实战案例分析
为了更好地理解爬虫逆向的实际应用,我们以一个具体的案例进行分析。
案例背景
假设我们需要从某电商网站上获取商品价格信息,但该网站采取了反爬虫措施,包括动态Token和用户行为分析等。
分析与挑战
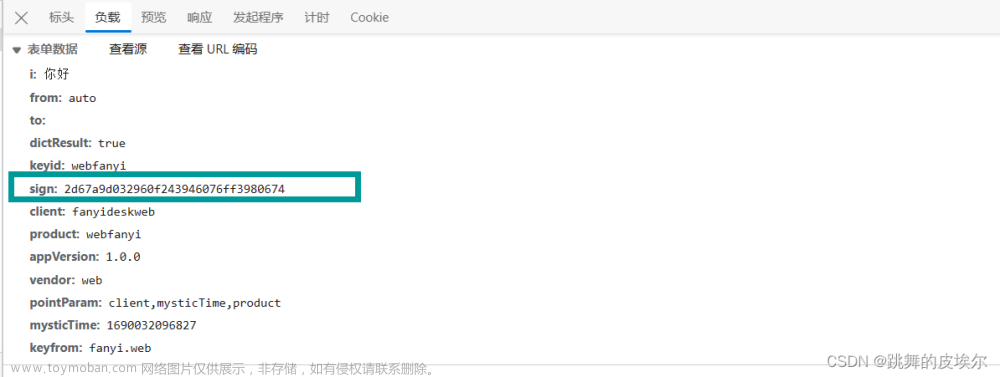
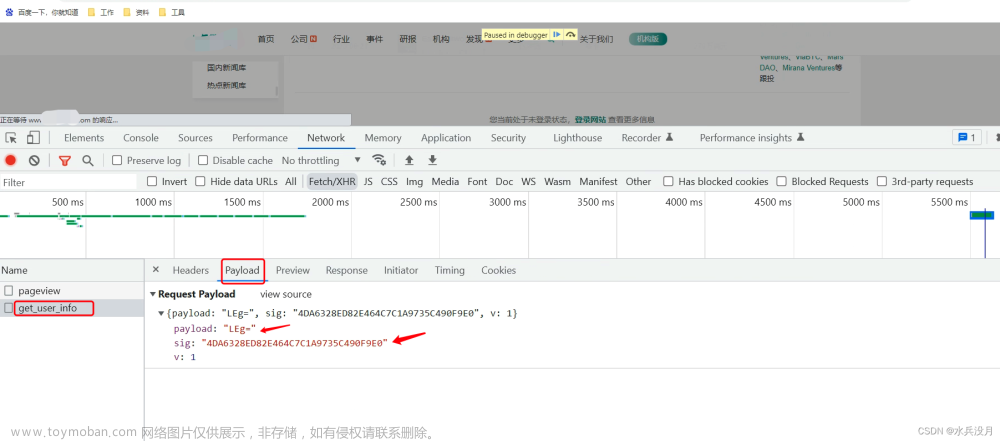
动态Token:该网站在每次请求中都会生成一个动态的Token,用于验证用户身份和请求合法性。这意味着简单地发送请求无法成功获取数据。
用户行为分析:网站可能会监控用户的访问行为,如点击速度、页面停留时间等,来判断是否为爬虫。
解决方案
分析网站加载过程
首先,我们使用浏览器开发者工具分析网站加载过程。我们注意到,在每次访问时,网站都会发送一次预先加载的请求,其中包含了一个动态生成的Token。
// 观察网站加载过程,发现动态Token的生成过程
// 示例代码
识别反爬虫机制
通过分析网站的请求和响应数据,我们发现了动态Token的生成规律,并且观察到了网站对于用户行为的分析。
使用Python的Requests库发送请求并观察响应数据,识别反爬虫机制
示例代码
模拟浏览器请求
借助Python的Requests库,我们模拟了浏览器的请求行为,并在每次请求中正确地携带了生成的动态Token。
import requests
# 请求头中添加用户代理信息
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36'
}
# 发送请求
response = requests.get('https://xxx.com', headers=headers)
# 输出响应内容
print(response.text)
使用Python的Requests库模拟浏览器请求,添加动态Token
示例代码
绕过反爬虫机制
针对验证码的识别,我们可以借助第三方库进行图像识别或者采取人工识别的方式。同时,我们可以调整请求频率和模拟人类的访问行为,来避免被网站识别为爬虫。
import requests
# 从某处获取动态Token,这里假设获取Token的函数为get_dynamic_token()
def get_dynamic_token():
# 实现获取动态Token的逻辑,例如从API接口获取
# 这里只是一个示例,实际情况下可能需要更复杂的逻辑
return "your_dynamic_token"
# 请求头中添加用户代理信息和动态Token
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36',
'Token': get_dynamic_token() # 添加动态Token
}
# 发送请求
response = requests.get('https://example.com', headers=headers)
# 输出响应内容
print(response.text)
使用第三方库或人工识别验证码
import requests
from PIL import Image
import pytesseract
# 定义一个函数来获取验证码图片并识别
def get_and_recognize_captcha():
# 发送请求获取验证码图片
response = requests.get('https://example.com/captcha_image')
# 将响应内容转换为图片对象
captcha_image = Image.open(BytesIO(response.content))
