Stable Diffusion是一个文本转图像的模型,由CompVis、Stability AI和LAION共同开发。它能够从一段简单的文本输入中快速生成相应的图像。此外,它还可以导入图像并配合文本对其进行处理。从技术角度来看,Stable Diffusion可以理解为从一张完全的高斯噪音图像开始,根据用户输入的要求,逐步剔除噪音,直到产生出用户所要图片的过程。
接下来,让我们使用stable diffusion模型来生成有趣的动漫图像吧!
step1:stable diffusion模型获取
方法1:stable diffusion官网地址为Stable Diffusion 3 — Stability AI,可以参考网站Home · AUTOMATIC1111/stable-diffusion-webui Wiki (github.com)安装使用模型。本地下载,这个方法需要读者具有较好的电脑设备,最好有英伟达的GPU,详细方法可参考Install and Run on NVidia GPUs。下方我们介绍一下文中方法1的安装步骤:
- 在网站Release v1.0.0-pre · AUTOMATIC1111/stable-diffusion-webui (github.com)下载
sd.webui.zip,下载解压后把解压后的文件夹放在一个合适的位置上; - 首先,运行文件夹中的update.bat文件,再运行文件夹中的run.bat文件,如果如果不出意外的话,你将会在浏览器看到以下内容:

方法2:如果本地无法进行安装,则可以尝试使用stable diffusion的国内镜像服务,比如下方这款AUTOMATIC1111/stable-diffusion-webui/NovelAI-Consolidation-Package-3.1: [自带UI启动器]最强云端AI绘画整合版-SDWebUi1.8+SDXL+最新Controlnet+DB训练插件+Roop+AnimateDiffV3+各种插件以及各种依赖模型下载(镜像长期维护更新) - CG (codewithgpu.com)
也可以通过下方一些网站体验文生图或图生图的功能,不过界面可能会与stable diffusion不同,本文后序讲解将基于stable diffusion原始界面:
- Vega AI 创作平台
- 意间ai (yjai.art)
- 飞桨AI Studio星河社区-人工智能学习与实训社区 (baidu.com)
step2:动漫图像的获取步骤
此处,我们介绍在本地安装stable diffusion模型后的步骤工作。
首先,利用stable diffusion自带的模型基本上获得不了好看的动漫图像,这时,我们不妨在CamelliaMIx_2.5D - V3 | Stable Diffusion Checkpoint | Civitai中下载CamelliaMIx_2.5D模型,将模型进行导入。
将下载好的模型文件放入\sd.webui\webui\models\Stable-diffusion文件夹中,你会发现该文件夹中有原始的stable diffusion模型,不过之后我们将使用新的模型生成图像。可以看到,在相同提示词下,新的模型将有更符合大众审美的输出:

step3:如何生成更好的提示词
要使用Stable Diffusion模型生成有趣的动漫图像并获得更好的提示词,你可以遵循以下方法和步骤:
- 明确目标:首先,确定你想要生成的动漫图像的主题、风格和氛围。是可爱的、搞笑的、还是冒险的?明确目标有助于你更精准地选择提示词。
- 收集灵感:浏览各种动漫作品、插画、艺术作品或在线资源,以收集灵感和参考。注意动漫中的颜色搭配、角色设计、场景构图等元素。
- 分析并提取关键词:从你收集的灵感中,分析并提取出与主题、风格、角色、场景等相关的关键词。这些关键词将成为你的提示词的基础。
- 构建提示词:使用提取出的关键词来构建你的提示词。尝试使用不同的组合和顺序,以找到最能表达你想法的提示词。可以包括画风(如“anime style”)、角色特征(如“cute girl with big eyes”)、场景描述(如“sunny park”)等。
- 简化与精炼:保持提示词简洁明了,避免冗长和复杂的描述。精炼的提示词更容易被模型理解和执行。
- 测试与优化:在Stable Diffusion模型中输入你的提示词,并观察生成的图像。根据结果,调整和优化你的提示词。尝试添加或删除某些关键词,改变关键词的顺序,或调整参数设置,以获得更满意的结果。
记住,Stable Diffusion模型的结果受到多种因素的影响,包括模型的训练数据、参数设置以及你的提示词选择。因此,可能需要一些尝试和调整才能获得理想的结果。
我们不妨让大语言模型替我们生成一些提示词,如下图所示:

