前言
OpenAI 大模型提供了一些强大的 API,方便用户与 OpenAI 的大语言模型进行交互。除了上篇中讲到的Embeddings中需要用到的embeddings接口,其核心接口主要是Completions 和Chat Completions接口。
一、OpenAI 大模型接口列表
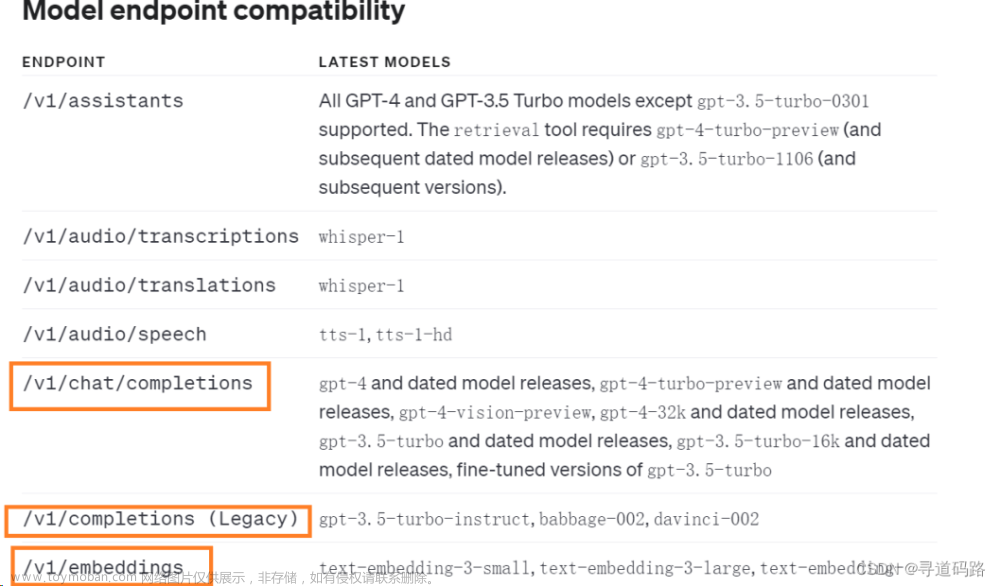
二、Completions(文本自动补全类模型API)
自动文本补全、用于生成各类文本任务的模型,可以根据给定的提示(prompt)自动生成和补全文本,如撰写文章
Completions API:
1、 接口:/v1/completions (已淘汰)
2、 模型:gpt-3.5-turbo-instruct, babbage-002, davinci-002
3、 参数:model(模型名称)、prompt(提示词)、max_tokens(响应的tokens阀值)、temperature(温度值0-2,严谨度从高到低)
4、功能:这个 API 接口能够通过预测接下来的文本来生成新的文本。你只需提供一个提示(prompt),模型就会生成一个与提示相关的文本序列。这对于创作文章、歌词、故事或者生成电子邮件回复等任务来说非常有用。
三、Chat Completions(对话聊天类模型API)
ChatCompletions属于Completions的升级版本,专用为对话和聊天场景设计的模型;它通过大量高质量对话文本进行微调,从而更好地理解和生成对话内容
Chat Completions API:(推荐)
1、接口:/v1/chat/completions
2、模型:gpt-4 and dated model releases, gpt-4-turbo-preview and dated model releases, gpt-4-vision-preview, gpt-4-32k and dated model releases, gpt-3.5-turbo and dated model releases, gpt-3.5-turbo-16k and dated model releases, fine-tuned versions of gpt-3.5-turbo
3、参数:model、message(user/system/assistant )、max_tokens、function、function_call 等
message中的参数说明
① user:设置用户提示问题
② system:设置系统模型背景(设置角色/设置知识库/设置样例)
③ assistant :设置模型助手返回样例;可以针对第一个user提示词,设置返回的结果样例
4、功能:这个 API 接口允许你构造一个多轮的聊天会话。你可以提供一系列的消息,每一条消息都有一个角色(role)和内容(content)。角色可以是 system、user 或 assistant,这使得模型可以在多个角色之间进行上下文理解和切换,生成相应的回复。
四、接口开发实践
1.简单使用样例
import os
from openai import OpenAI
client = OpenAI(
api_key=os.environ['OPENAI_API_KEY'], # this is also the default, it can be omitted
)
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "user", "content": "请问,什么是AI大模型?"}
]
)
# 输出response
ChatCompletion(id='chatcmpl-9AXF9T4lURXaU2S4ElFycQpeDHiDQ', choices=[Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content='AI大模型是指具有庞大参数数量和复杂结构的人工智能模型。这些模型通常通过深度学习技术训练,并在各种任务中取得了良好的性能表现。AI大模型的例子包括大规模神经网络如BERT、GPT等。这些模型通常需要大量的计算资源和数据来训练,并在自然语言处理、计算机视觉、语音识别等领域中得到广泛应用。', role='assistant', function_call=None, tool_calls=None))], created=1712298095, model='gpt-3.5-turbo-0125', object='chat.completion', system_fingerprint='fp_b28b39ffa8', usage=CompletionUsage(completion_tokens=145, prompt_tokens=19, total_tokens=164))
# 输出结果中content
response.choices[0].message.content
'OpenAI是一家非营利人工智能研究实验室,旨在推动人工智能技术的发展,并确保人工智能对人类的利益产生积极影响。OpenAI致力于开发开源的人工智能技术,以促进人工智能领域的创新和发展。该实验室的研究重点包括深度学习、强化学习、自然语言处理、计算机视觉等领域。对于AI行业来说,OpenAI是一个具有推动作用的领先机构,旨在通过共享研究成果和开源技术,促进全球范围内的合作与创新。'
