在多媒体内容中,视频是一个信息量巨大的载体。然而,有时我们需要从视频中提取出语音信息并转换为文本,比如为视频制作字幕,或是从讲座录像中提取讲稿。这篇技术博客将向你展示如何使用Python将视频中的语音转换为文字。
准备工作
在开始之前,我们需要安装一些库:
-
moviepy:用于视频文件处理 -
SpeechRecognition:用于识别语音并将其转换为文本 -
pydub:用于音频文件格式转换 -
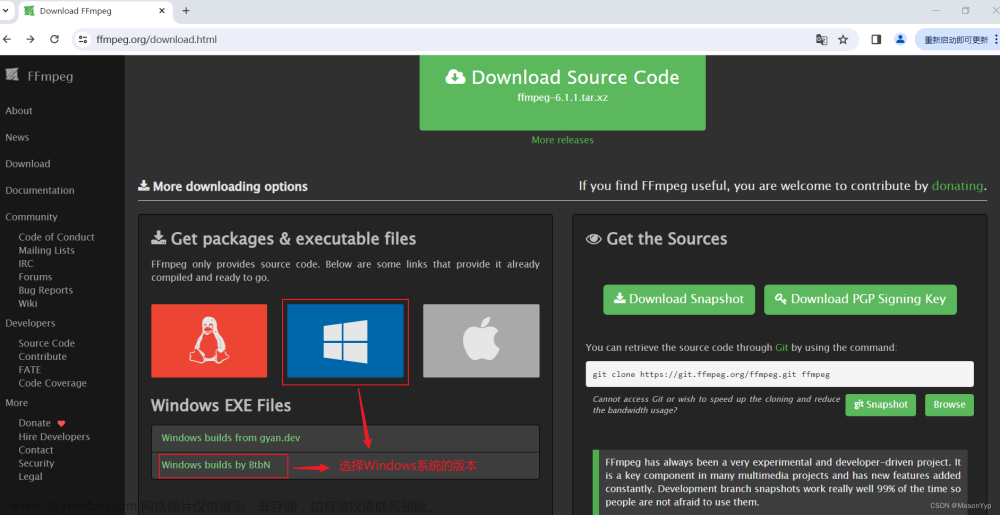
ffmpeg:音视频处理工具(需独立安装)
你可以使用pip来安装所需的Python库:
pip install moviepy SpeechRecognition pydub请确保你的系统中已经安装了ffmpeg。
步骤1:提取视频中的音频
第一步是从视频文件中提取音频。我们可以使用moviepy来做这个工作。
from moviepy.editor import VideoFileClip
# 视频文件路径
video_path = 'your_video.mp4'
# 加载视频文件
video = VideoFileClip(video_path)
# 从视频中提取音频部分
audio = video.audio
# 保存音频为临时文件
audio_path = 'temp_audio.wav'
audio.write_audiofile(audio_path)步骤2:将音频转换为适合识别的格式
SpeechRecognition库在处理音频文件时,需要确保音频是单声道并且采样率适中。我们可以使用pydub来转换音频格式。
from pydub import AudioSegment
# 载入音频文件
audio = AudioSegment.from_wav(audio_path)
# 将音频转换为单声道并设置适当的采样率
audio = audio.set_channels(1)
audio = audio.set_frame_rate(16000)
# 存储转换后的音频文件
processed_audio_path = 'processed_temp_audio.wav'
audio.export(processed_audio_path, format="wav")步骤3:语音识别
现在我们使用SpeechRecognition库来识别音频中的语音。
import speech_recognition as sr
# 初始化识别器
recognizer = sr.Recognizer()
# 从转换后的音频文件中加载数据
with sr.AudioFile(processed_audio_path) as source:
audio_data = recognizer.record(source)
# 识别音频中的语音内容
try:
text = recognizer.recognize_google(audio_data, language='zh-CN') # 假设音频语言为中文
print(text)
except sr.UnknownValueError:
print("Google Speech Recognition could not understand audio")
except sr.RequestError:
print("Could not request results from Google Speech Recognition service")
# 清理临时文件
import os
os.remove(audio_path)
os.remove(processed_audio_path)这段代码将音频内容发送到Google的免费语音识别服务,并尝试将其转换为文本。请注意,这里使用了中文作为语音的语言,你可能需要根据视频中语音的实际语言更改language参数。
结语
以上步骤展示了如何使用Python处理视频和音频文件,以及如何利用现有的语音识别服务,将音频中的语音转换为文字。这种转换在制作视频字幕、内容分析等多种领域都有着广泛的应用。文章来源:https://www.toymoban.com/news/detail-847832.html
请注意,虽然Google的语音识别服务在许多情况下效果不错,但任何自动化的语音识别系统都不可能完美,特别是在音频质量不佳或者包含大量专业术语的情况下。在这些情况下,可能需要人工校对和修改自动生成的文本。文章来源地址https://www.toymoban.com/news/detail-847832.html
到了这里,关于将视频中的语音转换为文字:使用Python实现自动字幕的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!