作者:来自 Elastic Sherry Ger, Stephen Brown
对于许多企业来说,搜索卓越中心(center of excellence - COE)向其用户提供搜索服务,从不同的数据源中整理知识,并将搜索功能集成到其内部和外部应用程序中。Elasticsearch,这个 “支撑着互联网上大约 90% 的搜索栏” 的分布式搜索平台,通常是企业搜索 COE 的首选工具。随着 ChatGPT 的广泛流行,用户发现 LLM(大型语言模型)具有抓住含义的神奇能力。这引发了对企业搜索 COE 提供增强型搜索体验的迫切需求:一种直观、自然、上下文驱动且能轻松识别用户意图的搜索体验。Elasticsearch,最受欢迎的向量数据库,支持规模化的全向量搜索,并与基于转换器的 LLM 原生集成;Elasticsearch 相关性引擎(ESRE)使搜索 COE 能够支持安全、可扩展且高性能的企业级语义搜索。
在这个两部分的博客中,我们将探讨如何使用 Elastic Learned Sparse EncodeR(ELSER)来实现并扩展搜索 COE 的语义搜索服务,ELSER 是 Elastic 训练的一个后交互模型,能够提供开箱即用的语义搜索能力,无需任务特定的微调。我们将在博客的第一部分中探讨在为开发人员提供内部 wiki 文章的语义搜索的用例,实施此过程以及从中获得的经验教训,重点关注以下领域:
- 模型选择 - model selection
- 模式设计 - schem design
- 数据摄入 - data ingestion
- 访问控制 - access control
- 搜索技术 - search techniques
备注:此博客的所有代码和内容都可以在这里找到。
在博客的下一部分中,我们将调查使用 Elastic Search 应用程序向开发人员扩展搜索服务的情况。
模型选择
实现语义搜索的第一个任务是选择一个嵌入模型,该模型应具备以下特点:
- 将文本及其含义转换为数值向量表示
- 适用于你的用例
有许多可选项,包括商业模型如 OpenAI、Cohere 和 Anthropic,以及 HuggingFace 上托管的开源模型,例如 Mistral 7B 或 Llama 2。此外,许多企业拥有自己的数据科学团队,他们已经使用内部数据微调了自己的 LLM 模型。
选择现有的 LLM 用于搜索 COE 的挑战在于该模型可能已经在特定领域的数据集上进行了训练。通常情况下,搜索 COE 必须满足各种各样的用例,并且可能没有数据科学资源来对基础模型进行领域适应。
Elastic Learned Sparse EncodeR(ELSER)是一种检索模型,专为开箱即用用例设计,因此对于优先考虑灵活性、速度和简化实施的搜索 COE 来说,选择它是一个很容易的选择。对于本博客,我们将使用 ELSER 来处理我们的用例,因为我们只处理英文文档,并且可以通过单击在 Elasticsearch 中部署该模型。对于多语言向量搜索,Elasticsearch 提供了类似的一键支持,支持 E5 嵌入模型。
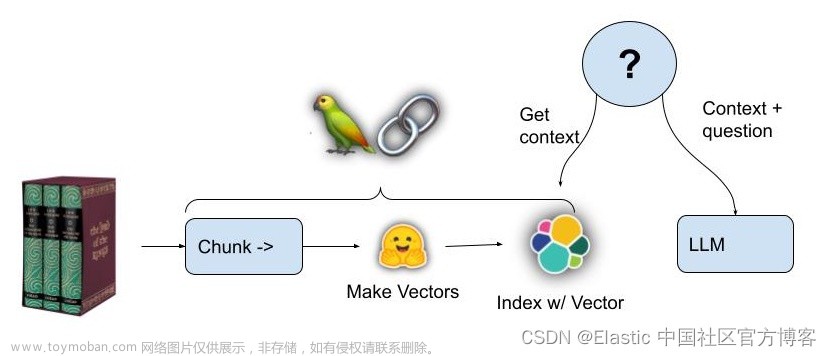
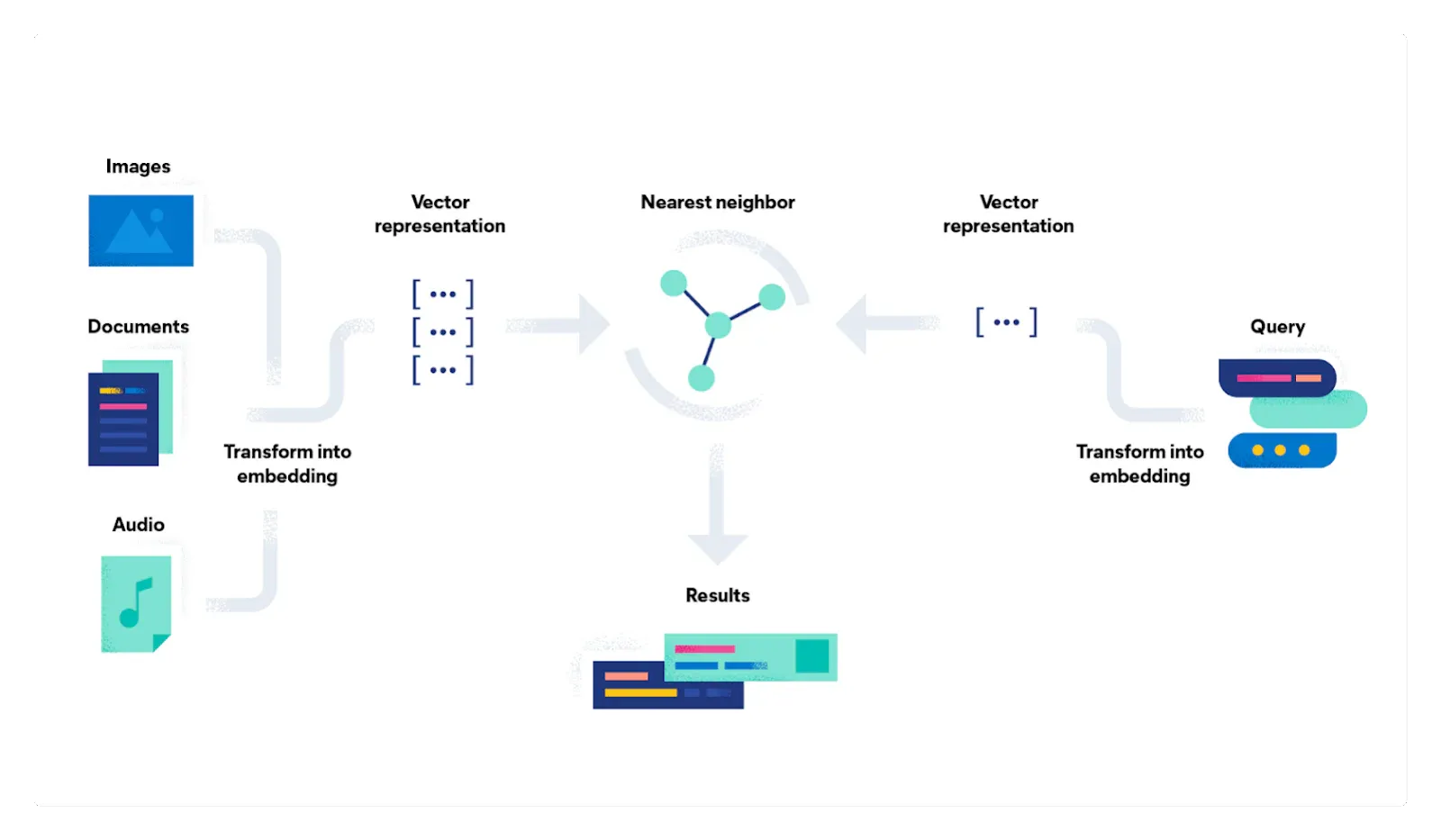
下图描述了向量搜索的基础知识。语义搜索是向量搜索的一个子集,因为我们只关注文本。
模式设计
对于我们的用例来说,一个 “必须具备” 的功能是根据用户查询返回文章中最相关的段落,以及元数据、原始文档的 URL、发布和更新日期以及 wiki 的来源。文档的长度不一,往往超过 ELSER 模型的最大输入令牌限制(512),需要将文本 “分块” 以避免截断。此外,我们可以将文章的元数据与向量嵌入一起存储在 Elasticsearch 中。
与纯向量数据库不同,Elasticsearch 既可以对文本执行传统的 BM25 搜索,也可以原生地过滤和聚合元数据(时间性、数值型、空间性、布尔等)。
这意味着 Elasticsearch 可以在同一个数据存储中以及在单个搜索请求中执行所有这些技术以及执行向量搜索。无需预处理/后处理文本或向量,也无需在应用层或另一个数据存储中关联向量搜索结果。这大大降低了应用复杂性和所需工具的数量。
