背景介绍
近来一套业务系统,从库一直处于延迟状态,无法追上主库,导致业务风险较大。从资源上看,从库的CPU、IO、网络使用率较低,不存在服务器压力过高导致回放慢的情况;从库开启了并行回放;在从库上执行show processlist看到没有回放线程阻塞,回放一直在持续;解析relay-log日志文件,发现其中并没大事务回放。
过程分析
现象确认
收到运维同事的反馈,有一套从库延迟的非常厉害,提供了show slave status延迟的截图信息
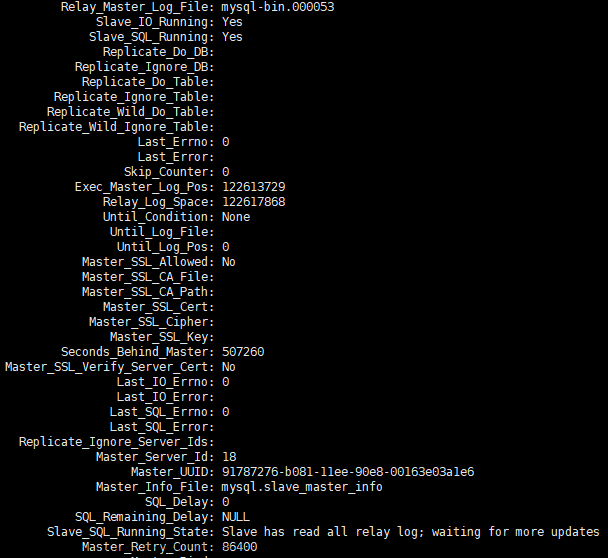
持续观察了一阵show slave status的变化,发现pos点位信息在不停的变化,Seconds_Behind_master也是不停的变化的,总体趋势还在不停的变大。
资源使用
观察了服务器资源使用情况,可以看到占用非常低

观察从库进程情况,基本上只能看到有一个线程在回放工作

并行回放参数说明
在主库设置了binlog_transaction_dependency_tracking=WRITESET
在从库设置了slave_parallel_type=LOGICAL_CLOCK和slave_parallel_workers=64
error log日志对比
从error log中取并行回放的日志进行分析
$ grep 010559 100werror3306.log | tail -n 3
2024-01-31T14:07:50.172007+08:00 6806 [Note] [MY-010559] [Repl] Multi-threaded slave statistics for channel 'cluster': seconds elapsed = 120; events assigned = 3318582273; worker queues filled over overrun level = 207029; waite
d due a Worker queue full = 238; waited due the total size = 0; waited at clock conflicts = 348754579743300 waited (count) when Workers occupied = 34529247 waited when Workers occupied = 76847369713200
2024-01-31T14:09:50.078829+08:00 6806 [Note] [MY-010559] [Repl] Multi-threaded slave statistics for channel 'cluster': seconds elapsed = 120; events assigned = 3319256065; worker queues filled over overrun level = 207029; waite
d due a Worker queue full = 238; waited due the total size = 0; waited at clock conflicts = 348851330164000 waited (count) when Workers occupied = 34535857 waited when Workers occupied = 76866419841900
2024-01-31T14:11:50.060510+08:00 6806 [Note] [MY-010559] [Repl] Multi-threaded slave statistics for channel 'cluster': seconds elapsed = 120; events assigned = 3319894017; worker queues filled over overrun level = 207029; waite
d due a Worker queue full = 238; waited due the total size = 0; waited at clock conflicts = 348943740455400 waited (count) when Workers occupied = 34542790 waited when Workers occupied = 76890229805500
上述信息的详细解释,可以参考MTS性能监控你知道多少
去掉了发生次数比较少的统计,显示了一些关键数据的对比

