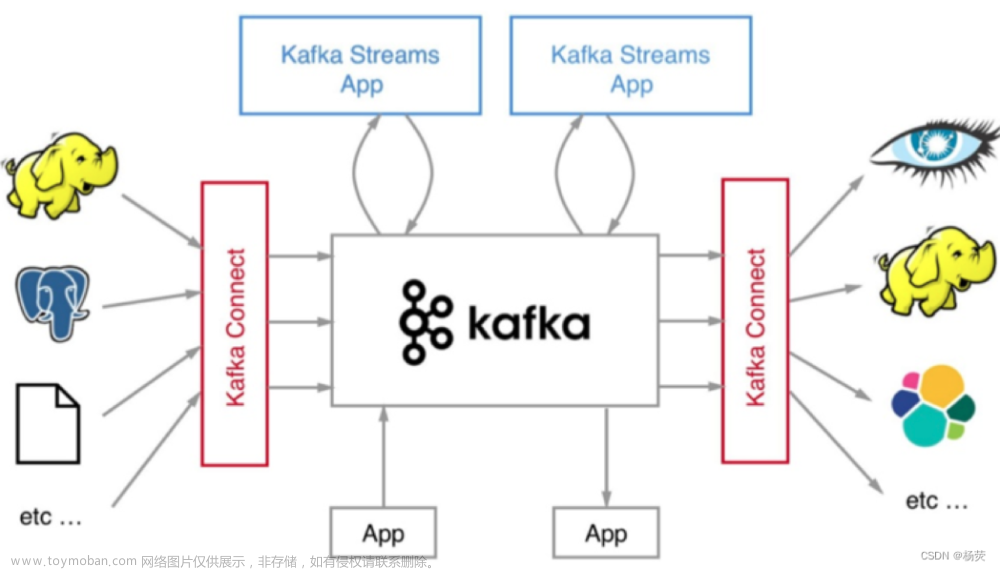
目录
Kafka消息生产
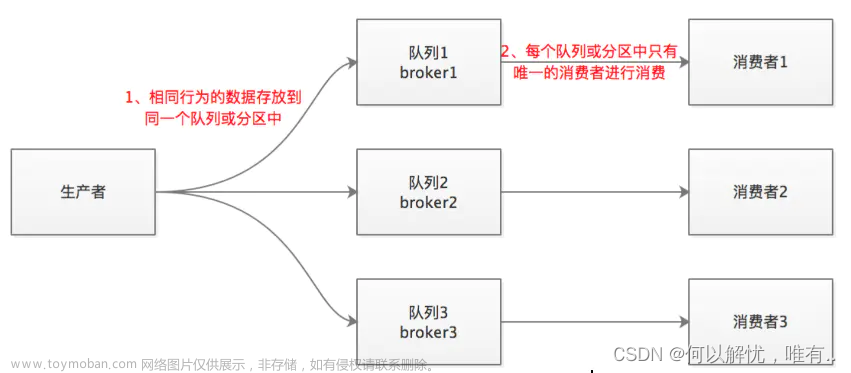
一个Topic对应一个Partition
一个Topic对应多个Partition
Kafka消息的顺序性保证(Producer、Consumer)
全局有序
局部有序
max.in.flight.requests.per.connection参数详解
Kafka的多副本机制
Kafka的follower从leader同步数据的流程
Kafka的follower为什么不能用于消息消费
Kafka的多分区(partition)以及多副本(Replica)机制的作用
Kafka和Zookeeper的关系
Kafka如何保证消息不丢失
Kafka消息发送模式
Kafka保证消息不丢失的措施
Kafka为什么这么快
Kafka如何保证消息不被重复消费
生产者消息重复发送
消费者消息重复消费
Kafka消息消费失败
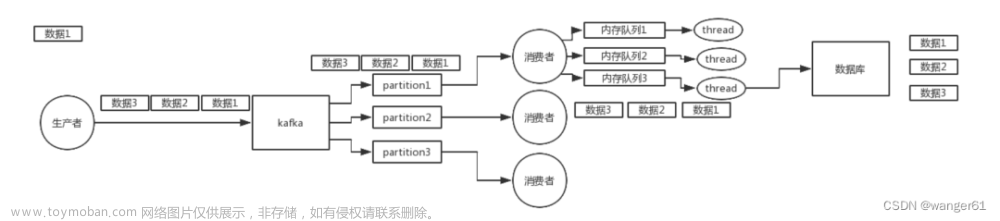
Kafka消息生产
一个Topic对应一个Partition
生产者生产的所有数据都会发送到此Topic对应的Partition下,从而保证消息的生产顺序。
一个Topic对应多个Partition
此时Kafka根据时机情况采取三种消息分发机制:
- partition在写入的时候可以指定需要写入的partition,如果有指定,则写入对应的partition。
没有指明 partition 值但有 key 的情况下,将 key 的 hash 值与 topic 的 partition数进行取余得到 partition 值;在Producer往Kafka插入数据时,控制同一Key分发到同一Partition。
既没有 partition 值又没有 key 值的情况下,第一次调用时随机生成一个整数(后
面每次调用在这个整数上自增),将这个值与 topic 可用的 partition 总数取余得到 partition值,也就是常说的 round-robin 算法。
Kafka消息的顺序性保证(Producer、Consumer)
- 全局有序: 一个Topic下的所有消息都需要按照生产顺序消费。
- 局部有序:一个Topic下的消息,只需要满足同一业务字段的要按照生产顺序消费。例如:Topic消息是订单的流水表,包含订单orderId,业务要求同一个orderId的消息需要按照生产顺序进行消费。
全局有序
全局有序需要保证一个Topic下的所有消息都需要按照生产顺序消费。此时设置一个Topic下只对应一个Partition即可。而且对应的consumer也要使用单线程或者保证消费顺序的线程模型。即可保证全局有序。
局部有序
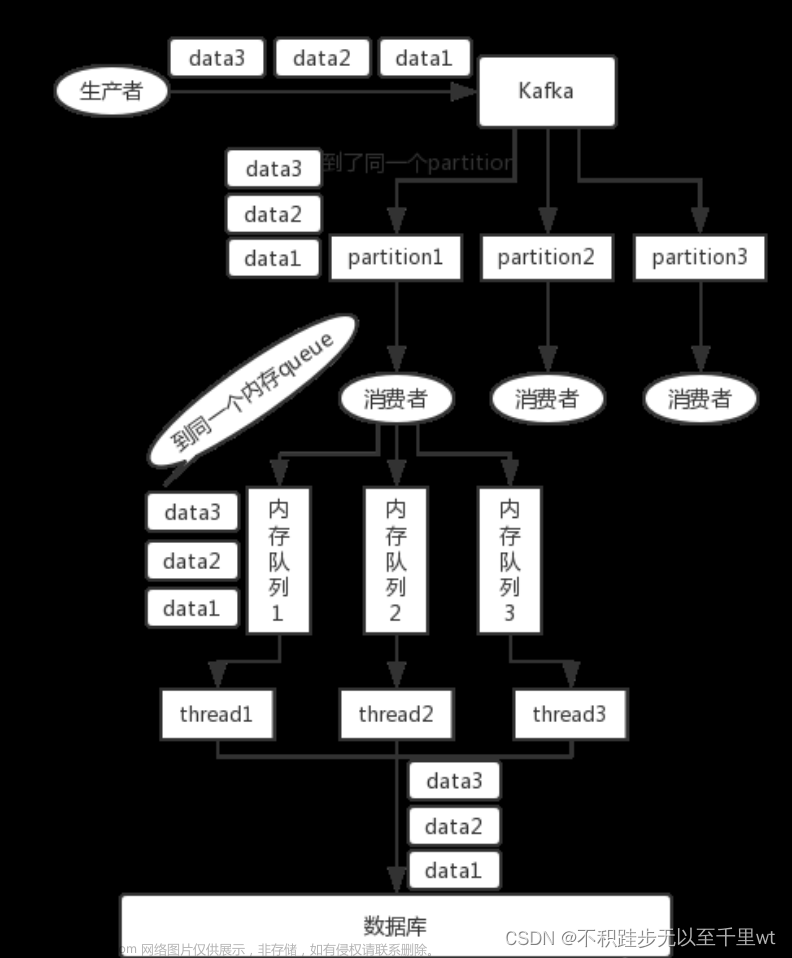
