人工智能主要分类算法
人工智能分类算法是用于将数据划分为不同类别的算法。这些算法通过学习数据的特征和模式,将输入数据映射到相应的类别。分类算法在人工智能中具有广泛的应用,如图像识别、语音识别、文本分类等。以下是几种常见的人工智能分类算法的详细讲解过程:
决策树
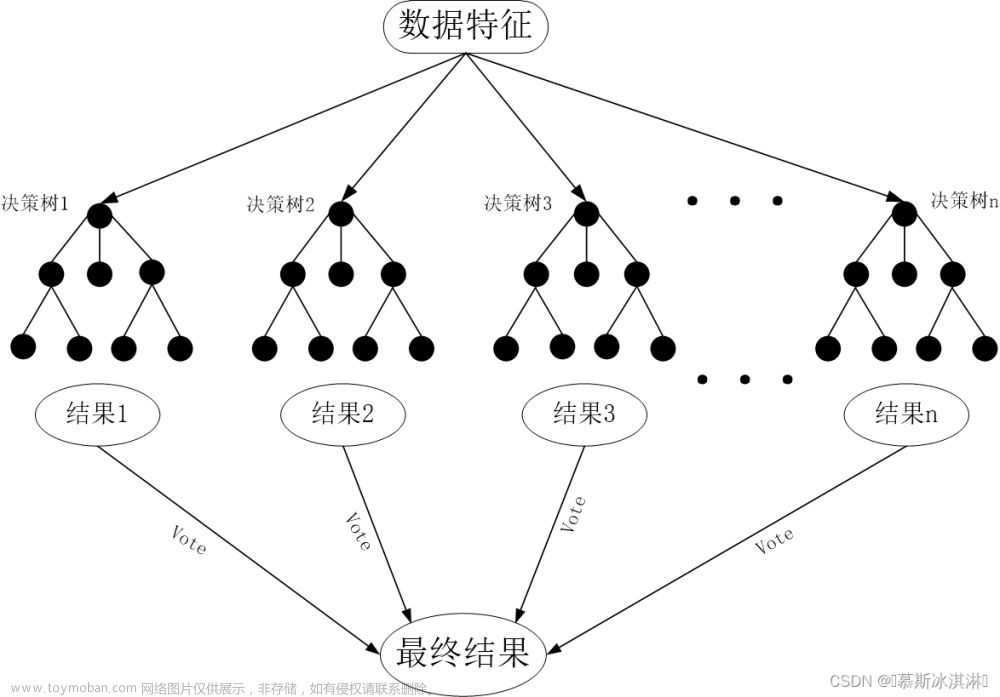
决策树是一种基于树形结构的分类算法。它通过一系列的问题来判断数据应该被分为哪一类。每个节点代表一个问题,根据问题的答案,数据被分为两类,并继续向下遍历直到到达叶节点。决策树的构建过程是根据已有数据学习出来的,当新的数据投入时,就可以根据这棵树上的问题,将数据划分到合适的叶子上。如下图是一个决策树的简单示意图
如下python实现的决策树代码示例:
import numpy as np
from sklearn.tree import DecisionTreeClassifier
# 创建数据集
X = np.array([[1, 1, 1], [2, 2, 2], [3, 3, 3], [4, 4, 4]])
y = np.array([0, 1, 0, 1])
# 创建决策树分类器
clf = DecisionTreeClassifier()
# 训练决策树分类器
clf.fit(X, y)
# 使用决策树分类器进行预测
predictions = clf.predict(X)
print(predictions)
在上述代码中,我们首先导入了NumPy和Scikit-Learn库。然后,我们创建了一个包含3个特征和4个样本的数据集,并使用NumPy将其转换为一个数组。接下来,我们创建了一个决策树分类器对象,并使用fit()方法对其进行训练。最后,我们使用predict()方法对数据集进行预测,并将预测结果打印出来。
随机森林
随机森林是集成学习的一个子类,它依靠于决策树的投票选择来决定最后的分类结果。随机森林通过建立几个模型组合的方式来解决单一预测问题。它的构建过程包括以下几个步骤:首先,从训练用例中以有放回抽样的方式,取样形成一个训练集,并用未抽到的用例作预测,评估其误差;然后,根据特征数目,计算其最佳的分裂方式;最后,重复上述步骤,构建另外一棵棵决策树,直到达到预定数目的一群决策树为止,即构建好了随机森林。

以下是一个使用Python实现随机森林的示例代码:
import numpy as np
from sklearn.ensemble import RandomForestClassifier
# 创建数据集
X = np.array([[1, 1, 1], [2, 2, 2], [3, 3, 3], [4, 4, 4]])
y = np.array([0, 1, 0, 1])
# 创建随机森林分类器
clf = RandomForestClassifier()
# 训练随机森林分类器
clf.fit(X, y)
# 使用随机森林分类器进行预测
predictions = clf.predict(X)
print(predictions)
在上述代码中,我们首先导入了NumPy和Scikit-Learn库。然后,我们创建了一个包含3个特征和4个样本的数据集,并使用NumPy将其转换为一个数组。接下来,我们创建了一个随机森林分类器对象,并使用fit()方法对其进行训练。最后,我们使用predict()方法对数据集进行预测,并将预测结果打印出来。
逻辑回归
逻辑回归是一种常用的监督分类算法。它通过使用逻辑函数估计概率来测量因变量和自变量之间的关系。如果预测目标是概率这样的,值域需要满足大于等于0,小于等于1的,这个时候单纯的线性模型是做不到的,因为在定义域不在某个范围之内时,值域也超出了规定区间。这个模型需要满足两个条件大于等于0,小于等于1。大于等于0的模型可以选择绝对值,平方值,这里用指数函数,一定大于0。再做一下变形,就得到了logisticregression模型。

以下是一个使用Python实现逻辑回归的示例代码:
import numpy as np
from sklearn.linear_model import LogisticRegression