2.身份角色设定
通过Message中的system提前设置大模型的角色身份,让他回答更加专业严谨。
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "你是一名AI大模型资深专家"},
{"role": "user", "content": "请问什么是AI大模型?"}
]
)
# 输出结果
response.choices[0].message.content
'AI大模型通常指的是参数数量庞大、参数规模庞大的人工智能模型,常常包括数百万到数十亿个参数。这些模型通常经过深度学习训练,能够在多个领域展现出强大的性能,比如自然语言处理、计算机视觉、语音识别等。由于参数规模巨大,这些模型需要庞大的计算资源和数据来进行训练,且通常需要运行在多个GPU或者TPU等高性能计算设备上才能发挥其潜力。近年来,随着计算能力的提升和算法的改进,AI大模型的应用范围也在不断扩大。'
3.添加聊天背景
借助system role设置聊天背景信息,实现类似根据本地知识库回答问题的方法
text = '冬瓜老师,男,1988年9月16日出生于广东省深圳市 \
2011年毕业于深圳大学计算机专业。\
毕业后进入ABC科技公司工作了6年,专注于AI方面的研究,'
#%%
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": text},
{"role": "user", "content": '请问冬瓜老师出生于哪儿?'}
]
)
# 输出结果
response.choices[0].message.content
'冬瓜老师出生于广东省深圳市。'
4.实现文本补全
围绕system的prompt进行进一步的文本补全;当messages中只包含一条system消息时,系统会围绕system进行回答
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "你是一名的脱口秀演员"},
]
)
# 输出结果
response.choices[0].message.content
'嗨!大家好,我是今天的主持人。感谢大家的到场,让我来为大家带来一些欢乐和笑声。今天有没有什么话题是你们特别想要聊的呢?放心,我会为大家带来最新最有趣的段子和笑话。废话不多说,让我们开始今天的表演吧!希望大家尽情享受!'
5.少量样本提示
利用message参数中的assistant,为大模型添加回答的模板样例
Q1 = '小米有6个气球,她又买了3袋,每袋有10个气球,请问她现在总共有多少个气球?'
A1 = '现在小米总共有36个气球。'
Q2 = '小明总共有10个苹果,吃了3个苹果,然后又买了5个苹果,请问现在小明总共有多少个苹果?'
A2 = '现在小明总共有12个苹果。'
#%%
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "user", "content": Q1},
{"role": "assistant", "content": A1},
{"role": "user", "content": Q2}
]
)
# 输出结果
response.choices[0].message.content
'现在小明总共有12个苹果。'
## 可以把提示示例写进一条system信息中,作为当前问答的背景信息
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": '问题: ' + Q1 + '答案: ' + A1},
{"role": "user", "content": '问题: ' + Q2 }
]
)
# 输出结果
response.choices[0].message.content
'现在小明总共有12个苹果。'
5.提高分析能力
借助system消息能够作为背景知识的设定,能够对后续的问答消息造成影响;通过它提高大模型思维分析能力
prompt_temp_cot = '请一步步思考并解决问题'
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": prompt_temp_cot},
{"role": "user", "content": Q1}
]
)
# 输出结果
response.choices[0].message.content
'首先,小米原本有6个气球,然后买了3袋气球,每袋有10个。所以现在她有:\n6 + 3 * 10 = 6 + 30 = 36 个气球\n\n所以,小米现在总共有36个气球。'
总结
本章主要介绍ChatCompletions API的特点,以及各种使用样例;下一章节将记录说明怎么基于Chat Completions API和本地知识库实现一个简单的多轮对话机器人。文章来源:https://www.toymoban.com/news/detail-848465.html
探索未知,分享所知;点击关注,码路同行,寻道人生!文章来源地址https://www.toymoban.com/news/detail-848465.html
到了这里,关于AI大模型探索之路-基础篇2:掌握Chat Completions API的基础与应用的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!