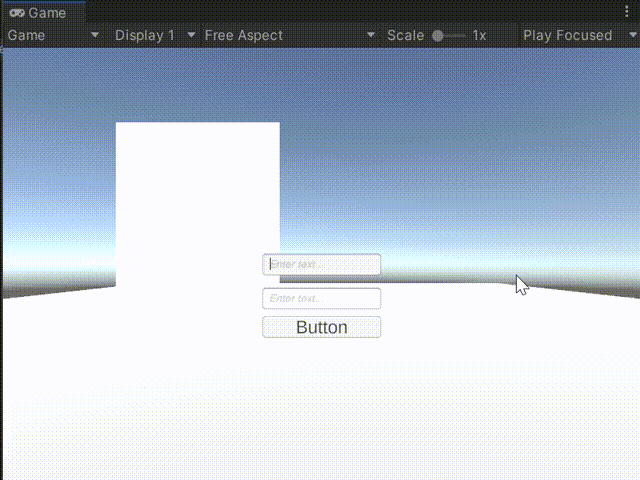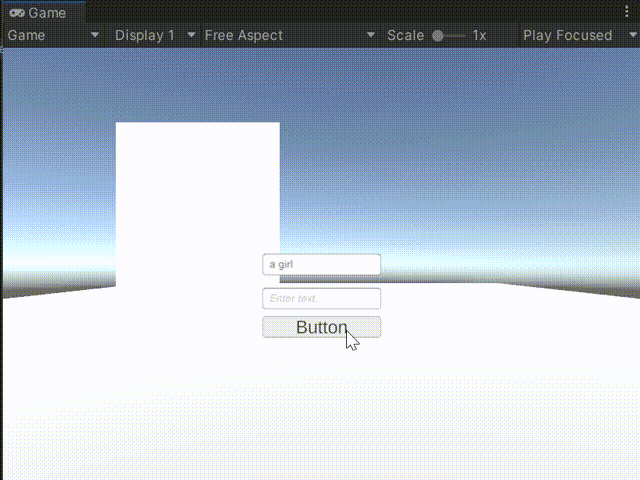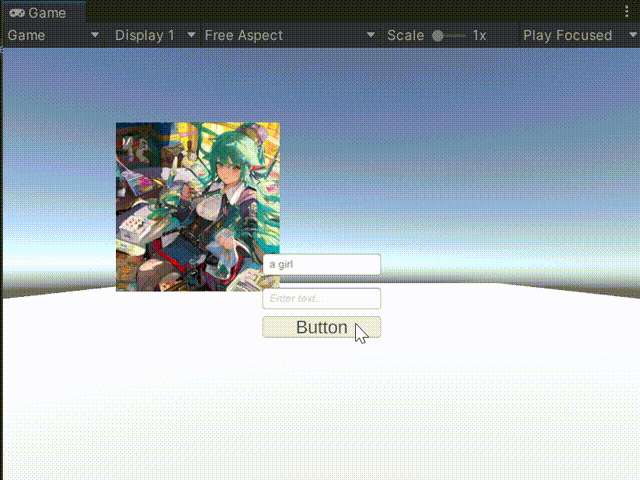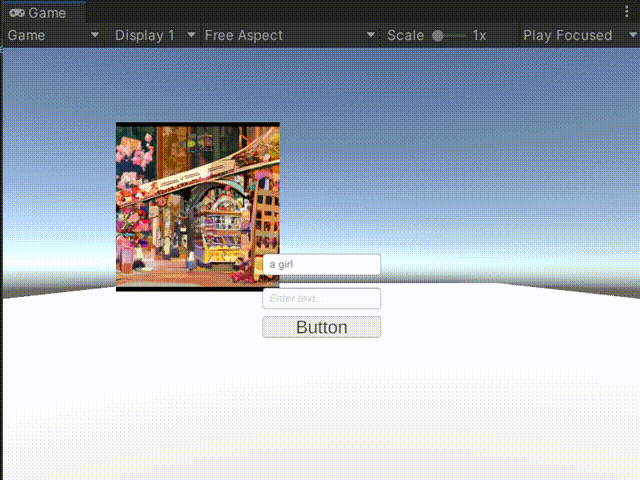
接下来,我们将这些提示词放入模型中,看看能生成一些什么样的图片吧!





可以看到模型输出结果还是可以的,使用过模型的友友肯定知道,模型有时候会输出一些“怪异”的图像,这需要我们不断尝试,最后找到合适的生成图。文章来源:https://www.toymoban.com/news/detail-847363.html
文章来源地址https://www.toymoban.com/news/detail-847363.html
到了这里,关于文生图——stable diffusion生成有趣的动漫图像的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!