要满足局部有序,只需要在发消息的时候指定Partition Key,Kafka对其进行Hash计算,根据计算结果决定放入哪个Partition。这样Partition Key相同的消息会放在同一个Partition。此时,Partition的数量仍然可以设置多个,提升Topic的整体吞吐量。并且为了达到严格的顺序消费还需要max.in.flight.requests.per.connection = 1。
不直接指定对应的Partition而是指定Partition Key
- 直接指定Partition,将所有消息指定到一个Partition中,此时相当于全局有序,此Topic下的其他Partition无用,浪费资源。
- 将不同的消息设置不同的Partition,此时生产者需要进行额外的计算,不好控制具体的Partition值。
在不增加partition数量的情况下想提高消费速度,可以考虑再次hash唯一标识(例如订单orderId)到不同的线程上,多个消费者线程并发处理消息(依旧可以保证局部有序)。
max.in.flight.requests.per.connection参数详解
消息重试对消费顺序的影响:对于一个有着先后顺序的消息A、B,正常情况下应该是A先发送完成后再发送B,但是在异常情况下,在A发送失败的情况下,B发送成功,而A由于重试机制在B发送完成之后重试发送成功了。这时对于本身顺序为AB的消息顺序变成了BA。
针对这种问题,严格的顺序消费还需要max.in.flight.requests.per.connection参数的支持。该参数指定了生产者在收到服务器响应之前可以发送多少个消息。它的值越高,就会占用越多的内存,同时也会提升吞吐量。把它设为1就可以保证消息是按照发送的顺序写入服务器的。
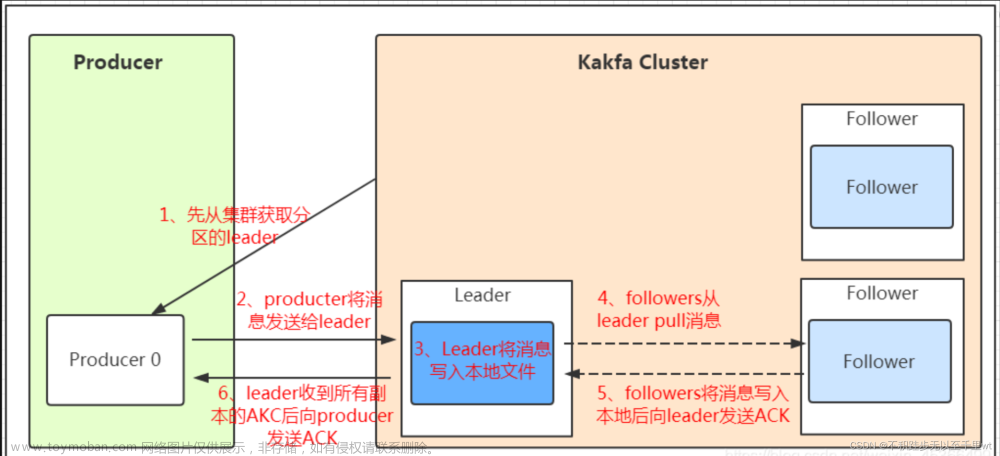
保证消息不丢失是一个消息队列中间件的基本保证,那producer在向kafka写入消息的时候,怎么保证消息不丢失呢?其实上面的写入流程图中有描述出来,那就是通过ACK应答机制!在生产者向队列写入数据的时候可以设置参数来确定是否确认kafka接收到数据,这个参数可设置的值为0、1、all。
- 0代表producer往集群发送数据不需要等到集群的返回,不确保消息发送成功。安全性最低但是效率最高。
- 1代表producer往集群发送数据只要leader应答就可以发送下一条,只确保leader发送成功。
- all代表producer往集群发送数据需要所有的follower都完成从leader的同步才会发送下一条,确保leader发送成功和所有的副本都完成备份。安全性最高,但是效率最低。
最后要注意的是,如果往不存在的topic写数据,能不能写入成功呢?kafka会自动创建topic,分区和副本的数量根据默认配置都是1。
此外,对于某些业务场景,设置max.in.flight.requests.per.connection=1会严重降低吞吐量,如果放弃使用这种同步重试机制,则可以考虑在消费端增加失败标记的记录,然后用定时任务轮询去重试这些失败的消息并做好监控报警。
Kafka的多副本机制
Kafka为分区(Partition)引入多副本(Replica)机制,分区(Partition)中的多个副本中有一个leader,其余称为leader的follower。我们的消息发送到leader副本,然后follower副本才能从leader副本中拉取消息进行同步。
