实验目的
通过实验熟悉Wireshark 抓包软件的使用方法,理解有关 HTTP 协议的各方面内容。
实验内容
1. 在windows 环境进行Wireshark 抓包。
2. 理解基本GET/response 交互,HTTP 数据包的格式。
3. 获取较长的HTML 文件,分析其数据包。
4. 获取有嵌入对象的HTML 文件,分析器数据包。
实验步骤
6. 基本HTTP 的GET/response 交互
1) 打开网页浏览器;实验前清空浏览器缓存,工具-Internet选项-浏览历史记录-删除
2)打开 Wireshark。本次试验中,我们只关注 HTTP 协议,不希望在抓包窗口中看到其他协议的数据包,因此在“display-filter-specification”窗口中输入“ ip.src==82.157.139.98 or ip.dst==82.157.139.98 and http” ,这样只有 HTTP 数据包会在 packet-listing 窗口中显示;
3) 稍等片刻,然后开始Wireshark 抓包;
4) 在浏览器地址栏中输入以下 URL,http:// 82.157.139.98 /test/test1.php你将在浏
览器中看到一个只有两行文字的 html 文件;
5) 停止Wireshark 抓包。输入合适的过滤条件,此时Wireshark 窗口会出现类似如下的窗口:
回答问题:
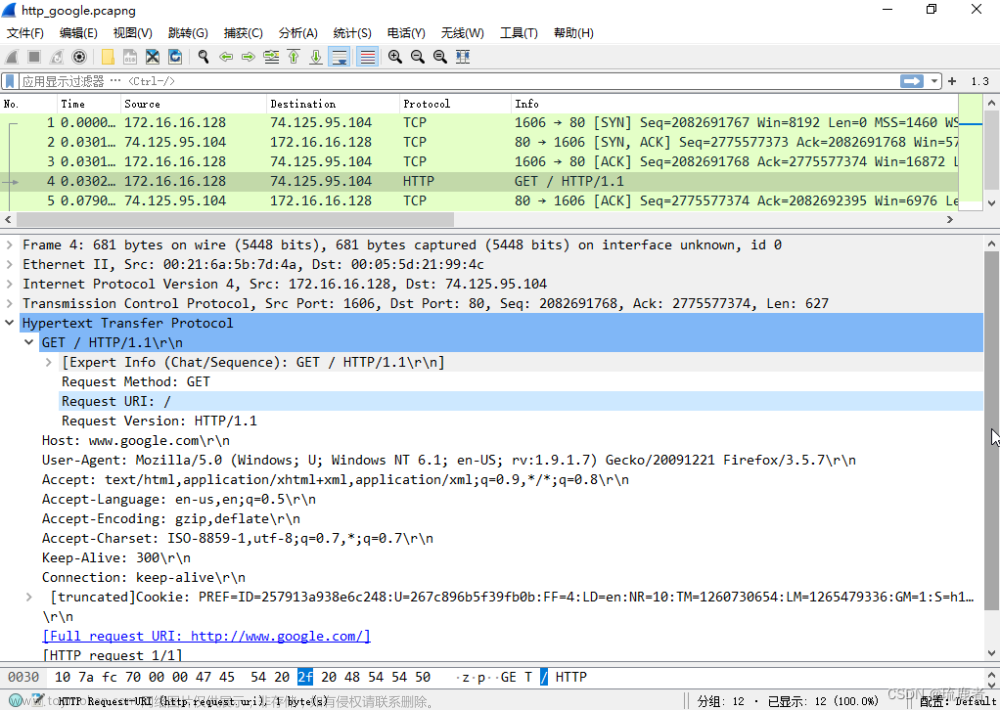
(1) 你的浏览器所运行的是 http 协议的 1.0 版本还是 1.1?服务器用的是什么版本的 http 协议?
答:浏览器用的是HTTP1.1

服务器用的是HTTP1.1

(2) 你的浏览器可以支持多少种语言(如果有)?
支持zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6,4种语言

(3) 你自己的IP 地址是多少?服务器呢?
答:自己的ip地址是:10.149.1.147
服务器的ip地址是:82.157.139.98

(4) 从服务器传回浏览器的状态代码是什么?
答:是HTTP/1.1 200 OK\r\n

(5) 你所看到的html 文件在服务器上最后的修改时间是什么?
答:是Fri, 02 Dec 2022 06:20:05 GMT

(6) 传回浏览器的内容的大小是多少 bytes?
答:是436字节

7. 有条件的HTTP 的GET/response 交互
1) 打开浏览器清空浏览器缓存。(以IE 浏览器为例,打开菜单栏中的工具->Internet
选项,选择删除文件)。
1) 打开Wireshark,开始抓包;
2) 在浏览器地址栏中输入以下 URL,http://82.157.139.98/test/test2.php在浏览器中,将会显示一个简单的具有 7行文字的html 文件。
3) 快速地再次输入上述URL,或者点击浏览器工具栏上的“ 刷新” 按钮;
4) 停止Wireshark 抓包,在“ display-filter-specification” 窗口中输入“ http” 以及其它必要过滤条件。
回答问题:
(1) 在packet-content 窗口中观察第一个从浏览器向服务器发出的http GET 请求的数据包,是否看到一行显示“ IF-MODIFIED-SINCE” ?
答:没有,因为这是浏览器第一次请求该页面,所以没有“IF-MODIFIED-SINCE”。
(2) 观察从服务器传回的 response 数据包,服务器是否很清楚的传回了该 html 文件的内容?你如何知道的?
答:服务器很清楚的传回了该 html 文件的内容,因为返回的状态码是200 OK,而且可以在Line-based text data中看到返回的html文件


