首先我们来看一下之前是如何书写页面模式中的类的:
BasePage:
class BasePage(object):
"""description of class"""
#webdriver instance
def __init__(self, driver):
self.driver = driver
GoogleMainPage:
from BasePage import BasePage
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
class GoogleMainPage(BasePage):
"""description of class"""
searchbox = (By.ID,'lst-ib')
def inputSearchContent(self,searchContent):
searchBox = self.driver.find_element(*self.searchbox)
searchBox.send_keys(searchContent+Keys.RETURN)
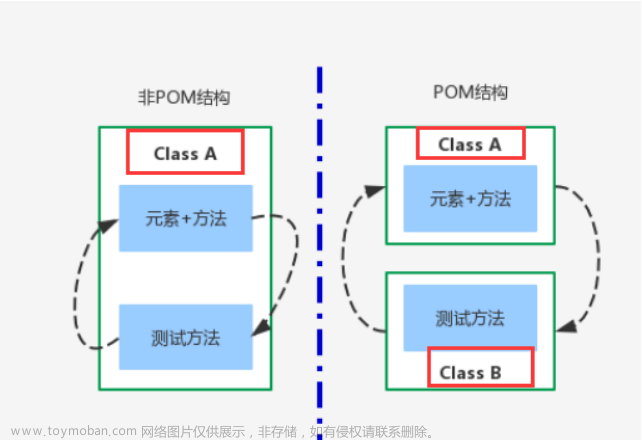
重新审视之前的实现,我们可以发现在各个子类页面中,均需要引用相当的selenium类库(比如webdriver),并且需要用webdriver来定位页面元素,这就会造成各个子类页面与selenium类库有较多的集成,并且也是书写上的浪费。
现在来看一下做了结构调整的部分呈现:
BasePage:
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
from selenium.common.exceptions import StaleElementReferenceException
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
class BasePage(object):
"""description of class"""
#webdriver instance
def __init__(self, browser='chrome'):
'''
initialize selenium webdriver, use chrome as default webdriver
'''
if browser == "firefox" or browser == "ff":
driver = webdriver.Firefox()
elif browser == "chrome":
driver = webdriver.Chrome()
elif browser == "internet explorer" or browser == "ie":
driver = webdriver.Ie()
elif browser == "opera":
driver = webdriver.Opera()
elif browser == "phantomjs":
driver = webdriver.PhantomJS()
try:
self.driver = driver
except Exception:
raise NameError("Not found %s browser,You can enter 'ie', 'ff' or 'chrome'." % browser)
def findElement(self,element):
'''
Find element
element is a set with format (identifier type, value), e.g. ('id','username')
Usage:
self.findElement(element)
'''
try:
type = element[0]
value = element[1]
if type == "id" or type == "ID" or type=="Id":
elem = self.driver.find_element_by_id(value)
elif type == "name" or type == "NAME" or type=="Name":
elem = self.driver.find_element_by_name(value)
elif type == "class" or type == "CLASS" or type=="Class":
elem = self.driver.find_element_by_class_name(value)
elif type == "link_text" or type == "LINK_TEXT" or type=="Link_text":
elem = self.driver.find_element_by_link_text(value)
elif type == "xpath" or type == "XPATH" or type=="Xpath":
elem = self.driver.find_element_by_xpath(value)
elif type == "css" or type == "CSS" or type=="Css":
elem = self.driver.find_element_by_css_selector(value)
else:
raise NameError("Please correct the type in function parameter")
except Exception:
raise ValueError("No such element found"+ str(element))
return elem
def findElements(self,element):
'''
Find elements
element is a set with format (identifier type, value), e.g. ('id','username')
Usage:
self.findElements(element)
'''
try:
type = element[0]
value = element[1]
if type == "id" or type == "ID" or type=="Id":
elem = self.driver.find_elements_by_id(value)
elif type == "name" or type == "NAME" or type=="Name":
elem = self.driver.find_elements_by_name(value)
elif type == "class" or type == "CLASS" or type=="Class":
elem = self.driver.find_elements_by_class_name(value)
elif type == "link_text" or type == "LINK_TEXT" or type=="Link_text":
elem = self.driver.find_elements_by_link_text(value)
elif type == "xpath" or type == "XPATH" or type=="Xpath":
elem = self.driver.find_elements_by_xpath(value)
elif type == "css" or type == "CSS" or type=="Css":
elem = self.driver.find_elements_by_css_selector(value)
else:
raise NameError("Please correct the type in function parameter")
except Exception:
raise ValueError("No such element found"+ str(element))
return elem
def open(self,url):
'''
Open web url
Usage:
self.open(url)
'''
if url != "":
self.driver.get(url)
else:
raise ValueError("please provide a base url")
def type(self,element,text):
'''
Operation input box.