Kafka的follower从leader同步数据的流程
- 初始同步请求:当一个新的follower加入集群或者现有的follower与leader失去连接后重新连接时,follower会向leader发送一个初始同步请求(Initial Fetch Request),请求获取最新的数据。
- 获取偏移量信息:leader响应这个请求,发送给follower最新的日志文件(log file)名称和偏移量(offset)。这告诉follower从哪个位置开始拉取数据。
- 数据拉取:根据从leader获取的偏移量信息,follower开始从leader拉取数据。这些数据通常是leader日志文件中的一部分或全部内容。
- 写入本地副本:follower在接收到数据后,会将这些数据写入自己的本地副本中。这确保了即使leader发生故障,follower也有完整的数据副本。
- 提交偏移量:一旦数据写入完成,follower会向leader发送一个确认消息,告知已经成功写入的偏移量。这个确认是Kafka复制协议的一部分,确保leader知道哪些数据已经被follower成功接收和写入。
- 持续同步:在初始同步之后,follower会持续地监听leader的日志变化。每当leader有新的数据写入时,follower都会按照上述流程拉取并写入这些数据。
- 故障恢复和选举:如果leader发生故障,Kafka集群中的其他节点(通常是follower)会通过ZooKeeper进行选举,选出一个新的leader。选举成功后,新的leader会继续接受生产者的写入请求,并同步数据到其他的follower。
- 日志截断:在某些情况下,如删除旧的topic分区或执行日志压缩时,leader可能会截断其日志文件。当这种情况发生时,leader会通知所有的follower进行相同的截断操作,以确保所有副本的一致性。
整个同步流程是异步的,并且设计得足够高效,以便在Kafka集群中处理大量的数据和高并发的读写操作。此外,Kafka还通过一系列的优化手段(如批量拉取、压缩传输等)来减少同步过程中的网络开销和延迟。
Kafka的follower为什么不能用于消息消费
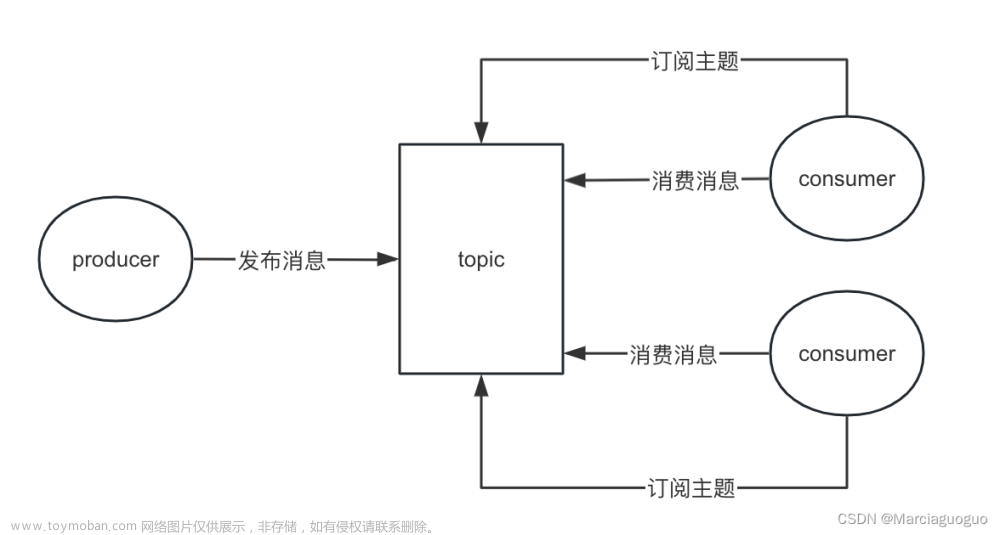
- 对于消息的消费,Kafka采用的是生产者-消费者模式。在这个模式中,生产者将消息写入Kafka的leader分区,而消费者则从leader分区拉取消息进行消费。Kafka通过移交偏移量来控制消费者从哪个位置开始消费消息,从而使得消费者可以按照一定的顺序消费消息。
- Kafka的设计是基于分布式的,所有的读写操作都是在leader分区进行的,follower分区则主要负责从leader同步数据。从而保证分布式环境中数据的一致性和可靠性。
Kafka的多分区(partition)以及多副本(Replica)机制的作用
- Kafka 通过给特定 Topic 指定多个 Partition, 而各个 Partition 可以分布在不同的 Broker 上, 这样便能提供比较好的并发能力(负载均衡)。