(3) 观察第二个从浏览器向服务器发出的 http GET 请求的数据包,是否看到一行显示
“ IF-MODIFIED-SINCE” ?如果有,在“ IF-MODIFIED-SINCE” 报头后显示的是什么?
答:有,后面的信息是Fri, 02 Dec 2022 06:40:38 GMT\r\n,是上一次请求的信息

(4) 从服务器传回的对第二个 http GET 的response 的状态代码是什么?服务器是否很
清楚的传回了该html 文件的内容?你如何知道的?
答:状态码是200,短语是ok
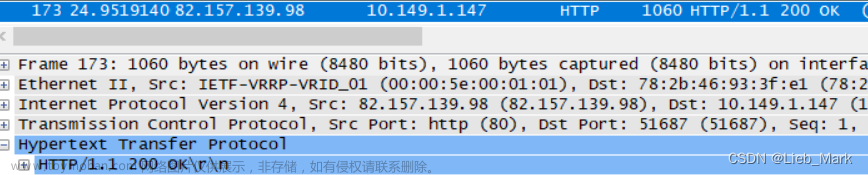
传回了html文件,在Line-based text data中可以看到返回的html文件

8. 获取较长的 HTML 文件
1) 打开你的浏览器,确认浏览器的缓冲器已经被清空;
2) 打开Wireshark,开始抓包;
3) 在浏览器地址栏中输入以下 URL,http://82.157.139.98/test/test3.php在浏览器中将会显示一个介绍海大的html文件。
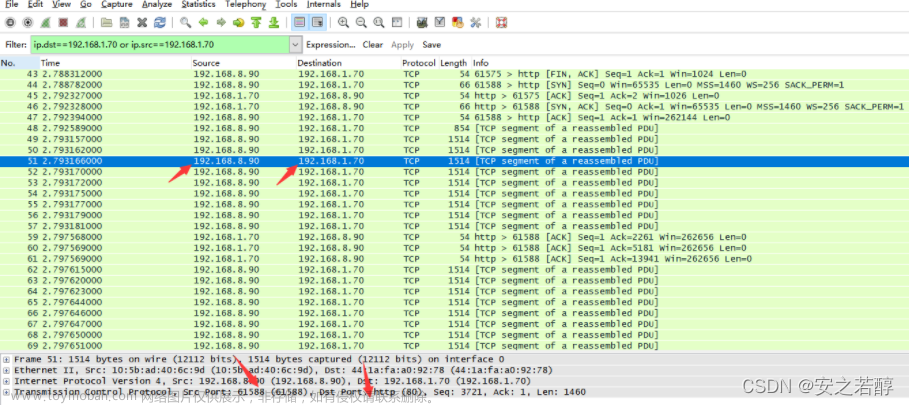
4) 停止Wireshark 抓包,在“ display-filter-specification” 窗口中输入“ tcp and http” 。在packet-listing-window 中,你会看到向服务器发出的 http GET 数据包,在其后有多种针对 GET 的response 数据包。http 的response数据包包含一个状态行,其后有报头行,再其后有一个空行,然后是数据实体。在我们的 http GET 数据包中,数据实体也就是我们需要查看的整个 html 文件。该 html 文件较长以至于一个 TCP 包已经不能满足数据量的要求,此时 http response 数据包就会被拆成被 TCP 拆成几块,每一块被一个TCP 段所包含。每个 TCP 段在0.17 html 1.6Wireshark 中被作为一个单独的数据包来记录。
回答问题:
(1) 浏览器向服务器发送了多少个 http GET 请求的数据包?
答:1个

(2) 该http response 数据包需要多少个含有数据的TCP 段来传送?
答:需要2个TCP段

(3) 与http GET 对应的response 数据包的状态代码是什么?
答:状态码是200,短语是OK

9、获取有嵌入对象的 HTML 文件
下面我们将了解含有嵌入对象的 html 文件的数据包,实验步骤如下(本次实验需要主机与本校以外的网络建立连接):
1) 打开你的浏览器,确认浏览器的缓冲器已经被清空;
2) 打开Wireshark,开始抓包;
3) 在浏览器地址栏中输入以下 URL:http://192.168.11.231 /test/test4.php在浏览器中将会显示一个含有两个图片的 html 文件。这两个图片是被该html 文件所引用的图片,也就是说该 html 文件并不包含这些图片文件,而是含有这些图片文件的 URL 地址。如果教材中所述,你的浏览器必须从相应的 URL 地址获取这些图片。
4) 停止Wireshark 抓包,在“ display-filter-specification” 窗口中输入“ http” 。
回答问题:
(1) 浏览器向服务器发送了多少个 http GET 请求的数据包?这些数据包发送的目的网址是什么?
答:发送了4个http GET 请求的数据包,目的网址是82.157.139.98和2001:da8:7013:8104::8047

应答报文的404,应答的是客户端向/favicon.ico发送的GET请求,favicon.ico表示的是显示在浏览器标签页左上角的logo,与实验关注的网页内容无关,所以可以忽略,如果忽略则为3条。
(2) 浏览器是从两个服务器上连续下载这两个图片还是并行下载的?请做相应解释。
答:串行,两个图片的请求包是以时间顺序发出文章来源:https://www.toymoban.com/news/detail-848658.html
 文章来源地址https://www.toymoban.com/news/detail-848658.html
文章来源地址https://www.toymoban.com/news/detail-848658.html
到了这里,关于计算机网络实验2 HTTP 抓包分析的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!