Usage:
self.type(element,text)
'''
element.send_keys(text)
def enter(self,element):
'''
Keyboard: hit return
Usage:
self.enter(element)
'''
element.send_keys(Keys.RETURN)
def click(self,element):
'''
Click page element, like button, image, link, etc.
'''
element.click()
def quit(self):
'''
Quit webdriver
'''
self.driver.quit()
def getAttribute(self, element, attribute):
'''
Get element attribute
'''
return element.get_attribute(attribute)
def getText(self, element):
'''
Get text of a web element
'''
return element.text
def getTitle(self):
'''
Get window title
'''
return self.driver.title
def getCurrentUrl(self):
'''
Get current url
'''
return self.driver.current_url
def getScreenshot(self,targetpath):
'''
Get current screenshot and save it to target path
'''
self.driver.get_screenshot_as_file(targetpath)
def maximizeWindow(self):
'''
Maximize current browser window
'''
self.driver.maximize_window()
def back(self):
'''
Goes one step backward in the browser history.
'''
self.driver.back()
def forward(self):
"""
Goes one step forward in the browser history.
"""
self.driver.forward()
def getWindowSize(self):
"""
Gets the width and height of the current window.
"""
return self.driver.get_window_size()
def refresh(self):
'''
Refresh current page
'''
self.driver.refresh()
self.driver.switch_to()
GoogleMainPage:
from BasePage import BasePage
class GoogleMainPage(BasePage):
"""description of class"""
searchbox = ('ID','lst-ib')
def __init__(self, browser = 'chrome'):
super().__init__(browser)
def inputSearchContent(self,searchContent):
searchBox = self.findElement(self.searchbox)
self.type(searchBox,searchContent)
self.enter(searchBox)
Test
所做的改变:
- 将与Selenium类库相关的操作做二次封装,放在BasePage中,其他子类页面自动继承相应的操作方法(如findelement,click等等)
- 封装了findelement方法,可以根据页面元素的(类型,值)进行查找,只需要调用一个方法findelement(s),而不需要针对不同的类型调用不同的find方法(fine_element_by_xxxx())
- 子类页面不需要引用selenium的类库,书写更加简单易读
- 测试用例中也不需要引用selenium的任何类库,简单易读
现在我也找了很多测试的朋友,做了一个分享技术的交流群,共享了很多我们收集的技术文档和视频教程。
如果你不想再体验自学时找不到资源,没人解答问题,坚持几天便放弃的感受
可以加入我们一起交流。而且还有很多在自动化,性能,安全,测试开发等等方面有一定建树的技术大牛
分享他们的经验,还会分享很多直播讲座和技术沙龙
可以免费学习!划重点!开源的!!!
qq群号:485187702【暗号:csdn11】最后感谢每一个认真阅读我文章的人,看着粉丝一路的上涨和关注,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走! 希望能帮助到你!【100%无套路免费领取】
 文章来源:https://www.toymoban.com/news/detail-848312.html
文章来源:https://www.toymoban.com/news/detail-848312.html
 文章来源地址https://www.toymoban.com/news/detail-848312.html
文章来源地址https://www.toymoban.com/news/detail-848312.html
到了这里,关于基于Selenium的Web自动化框架的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!