- Partition 可以指定对应的 Replica 数, 这也极大地提高了消息存储的安全性, 提高了容灾能力,不过也相应的增加了所需要的存储空间。
Kafka和Zookeeper的关系
Zookeeper主要为Kafka提供元数据的管理的功能。
- Broker注册:在 Zookeeper 上会有一个专门用来进行 Broker 服务器列表记录的节点。每个 Broker 在启动时,都会到 Zookeeper 上进行注册,即到
/brokers/ids下创建属于自己的节点。每个 Broker 就会将自己的 IP 地址和端口等信息记录到该节点中去- Topick注册:在 Kafka 中,同一个Topic 的消息会被分成多个分区并将其分布在多个 Broker 上,这些分区信息及与 Broker 的对应关系也都是由 Zookeeper 在维护。比如我创建了一个名字为 my-topic 的主题并且它有两个分区,对应到 zookeeper 中会创建这些文件夹:
/brokers/topics/my-topic/Partitions/0、/brokers/topics/my-topic/Partitions/1。- 负载均衡:对于同一个 Topic 的不同 Partition,Kafka 会尽力将这些 Partition 分布到不同的 Broker 服务器上。当生产者产生消息后也会尽量投递到不同 Broker 的 Partition 里面。当 Consumer 消费的时候,Zookeeper 可以根据当前的 Partition 数量以及 Consumer 数量来实现动态负载均衡。
在Kafka2.8之前Kafka严重依赖于Zookeeper,在Kafka2.8之后引入了基于Raft协议的KRaft模式,从而使得Kafka不再严重依赖于Zookeeper,可以进行独立的部署,大大简化了Kafka的架构.
Kafka如何保证消息不丢失
Kafka消息发送模式
同步发送模式:发出消息后,必须等待阻塞队列收到通知后,才发送下一条消息;同步发送模式可以保证消息不丢失、又能保证消息的有序性。
SendResult<String, Object> sendResult = kafkaTemplate.send(topic, o).get(); if (sendResult.getRecordMetadata() != null) { logger.info("生产者成功发送消息到" + sendResult.getProducerRecord().topic() + "-> " + sendRe sult.getProducerRecord().value().toString()); }异步发送模式:生产者一直向缓冲区写消息,然后一起写到队列中;好处是吞吐量大,性能高。
