MySQL是一个关系型数据库管理系统,由瑞典 MySQL AB 公司开发,属于 Oracle 旗下产品。MySQL是最流行的关系型数据库管理系统之一,在 WEB 应用方面,MySQL是最好的RDBMS (Relational Database Management System,关系数据库管理系统)应用软件之一。
数据库的三范式
数据库的三范式是设计关系型数据库时常用的一种规范,它有助于确保数据的一致性和减少数据冗余。三范式分别是:
- 第一范式(1NF):属性不可再分
- 每个字段都是原子性的,即字段不可再分。
- 例如,一个地址字段应该拆分为街道、城市、省份和邮编等独立的字段。
- 第二范式(2NF):完全依赖于主键
- 满足第一范式的基础上,非主键字段必须完全依赖于主键,而不是部分依赖。
- 例如,如果有一个订单详情表,其中包含订单ID、产品ID、数量和价格等字段,那么这个表应该满足第二范式,因为所有非主键字段都完全依赖于主键(订单ID和产品ID)。
- 第三范式(3NF):消除传递依赖
- 满足第二范式的基础上,非主键字段之间不能有传递依赖关系。
- 例如,如果有一个员工表,其中包含员工ID、姓名、部门ID和部门经理ID等字段,那么这个表应该满足第三范式,因为部门经理ID不应该直接依赖于员工ID,而是应该依赖于部门ID。
遵循三范式的数据库设计可以减少数据冗余,提高数据的一致性和可维护性。然而,在实际应用中,为了提高查询性能,有时需要对三范式进行适当的权衡和调整。
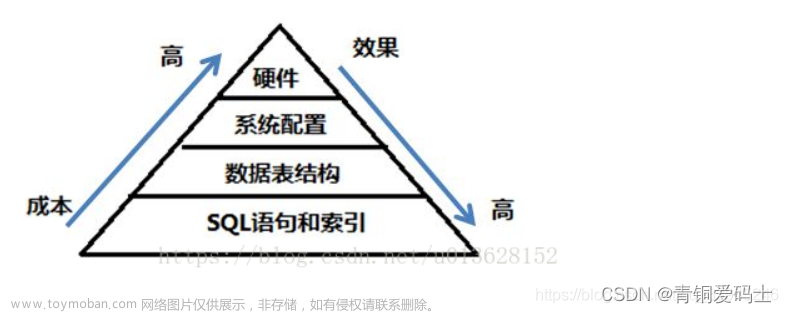
Mysql优化建议
MySQL数据库的优化可以从多个角度进行,包括硬件优化、配置优化、结构设计优化、查询优化等。以下是一些常见的MySQL优化建议:
-
硬件优化:
- 增加内存:提高InnoDB缓冲池的大小,以减少磁盘I/O。
- 使用固态硬盘(SSD):提高数据读写速度。
- 多核处理器和足够的CPU资源:以支持并行查询处理。
-
配置优化:
-
my.cnf或my.ini配置文件调整:根据服务器的硬件资源合理设置InnoDB缓冲池大小、日志文件大小、表空间大小等。 - 调整线程缓存和连接数:根据服务器的负载情况调整。
-
-
结构设计优化:
- 规范化表结构:避免冗余数据,但要注意不要过度规范化,以免造成过多的联合查询。
- 使用合适的数据类型:例如,对于字符串类型的字段,如果长度固定,使用
CHAR比VARCHAR更高效。 - 分割大表:将大表分割为多个小表,以提高查询效率。
-
索引优化:
- 添加合适的索引:为经常用于查询条件的列创建索引。
- 删除不必要的索引:避免过多的索引导致写操作变慢和维护成本增加。
- 使用复合索引:针对多列查询,使用复合索引可以提高查询效率。
-
查询优化:
- 避免SELECT *:只查询需要的列。
- 使用EXPLAIN分析查询:了解查询执行计划,找出瓶颈。
- 优化JOIN操作:选择合适的JOIN类型,减少不必要的JOIN。
- 使用LIMIT分页查询:避免一次性返回大量数据。
-
缓存优化:
- 利用MySQL的查询缓存:对于读取频繁且不经常变动的数据,可以启用查询缓存。
- 使用外部缓存系统:如Redis,减轻数据库的压力。
-
定期维护:
- 定期运行OPTIMIZE TABLE:整理表碎片,提高性能(仅对MyISAM有效)。
- 定期检查和优化表:使用
CHECK TABLE和REPAIR TABLE命令。
-
备份与恢复:
- 定期备份数据库:确保数据安全。
- 测试恢复流程:确保在紧急情况下能快速恢复数据。
-
监控与分析:
- 使用性能监控工具:如Percona Toolkit、MySQLTuner等,定期检查和分析数据库性能。
- 读写分离和负载均衡:
- 实现主从复制:将读操作分散到从库,减轻主库压力。
- 使用负载均衡器:在多个数据库服务器之间分配请求。
请注意,这些建议需要根据实际情况进行调整,不同的应用场景可能需要不同的优化策略。在进行任何重大更改之前,最好在测试环境中进行充分的测试。
Mysql聚集索引
在MySQL中,聚集索引(Clustered Index)是指索引的一种类型,它决定了数据行的物理存储顺序。每个InnoDB表都有一个主键,而这个主键的索引就是聚集索引。聚集索引的叶节点包含了完整的数据行,而非叶节点则包含指向子节点的指针。
以下是一些关于MySQL聚集索引的重要特点:
- 数据行存储顺序:数据行按照聚集索引的顺序存储在磁盘上,这意味着聚集索引决定了数据的物理存储方式。
-
主键作为聚集索引:如果表定义了主键,那么主键就是该表的聚集索引。如果没有显式定义主键,InnoDB会选择一个唯一非空索引作为聚集索引,如果也没有这样的索引,InnoDB会隐式地生成一个名为