有了明确的用例需求,我们就可以创建我们的映射了。
PUT dev_wiki_elser
{
"mappings": {
"properties": {
"@timestamp": {
"type": "date"
},
"access": {
"type": "keyword"
},
"created_at": {
"type": "date",
"format": "iso8601"
},
"key_phrases": {
"type": "text"
},
"links": {
"type": "text"
},
"passages": {
"type": "nested",
"properties": {
"is_truncated": {
"type": "boolean"
},
"model_id": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"passage_tokens": {
"type": "sparse_vector"
},
"text": {
"type": "text"
}
}
},
"source": {
"type": "keyword"
},
"summary": {
"type": "text"
},
"updated_at": {
"type": "date",
"format": "iso8601"
}
}
}
}我们将嵌套字段类型用于原始文本块及其使用 ELSER 创建的相应稀疏向量嵌入。 嵌套字段类型是一种特殊类型,其中每个内部文档都作为其自己的文档进行索引,并且其引用与包含文档或父文档一起存储。 使用嵌套字段类型,我们不会为每个文本块复制元数据。 此外,我们不会索引原始文档,因为文档的各个部分在 passage 字段中可用。 另一个细节是 summary 字段包含文章的标题。
使用 Elastic Ingest Pipeline 进行数据摄入
Elasticsearch 的推断处理器允许我们在摄入文档时创建稀疏向量嵌入。脚本处理器将 article_content 分区为少于 512 个项的段落,将文本转换为向量嵌入,并将文本和嵌入都索引到嵌套字段 passages 中。摄入管道是从博客 “通过摄入管道将大型文档分块加上嵌套向量等于简单的段落搜索” 中调整而来,该博客演示了使用摄入推断处理器将文本分块并转换为 LLM 模型中导入 Elasticsearch 的密集向量的过程。在这里,我们使用相同的分块技术通过分隔符来调用 ELSER 创建稀疏向量嵌入。
PUT _ingest/pipeline/elser-v2-dev-wiki2
{
"processors": [
{
"script": {
"description": "Chunk body into sentences by looking for . followed by a space",
"lang": "painless",
"source": """
String[] envSplit = /((?<!M(r|s|rs)\.)(?<=\.) |(?<=\!) |(?<=\?) )/.split(ctx['article_content']);
ctx['passages'] = new ArrayList();
int i = 0;
boolean remaining = true;
if (envSplit.length == 0) {
return
} else if (envSplit.length == 1) {
Map passage = ['text': envSplit[0]];ctx['passages'].add(passage)
} else {
while (remaining) {
Map passage = ['text': envSplit[i++]];
while (i < envSplit.length && passage.text.length() + envSplit[i].length() < params.model_limit) {passage.text = passage.text + ' ' + envSplit[i++]}
if (i == envSplit.length) {remaining = false}