ListenableFuture<SendResult<String, Object>> future = kafkaTemplate.send(topic, o); future.addCallback(result -> logger.info("生产者成功发送消息到topic:{} partition:{}的消息", result.getRecordMetadata().topic(), result.getRecordMetadata().partition()), ex -> logger.error("生产者发送消失败,原因:{}", ex.getMessage()));
Kafka保证消息不丢失的措施
-
在
同步模式下,将发送消息的确认机制设置为all,使得所有节点确认后再发送下一条数据即可。 -
在
异步模式下,如果消息发送出去了,但还没有收到确定的时候,在配置文件中设置成不限制阻塞超时的时间,即让生产者一直保持等待,也可以保证数据不丢失。
Kafka为什么这么快
Kafka不基于内存,而是基于磁盘,因此消息堆积能力更强。
- 顺序写磁盘,充分利用磁盘特性:利用磁盘的顺序访问速度可以接近内存,kafka的消息都是append操作,partition是有序的,节省了磁盘的寻道时间,同时通过批量操作、节省写入次数,partition物理上分为多个segment存储,方便删除;
-
零拷贝:
- Producer 生产的数据持久化到 broker,采用 mmap 文件映射,实现顺序的快速写入。
- mmap()系统调用函数会直接把内核缓冲区里的数据「映射」到用户空间,这样,操作系统内核与用户空间就不需要再进行任何的数据拷贝操作;
- Customer 从 broker 读取数据,采用 sendfile,将磁盘文件读到 OS 内核缓冲区后,转到 NIO buffer进行网络发送,减少 CPU 消耗。
- Producer 生产的数据持久化到 broker,采用 mmap 文件映射,实现顺序的快速写入。
- Kafka不依赖于JVM,主要依赖OS的PageCache,如果生产消费速率相当,直接使用PageCache交换数据,不需要经过系统磁盘。
- 消息压缩:Producer 可将数据压缩后发送给 broker,从而减少网络传输代价,目前支持的压缩算法有:Snappy、Gzip、LZ4。数据压缩一般都是和批处理配套使用来作为优化手段的。
- 分批发送:批量处理,合并小的请求,然后以流的方式进行交互,直顶网络上限;
Kafka如何保证消息不被重复消费
生产者消息重复发送
生产发送的消息没有收到正确的broke响应,导致producer重试。
详解:producer发出一条消息,broker落盘以后,因为网络等原因,发送端得到一个发送失败的响应或者网络中断,然后producer收到 一个可恢复的Exception重试消息导致消息重复。
解决:
enable.idempotence=true //此时会默认开启acks=all
acks=all
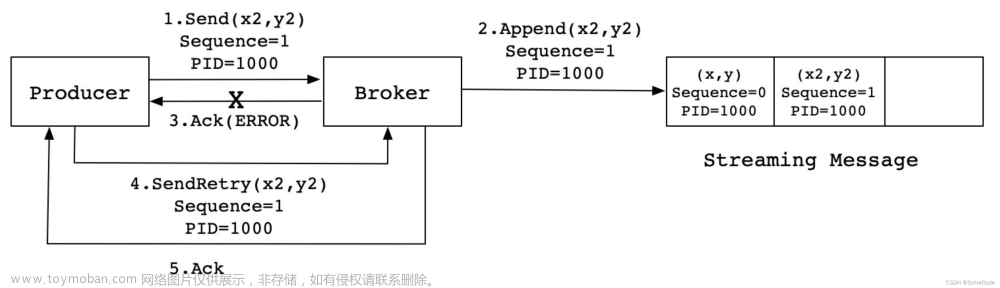
retries>1kafka 0.11.0.0版本之后,正式推出了idempotent producer,支持生产者的幂等。每个生产者producer都有一个唯-id,producer每发送一条数据都会带上一个sequence,当消息落盘,sequence就会递增1。只需判断当前消息的sequence是否大于当前最大sequence,大于就代表此条数据没有落盘过,可以正常消费,不大于就代表落盘过,这个时候重发的消息会被服务端拒掉从而避免消息重复。
