈希算法并不保证节点能够在哈希环上分布均匀,这样就会带来一个问题,会有大量的请求集中在一个节点上。
上图中如果节点 A 被移除了,当节点 A 宕机后,根据一致性哈希算法的规则,其上数据应该全部迁移到相邻的节点 B 上,这样,节点 B 的数据量、访问量都会迅速增加很多倍,一旦新增的压力超过了节点 B 的处理能力上限,就会导致节点 B 崩溃,进而形成雪崩式的连锁反应。
所以,一致性哈希算法虽然减少了数据迁移量,但是存在节点分布不均匀的问题。
4.2 通过虚拟节点提高均衡度
要想解决节点能在哈希环上分配不均匀的问题,就是要有大量的节点,节点数越多,哈希环上的节点分布的就越均匀。
但问题是,实际中我们没有那么多节点。所以这个时候我们就加入虚拟节点,也就是对一个真实节点做多个副本。
具体做法是,不再将真实节点映射到哈希环上,而是将虚拟节点映射到哈希环上,并将虚拟节点映射到实际节点,所以这里有「两层」映射关系。
比如对每个节点分别设置 3 个虚拟节点:
对节点 A 加上编号来作为虚拟节点:A-01、A-02、A-03
对节点 B 加上编号来作为虚拟节点:B-01、B-02、B-03
对节点 C 加上编号来作为虚拟节点:C-01、C-02、C-03
引入虚拟节点后,原本哈希环上只有 3 个节点的情况,就会变成有 9 个虚拟节点映射到哈希环上,哈希环上的节点数量多了 3 倍。

节点数量多了后,节点在哈希环上的分布就相对均匀了。这时候,如果有访问请求寻址到「A-01」这个虚拟节点,接着再通过「A-01」虚拟节点找到真实节点 A,这样请求就能访问到真实节点 A 了。
总结:
- 一个真实节点对应N个虚拟节点
- 一个虚拟节点对应N个key
5. 代码实现
下面是用go实现的代码:
import (
"hash/crc32"
"sort"
"strconv"
)
// Hash map bytes to uint32
type Hash func(data []byte) uint32
// 包含所有的hashed keys
type Map struct {
hash Hash //Hash 函数
replicas int //虚拟节点倍数
keys []int //虚拟节点的哈希环
hashMap map[int]string //虚拟节点与真实节点的映射表,键是虚拟节点的哈希值,值是真实节点的名称。
}
// New create a Map instance
func New(replicas int, fn Hash) *Map {
m := &Map{
replicas: replicas,
hash: fn,
hashMap: make(map[int]string),
}
if m.hash == nil {
m.hash = crc32.ChecksumIEEE
}
return m
}
func (m *Map) Add(keys ...string) {
for _, key := range keys {
for i := 0; i < m.replicas; i++ {
// 虚拟节点在哈希环上的hash值
hash := int(m.hash([]byte(strconv.Itoa(i) + key)))
m.keys = append(m.keys, hash)
// 虚拟节点和真实节点的映射
m.hashMap[hash] = key
}
}
sort.Ints(m.keys)
}
func (m *Map) Get(key string) string {
if len(m.keys) == 0 {
return ""
}
// 要查询的key的hash
hash := int(m.hash([]byte(key)))
// 找到最近的虚拟节点对应的下标idx
idx := sort.Search(len(m.keys), func(i int) bool {
return m.keys[i] >= hash
})
//顺时针找到第一个匹配的虚拟节点的下标 idx,从 m.keys 中获取到对应的哈希值。如果 idx == len(m.keys),说明应选择 m.keys[0],因为 m.keys 是一个环状结构,所以用取余数的方式来处理这种情况。
//m.keys[idx%len(m.keys)]获得虚拟节点的hash
//根据虚拟节点的hash值获取真实节点
return m.hashMap[m.keys[idx%len(m.keys)]]
}
6.总结
一致性哈希是指将「存储节点」和「数据」都映射到一个首尾相连的哈希环上,如果增加或者移除一个节点,仅影响该节点在哈希环上顺时针相邻的后继节点,其它数据也不会受到影响。
但是一致性哈希算法不能够均匀的分布节点,会出现大量请求都集中在一个节点的情况,在这种情况下进行容灾与扩容时,容易出现雪崩的连锁反应。
为了解决一致性哈希算法不能够均匀的分布节点的问题,就需要引入虚拟节点,对一个真实节点做多个副本。不再将真实节点映射到哈希环上,而是将虚拟节点映射到哈希环上,并将虚拟节点映射到实际节点,所以这里有「两层」映射关系。文章来源:https://www.toymoban.com/news/detail-847043.html
引入虚拟节点后,可以会提高节点的均衡度,还会提高系统的稳定性。所以,带虚拟节点的一致性哈希方法不仅适合硬件配置不同的节点的场景,而且适合节点规模会发生变化的场景。文章来源地址https://www.toymoban.com/news/detail-847043.html
到了这里,关于【负载均衡——一致性哈希算法】的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!