# 使用 pytesseract 库进行验证码识别
captcha_text = pytesseract.image_to_string(captcha_image)
return captcha_text
# 定义函数来发送带验证码的请求
def send_request_with_captcha(captcha_text):
# 构造请求参数
params = {
'captcha': captcha_text,
# 其他请求参数...
}
# 发送带验证码的请求
response = requests.get('https://example.com/protected_resource', params=params)
return response.text
# 主函数
def main():
# 获取并识别验证码
captcha_text = get_and_recognize_captcha()
# 发送带验证码的请求
response_text = send_request_with_captcha(captcha_text)
print(response_text)
if __name__ == "__main__":
main()
调整请求频率和模拟人类访问行为
import requests
import time
from random import randint
# 模拟人类访问行为的函数
def simulate_human_behavior():
# 随机等待一段时间
wait_time = randint(1, 5) # 随机等待1到5秒
time.sleep(wait_time)
# 发送请求的函数
def send_request(url):
# 模拟人类访问行为
simulate_human_behavior()
# 发送请求
response = requests.get(url)
# 如果需要,可以在这里处理响应数据
# ...
return response.text
# 主函数
def main():
# 设置请求的目标URL
url = 'https://example.com'
# 发送多次请求
for i in range(10):
# 发送请求并获取响应
response_text = send_request(url)
# 输出响应内容
print(f"Response {i+1}: {response_text}")
# 可以根据具体情况处理响应数据,例如解析HTML、提取信息等
# ...
if __name__ == "__main__":
main()
成果与反思
通过以上步骤,我们成功地绕过了网站的反爬虫机制,实现了对商品价格信息的抓取。这个案例告诉我们,爬虫逆向需要综合运用多种技术手段,包括对网站加载过程的分析、反爬虫机制的识别和模拟浏览器行为等。同时,需要持续关注和应对网站安全技术的更新和变化,保持学习和创新的态度。
结论
爬虫逆向是一项具有挑战性和技术含量的工作,它为数据采集和分析提供了重要支持。通过本文的探讨,我们了解了爬虫逆向的基本概念、常见反爬虫技术以及解决这些技术的方法。希望本文能够为对爬虫逆向感兴趣的读者提供一些启发和帮助,同时也鼓励大家在实践中不断探索和创新。文章来源:https://www.toymoban.com/news/detail-847995.html
 文章来源地址https://www.toymoban.com/news/detail-847995.html
文章来源地址https://www.toymoban.com/news/detail-847995.html
到了这里,关于爬虫(Web Crawler)逆向技术探索的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!