# 创建数据集
X = np.array([[1, 1, 1], [2, 2, 2], [3, 3, 3], [4, 4, 4]])
y = np.array([0, 1, 0, 1])
# 创建逻辑回归模型
clf = LogisticRegression()
# 训练逻辑回归模型
clf.fit(X, y)
# 使用逻辑回归模型进行预测
predictions = clf.predict(X)
print(predictions)
在上述代码中,我们首先导入了NumPy和Scikit-Learn库。然后,我们创建了一个包含3个特征和4个样本的数据集,并使用NumPy将其转换为一个数组。接下来,我们创建了一个逻辑回归模型对象,并使用fit()方法对其进行训练。最后,我们使用predict()方法对数据集进行预测,并将预测结果打印出来。
K-均值
K-均值是一种聚类算法,它通过对数据集进行分类来聚类。K-均值用于无监督学习,因此,我们只需使用训练数据X,以及我们想要识别的聚类数量K。K-均值的基本过程是:首先,随机选择K个初始聚类中心;然后,将每个数据点分配到离它最近的聚类中心所在的类别;接着,重新计算每个类别的聚类中心;最后,重复以上步骤直到聚类中心不再发生变化或达到预设的最大迭代次数。
以下是一个使用Python实现K-均值聚类算法的示例代码:
import numpy as np
def k_means(data, k):
# 数据标准化
data = (data - np.mean(data, axis=0)) / np.std(data, axis=0)
# 随机选择k个质心
centers = np.random.choice(data, size=(k, data.shape[1]), replace=False)
# 迭代聚类
while True:
# 将每个样本分配给最近的质心
labels = np.argmin(np.sum((data[:, None, :] - centers) ** 2, axis=-1), axis=1)
# 更新质心
new_centers = np.array([data[labels == i].mean(axis=0) for i in range(k)])
# 如果质心没有变化,则停止迭代
if np.allclose(centers, new_centers, atol=1e-4):
break
centers = new_centers
return labels, centers
# 测试代码
data = np.array([[1, 2], [2, 3], [3, 4], [4, 5], [5, 6]])
k = 2
labels, centers = k_means(data, k)
print("Labels:", labels)
print("Centers:", centers)
在上述代码中,我们首先导入了NumPy库,然后定义了一个k_means函数来执行K-均值聚类算法。该函数接受两个参数:data表示要聚类的数据,k表示要聚类的类别数。函数首先对数据进行标准化处理,然后随机选择k个质心作为初始聚类中心。接下来,函数进入一个循环,在每次循环中,将每个样本分配给最近的质心,然后更新质心。如果质心没有变化,则停止迭代。最后,函数返回聚类结果和最终的质心。
在测试代码中,我们创建了一个包含5个样本的数据集,每个样本包含两个特征。然后,我们使用k_means函数对数据集进行聚类,并将聚类结果和最终的质心打印出来。文章来源:https://www.toymoban.com/news/detail-847468.html
总结
以上就是几种常见的人工智能分类算法的详细讲解过程。这些算法在人工智能的研究和应用中都有着广泛的应用。文章来源地址https://www.toymoban.com/news/detail-847468.html
到了这里,关于人工智能分类算法概述的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!