GEN_CLUST_INDEX的自动递增列作为聚集索引。 - 叶节点包含数据行:在聚集索引中,叶节点包含了完整的数据行信息,而不仅仅是索引列。这意味着查询时,如果只需要访问索引列,就不需要再单独去查找数据行。
- 一张表只有一个聚集索引:由于聚集索引决定了数据的物理存储方式,因此每张表只能有一个聚集索引。这也是为什么InnoDB表的主键只能有一个的原因。
- 辅助索引(二级索引):除了聚集索引之外,其他的所有索引都称为辅助索引或二级索引。辅助索引的叶节点包含的是指向相应数据行的指针,而不是数据行本身。当查询使用辅助索引时,InnoDB会先查找辅助索引,然后通过指针找到聚集索引中的完整数据行。
- 插入优化:由于聚集索引决定了数据的物理存储顺序,新插入的数据行通常会被放置在已有数据行的末尾。如果新插入的数据行需要放在中间位置,可能会导致大量的数据移动,影响性能。
了解聚集索引的特点对于数据库设计和查询优化非常重要。例如,合理地选择主键可以使得常用的查询更加高效,因为聚集索引能够直接影响到数据行的访问速度。
Mysql的非聚集索引
在MySQL中,非聚集索引(Non-Clustered Index)也被称为二级索引或辅助索引。与聚集索引不同,非聚集索引并不决定数据行的物理存储顺序,而是包含指向数据行的指针。每条索引记录都包含了一个指向实际数据行的地址,以及索引列的值。
以下是一些关于MySQL非聚集索引的重要特点:
- 独立于数据行存储:非聚集索引的叶节点包含了指向数据行的指针,而不是数据行本身。这意味着非聚集索引的结构和数据行的物理存储是独立的。
- 可以有多个:与聚集索引不同,一张表可以有多个非聚集索引。这是因为非聚集索引不决定数据行的物理存储方式,所以可以为不同的列创建多个索引以提高查询效率。
- 访问路径:当查询使用非聚集索引时,InnoDB会先查找非聚集索引,然后通过指针找到聚集索引中的完整数据行。如果查询只需要访问索引列,就不需要再访问数据行。
- 覆盖索引:如果查询只需要访问非聚集索引中的列,而不需要访问数据行中的其他列,这种情况被称为覆盖索引(Covering Index)。覆盖索引可以提高查询效率,因为不需要访问数据行。
- 插入优化:由于非聚集索引不直接影响数据行的物理存储顺序,新插入的数据行对非聚集索引的影响通常比对聚集索引小。这意味着在某些情况下,插入操作可能会更快。
- 维护成本:每个非聚集索引都需要额外的存储空间,并且在插入、更新和删除操作时需要维护。因此,过多的非聚集索引可能会增加写操作的开销。
了解非聚集索引的特点对于数据库设计和查询优化非常重要。合理地选择和使用非聚集索引可以提高查询性能,但同时也要注意不要过度使用,以免增加写操作的负担和维护成本。
MySql的回表查询是什么?
在MySQL中,“回表查询”(Lookup Query)是指在执行查询时,首先通过非聚集索引(二级索引)定位到数据行的位置,然后再回到数据表中获取完整的数据行的过程。这个过程通常发生在使用覆盖索引无法满足查询需求时,即查询需要的列不完全包含在非聚集索引中。
以下是回表查询的基本步骤:
- 使用非聚集索引:查询首先使用非聚集索引来快速定位到数据行的位置。非聚集索引的叶节点包含了指向数据行的指针。
- 查找数据行:通过非聚集索引找到的指针,查询然后回到数据表中获取完整的数据行。这个步骤被称为"回表",因为查询从索引回到了数据表。
- 获取所需数据:一旦找到了数据行,查询就可以从中获取所需的所有列。
回表查询的效率取决于两个主要因素:文章来源:https://www.toymoban.com/news/detail-847988.html
- 索引的选择:如果非聚集索引能够有效地过滤掉不需要的数据行,那么需要回表的数据行数量就会大大减少,从而提高查询效率。
- 数据页的加载:如果需要回表的数据行位于同一个数据页中,那么这个数据页可能已经被加载到内存中,这样可以减少磁盘I/O操作,提高查询效率。
在某些情况下,可以通过设计合理的索引策略来避免或减少回表查询的需求。例如,如果查询经常需要访问某些列,可以考虑创建一个包含这些列的复合索引,这样就可以使用覆盖索引,避免回表查询。然而,并非所有查询都可以通过覆盖索引来优化,有时候回表查询是不可避免的。在这种情况下,合理地设计和调整索引可以帮助提高回表查询的效率。文章来源地址https://www.toymoban.com/news/detail-847988.html
到了这里,关于MySQL面试题系列-6的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!