ctx['passages'].add(passage)
}
}
""",
"params": {
"model_limit": 400
}
}
},
{
"foreach": {
"field": "passages",
"processor": {
"inference": {
"model_id": ".elser_model_2_linux-x86_64",
"input_output": [
{
"input_field": "_ingest._value.text",
"output_field": "_ingest._value.passage_tokens"
}
],
"on_failure": [
{
"append": {
"field": "_source._ingest.inference_errors",
"value": [
{
"message": "Processor 'inference' in pipeline 'elser-v2-dev-wiki' failed with message '{{ _ingest.on_failure_message }}'",
"pipeline": "elser-v2-dev-wiki",
"timestamp": "{{{ _ingest.timestamp }}}"
}
]
}
}
]
}
}
}
},
{
"remove": {
"field": [
"article_content"
]
}
}
]
}作为管道的一部分,我们从索引中删除了article_content,因为内容在 passages 字段的分块中已经可用。
这里使用的分块技术,通过句尾标点创建 passages,是一种基本技术。有关使用各种方法进行分块的详细信息和代码,请参阅用于语义搜索的 token 计算。此外,Elasticsearch 中的原生分块功能即将推出。
对于这篇博客,我们将使用管道摄入 4 个公开的样本文档。这些文档是关于配置流量过滤的 Elastic Cloud 指南。其中一个文档具有 "access": "private"。
POST dev_wiki_elser/_doc?pipeline=elser-v2-dev-wiki
{
"summary": "IP traffic filters",
"access": "private",
"@timestamp": "2023-08-07T08:15:12.590363000Z",
"key_phrases": """- Traffic filtering\\n- IP address \\n- CIDR block \\n- Egress IP filters \\n- Ingress IP filters\\n- Inbound IP filters\\n- Outbound IP filters\\n- IPv4 \\n- VPC Endpoint Gateway \\n- VPC Endpoint Interface \""",
"updated_at": "2023-08-07T08:15:14.756374+00:00",
"created_at": "2023-08-03T19:54:31.260012+00:00",
"links": [
"https://www.elastic.co/guide/en/cloud/current/ec-traffic-filtering-ip.html"
],
"source": "CLOUD_INFRASTRACTURE_DOCUMENT",
"article_content": """Traffic filtering, by IP address or CIDR block, is one of the security layers available in Elasticsearch Service. It allows you to limit how your deployments can be
…
Select the Delete icon. The icon is inactive if there are deployments assigned to the rule set.