消费者消息重复消费
Kafka默认先消费消息,再提交offset。如果消费者在消费了消息之后,消费者挂了,还未提交offset,那么Broker后边会重新让消费者消费。
解决:消费者进行幂等处理,消费者进行幂等处理同样可以处理生产生重复发送消息的问题。
- 将唯一键存入第三方介质,要操作数据的时候先判断第三方介质(数据库或者缓存)有没有这个唯一键。
- 将版本号(offset)存入到数据里面,然后再要操作数据的时候用这个版本号做乐观锁,当版本号大于原先的才能操作。
如:可以用redis的setnx分布式锁来实现。比如操作订单消息,可以把订单id作为key,在消费消息时,通过setnx命令设置一下,offset提交完成后,在redis中删除订单id的key。setnx命令保证同样的订单消息,只有一个能被消费,可有效保证消费的幂等性!上面提到的两种方式需要结合SETNX使用。
Kafka消息消费失败
Kafka默认消息消费失败后的重试次数为10,并且重试间隔为0s。
当达到最大消息重试次数后,数据会直接跳过继续向后执行。消费失败的消息会被加入到死信队列中进行处理。对于死信队列的处理,既可以用 @DltHandler 处理,也可以使用 @KafkaListener 重新消费。
死信队列(Dead Letter Queue,简称 DLQ) 是消息中间件中的一种特殊队列。它主要用于处理无法被消费者正确处理的消息,通常是因为消息格式错误、处理失败、消费超时等情况导致的消息被"丢弃"或"死亡"的情况。当消息进入队列后,消费者会尝试处理它。如果处理失败,或者超过一定的重试次数仍无法被成功处理,消息可以发送到死信队列中,而不是被永久性地丢弃。在死信队列中,可以进一步分析、处理这些无法正常消费的消息,以便定位问题、修复错误,并采取适当的措施。
一文理解Kafka如何保证消息顺序性-腾讯云开发者社区-腾讯云 (tencent.com)
Kafka基本原理详解(超详细!)_kafka工作原理-CSDN博客
如何保证kafka消费的顺序性_kafka顺序消费 如何控制-CSDN博客
kafka专题:kafka的消息丢失、重复消费、消息积压等线上问题汇总及优化_java kafk数据积压导致其他队列消息丢失-CSDN博客Kafka消息重复-原因/解决方案 - 自学精灵 (skyofit.com)文章来源:https://www.toymoban.com/news/detail-847450.html
Kafka常见问题总结 | JavaGuide文章来源地址https://www.toymoban.com/news/detail-847450.html
到了这里,关于Kafka如何保证消息的消费顺序【全局有序、局部有序】、Kafka如何保证消息不被重复消费、Kafka为什么这么快?【重点】、Kafka常见问题汇总【史上最全】的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!