"""
}其他三个具有 “access”: “public” 属性。 以下是有关配置 AWS Privatelink 流量过滤器的文章。
POST dev_wiki_elser/_doc?pipeline=elser-v2-dev-wiki
{
"summary": "AWS PrivateLink traffic filter",
"access": "public",
"@timestamp": "2023-08-07T08:15:12.590363000Z",
"key_phrases": "- AWS\\\\n- PrivateLink \\\\n- VPC \\\\n- VPC Endpoint \\\\n- VPC Endpoint Service \\\\n- VPC Endpoint Policy \\\\n- VPC Endpoint Connection \\\\n- VPC Endpoint Interface \\\\n- VPC Endpoint Gateway \\\\n- VPC Endpoint Interface \\",
"updated_at": "2023-08-07T08:15:14.756374+00:00",
"created_at": "2023-08-03T19:54:31.260012+00:00",
"links": [
"https://www.elastic.co/guide/en/cloud/current/ec-traffic-filtering-vpc.html"
],
"source": "CLOUD_INFRASTRACTURE_DOCUMENT",
"article_content": """Traffic filtering, to only AWS PrivateLink
…
On the Security page, under Traffic filters select Remove."""
}另外两个文档非常相似,一个是关于 Azure Private Link 流量过滤器的,另一个是关于 GCP Private Service Connect 流量过滤器的。
访问控制
Elasticsearch 支持基于角色的访问控制,包括原生支持字段和文档级别的访问控制;这大大减少了保护应用程序所需的操作和维护复杂性。在我们的开发者 wiki 用例中,我们可以根据 access 字段值限制对文档的访问。例如,标记为 private 的文档不应对属于public_documents 用户角色的用户可访问,即具有属性access: private 的文档对于拥有 public_documents 角色的用户而言是不存在的。除了限制拥有 public_documents 用户角色的用户对文档的访问外,我们还可以移除对 access 字段的可见性。
注意:通过 REST API PUT 角色的代码包含在 gist 中。

用户 sherry 具有 public_documents 角色。 对于该用户,对索引进行简单计数将仅返回 3 个具有 "access": "public" 属性的文档。
curl -u sherry:my_password -XGET https://my-cluster.aws.elastic-cloud.com/dev_wiki_elser/_count/?pretty响应:
{
"count" : 3,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
}
}此外,查看索引映射的调用将仅返回用户被授权的字段。
curl -u sherry:my_password -XGET https://my-cluster.aws.elastic-cloud.com/dev_wiki_elser/_mapping/?pretty
{
"dev_wiki_elser" : {
"mappings" : {
"properties" : {
"@timestamp" : {
"type" : "date"
},
"created_at" : {
"type" : "date",
"format" : "iso8601"
},
"key_phrases" : {
"type" : "text"
},
"links" : {
"type" : "text"
},
"passages" : {
"type" : "nested",
"properties" : {
"passage_tokens" : {
"type" : "sparse_vector"
},
"text" : {
"type" : "text"
}
}
},
"source" : {
"type" : "keyword"
},
"summary" : {
"type" : "text"
},
"updated_at" : {
"type" : "date",
"format" : "iso8601"
}
}
}
}
}有了这种基于角色的访问控制(role-based control access - RBAC),拥有 public_documents 角色的用户将只能搜索和访问他们有权限的文档和字段。这是一个简单但强大的例子,展示了如何在 Elasticsearch 中本地轻松地保护数据和内容。此外,Elasticsearch 完全支持其他企业级认证/授权框架,如 SAML、LDAP、Active Directory 等,因此利用这些框架来控制对数据的访问只是简单的配置问题。
搜索技术
现在,我们准备转向语义搜索。请注意,搜索相关性调优是一个迭代过程,可能需要我们回头使用不同于我们已采用的模型和/或修改索引模式。
此外,向我们的语义搜索查询中添加元数据过滤可以提高相关性。同时,结合使用不同的搜索算法也是优化结果的另一个选项,比如将 BM25 与 ELSER 一起使用,使用倒数排名融合(RRF)进行混合搜索,使用密集向量与 ELSER 以及它们的某些组合。Elasticsearch 原生支持所有这些功能。
我们用例的语料库,开发者 wiki 文档,倾向于包含非常相似的主题和术语。以下查询仅使用 ELSER 向量嵌入检索关于配置过滤规则集,以连接 Google Private Service Connect 到 Elastic Cloud 部署的最相关段落。我们已将 "_source" 设置为 "false",因为我们只需要输出 summary 或 title、URL 和文章的相关部分。为了清晰起见,我们跳过了日期。
GET dev_wiki_elser/_search
{
"_source": "false",
"fields": [
"summary",
"links"
],
"query": {
"nested": {
"path": "passages",
"score_mode": "max",
"query": {
"text_expansion": {
"passages.passage_tokens": {
"model_id": ".elser_model_2_linux-x86_64",
"model_text": "How to configure traffic filter rule set private link google"
}
}
},
"inner_hits": {
"size": 1,
"_source": false,
"fields": [
"passages.text"
]
}
}
}
}不幸的是,返回的第一篇文章是关于如何为 AWS 配置流量过滤器集,而不是 Google Cloud 的文章。这并不令人惊讶,因为 “private link” 是一个描述 VPCs 之间安全链接的常用词汇,最初由亚马逊网络服务(AWS)使用,就像 Kleenex 之于面巾纸一样;尽管其在 Google Cloud Platform 中的等效物被称为私有连接服务,但它被用户广泛采用。
{
"took": 19,
"timed_out": false,
"_shards": {
…
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": 20.017376,
"hits": [
{
"_index": "dev_wiki_elser",
"_id": "UGxiOY0Bds674Ci9z6yW",
"_score": 20.017376,
"_source": {},
"fields": {
"summary": [
"AWS PrivateLink traffic filter"
],,
"links": ["https://www.elastic.co/guide/en/cloud/current/ec-traffic-filtering-vpc.html"]
},
"inner_hits": {
"passages": {
"hits": {
"total": {
"value": 24,
"relation": "eq"
},
"max_score": 20.017376,
"hits": [
{
"_index": "dev_wiki_elser",
"_id": "UGxiOY0Bds674Ci9z6yW",
"_nested": {
"field": "passages",
"offset": 17
},
"_score": 20.017376,
"fields": {
"passages": [
{
"text": [
"""Or, select Dedicated deployments to go to the deployments page to view all of your deployments.
Under the Features tab, open the Traffic filters page.
Select Create filter.
Select Private link endpoint.
...这就是我们映射中的 key_phrases 字段发挥作用的地方。在我们的用例中,文章附有关键词和短语,这为将语义搜索与传统的 BM25 搜索相结合提供了一个绝佳的方式。
通常,内容并没有关键词/短语,但这可以通过使用 LLM 来执行关键词提取轻松解决,这样可以提炼出文章的精华。这可以通过使用公共的 LLM,如 OpenAI 或 Gemini,或者使用本地托管的 LLM,如 Mistral 7 或 llama2 来实现。请在下一篇博客中留意这一点。
将我们原始的文本扩展搜索和对 key_phrases 字段的 match 查询包裹在一个 bool 查询中,确保如预期返回正确的文档。
GET dev_wiki_elser/_search
{
"_source": "false",
"fields": [
"summary",
"links"
],
"query": {
"bool": {
"should": [
{
"nested": {
"path": "passages",
"score_mode": "max",
"query": {
"text_expansion": {
"passages.passage_tokens": {
"model_id": ".elser_model_2_linux-x86_64",
"model_text": "How to configure traffic filter rule set private link google"
}
}
},
"inner_hits": {
"size": 1,
"_source": false,
"fields": [
"passages.text"
]
}
}
},
{
"match": {
"key_phrases": "How to configure traffic filter rule set private link google"
}
}
]
}
}
}查询的响应正确标识了相关文章。
{
"took": 22,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": 22.327188,
"hits": [
{
"_index": "dev_wiki_elser",
"_id": "UmxjOY0Bds674Ci9Dqzy",
"_score": 22.327188,
"_source": {},
"fields": {
"summary": [
"Google Private Service Connect"
],
"links": [
"https://www.elastic.co/guide/en/cloud/current/ec-traffic-filtering-psc.html"
]
},
"inner_hits": {
"passages": {
"hits": {
"total": {
"value": 22,
"relation": "eq"
},
"max_score": 19.884687,
"hits": [
{
"_index": "dev_wiki_elser",
"_id": "UmxjOY0Bds674Ci9Dqzy",
"_nested": {
"field": "passages",
"offset": 16
},
"_score": 19.884687,
"fields": {
"passages": [
{
"text": [
"""Add the Private Service Connect rules to your deployments
…我们针对该用例尝试的另一种技术是具有倒数排名融合的混合搜索。 对于我们的用例,该方法不如带有文本扩展和 BM25 的简单布尔查询有效。 此外,由于我们使用的分块技术,尽管相关性很好,但响应段落通常从段落的中间开始。 我们能够美化应用层的响应。
总结
在这篇博客中,我们探索了在企业卓越中心实施语义搜索的过程。
- 模型选择:ELSER 是一个为开箱即用用例设计的检索模型,这使得它成为寻求灵活性、速度和流线型实施的搜索中心的简单选择。
- 模式设计:与纯向量数据库不同,Elasticsearch 同样可以执行传统的 BM25 搜索,并且能够在同一上下文数据库和查询中原生地过滤和聚合元数据以及向量搜索。其结果是能够显著简化应用复杂性和相比于纯向量数据库所需的工具数量。使用嵌套字段类型来存储原始文本的块及其对应的由 ELSER 创建的稀疏向量嵌入,是一种存储和搜索数据的高效方式。
- 数据摄入:Elasticsearch 推理处理器允许我们在摄入文档时 “分块” 并创建稀疏向量嵌入。这一切都可以在 Elasticsearch 内完成,无需额外的工具和预处理。Elasticsearch 即将推出原生分块功能。
- 访问控制:Elasticsearch 拥有强大的原生 RBAC 控制,以限制/控制访问,包括字段和文档级别的访问控制,这大大减少了保护数据和应用所需的操作和维护复杂性。
- 搜索技术:语义搜索是一个迭代过程,可能需要调整或结合多种搜索技术来产生最相关的结果。在这个案例中,我们发现纯粹的语义文本扩展搜索没有提供最佳的相关性。因此,我们结合了语义搜索和传统的 BM25 搜索对关键短语进行过滤,以提供最佳结果。还有其他技术,如倒数排序融合可以使用,尽管在这个用例中它们没有提供更好的结果。
提醒一下,这篇博客的所有代码和内容都可以在这里找到。
其他注意事项
我们忽略的一件事是如何以可扩展和系统的方式评估搜索相关性。 对于我们的用例,我们有一个测试数据集、查询和预期结果来定量测量 “什么是好的”。 我们强烈建议你查看通过数据驱动的查询优化提高搜索相关性,以获得可靠的方法。
此外,调整我们的用例的语义搜索相关性是一个迭代过程。 对于许多搜索 COE 来说,快速启动、调整路线并在需要时采用不同的技术是有意义的。 LLMs 是我们工具集中一个极其灵活的工具,可以为我们的用户提供更高级别的搜索体验。
下一个博客
在本博客的下一部分中,我们将了解如何以优化且简单的方式向开发人员公开我们的 Elasticsearch 查询,使他们能够快速将搜索功能合并到应用程序中。 作为其中的一部分,我们将提供关键字提取的示例,这可以提高搜索性能。文章来源:https://www.toymoban.com/news/detail-848047.html
原文:https://www.elastic.co/search-labs/blog/semantic-search-as-service-at-a-search-center-of-excellence文章来源地址https://www.toymoban.com/news/detail-848047.html
到了这里,关于Elasticsearch:语义搜索即服务处于卓越搜索的中心的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!