可以发现自然时间120,回放的协调线程有90多秒由于无法并行回放而进入等待,有近20秒是由于没有空闲的work线程进入等待,折算下来协调线程工作的时间只有10秒左右。
并行度统计
众所周知,mysql从库并行回放主要依赖于binlog中的last_commmitted来做判断,如果事务的last_committed相同,则基本上可以认为这些事务可以并行回放,下面从环境中获取一个relay log进行并行回放的大概统计
$ mysqlsqlbinlog --no-defaults 046638 |grep -o 'last_committed.*' | sed 's/=/ /g' | awk '{print $2}' |sort -n | uniq -c |awk 'BEGIN {print "last_commited group_count Percentage"} {count[$2]=$1
; sum+=$1} END {for (i in count) printf "%d %d %.2f%%\n", i, count[i], (count[i]/sum)*100|"sort -k 1,1n"}' | awk '{if($2>=1 && $2 <11){sum+=$2}} END {print sum}'
235703
$ mysqlsqlbinlog --no-defaults 046638 |grep -o 'last_committed.*' | sed 's/=/ /g' | awk '{print $2}' |sort -n | uniq -c |awk 'BEGIN {print "last_commited group_count Percentage"} {count[$2]=$1
; sum+=$1} END {for (i in count) printf "%d %d %.2f%%\n", i, count[i], (count[i]/sum)*100|"sort -k 1,1n"}' | awk '{if($2>10){sum+=$2}} END {print sum}'
314694
上述第一条命令,是统计last_committed相同的事务数量在1-10个,即并行回放程度较低或者是无法并行回放,这些事务总数量为235703,占43%,详细解析并行回放度比较低的事务分布,可以看出这部分last_committed基本上都是单条的,都需要等待先序事务回放完成后,自己才能进行回放,这就会造成前面日志中观察到的协调线程等待无法并行回放而进入等待的时间比较长的情况
$ mysqlbinlog --no-defaults 046638 |grep -o 'last_committed.*' | sed 's/=/ /g' | awk '{print $2}' |sort -n | uniq -c |awk 'BEGIN {print "last_commited group_count Percentage"} {count[$2]=$1; sum+=$1} END {for (i in count) printf "%d %d %.2f%%\n", i, count[i], (count[i]/sum)*100|"sort -k 1,1n"}' | awk '{if($2>=1 && $2 <11) {print $2}}' | sort | uniq -c
200863 1
17236 2
98 3
13 4
3 5
1 7
第二条命令统计last_committed相同的事务数量超过10个的总事务数,其数量为314694,占57%,详细解析了这些并行回放度比较高的事务,可以看到每一组是在6500~9000个事务数间
$ mysqlsqlbinlog --no-defaults 046638 |grep -o 'last_committed.*' | sed 's/=/ /g' | awk '{print $2}' |sort -n | uniq -c |awk 'BEGIN {print "last_commited group_count Percentage"} {count[$2]=$1
; sum+=$1} END {for (i in count) printf "%d %d %.2f%%\n", i, count[i], (count[i]/sum)*100|"sort -k 1,1n"}' | awk '{if($2>11){print $0}}' | column -t
last_commited group_count Percentage
1 7340 1.33%
11938 7226 1.31%
23558 7249 1.32%
35248 6848 1.24%
46421 7720 1.40%
59128 7481 1.36%
70789 7598 1.38%
82474 6538 1.19%
93366 6988 1.27%
104628 7968 1.45%
116890 7190 1.31%
128034 6750 1.23%
138849 7513 1.37%
150522 6966 1.27%
161989 7972 1.45%
175599 8315 1.51%
189320 8235 1.50%
202845 8415 1.53%
218077 8690 1.58%
234248 8623 1.57%
249647 8551 1.55%
264860 8958 1.63%
280962 8900 1.62%
297724 8768 1.59%
313092 8620 1.57%
327972 9179 1.67%
344435 8416 1.53%
359580 8924 1.62%
375314 8160 1.48%
390564 9333 1.70%
407106 8637 1.57%
422777 8493 1.54%
438500 8046 1.46%
453607 8948 1.63%
470939 8553 1.55%
486706 8339 1.52%
503562 8385 1.52%
520179 8313 1.51%
535929 7546 1.37%
last_committed机制介绍
主库的参数binlog_transaction_dependency_tracking用于指定如何生成其写入二进制日志的依赖信息,以帮助从库确定哪些事务可以并行执行,即通过该参数控制last_committed的生成机制,参数可选值有COMMIT_ORDER、WRITESET、SESSION_WRITESET。
从下面这段代码,很容易看出来三种参数关系:
- 基础算法为COMMIT_ORDER
- WRITESET算法是在COMMIT_ORDER基础上再计算一次
- SESSION_WRITESET算法是在WRITESET基础上再计算一次

由于我的实例设置的是WRITESET,因此关注COMMIT_ORDER算法和的WRITESET算法即可。
COMMIT_ORDER
COMMIT_ORDER计算规则:如果两个事务在主节点上是同时提交的,说明两个事务的数据之间没有冲突,那么一定也是可以在从节点上并行执行的,理想中的典型案例如下面的例子
| session-1 | session-2 |
|---|---|
| BEGIN | BEGIN |
| INSERT t1 values(1) | |
| INSERT t2 values(2) | |
| commit (group_commit) | commit (group_commit) |
但对于MySQL来说,group_commit是内部行为,只要session-1和session-2是同时执行commit,不管内部是否合并为group_commit,两个事务的数据本质上都是没有冲突的;再退一步来讲,只要session-1执行commit之后,session-2没有新的数据写入,两个事务依旧没有数据冲突,依然可以并行复制。
| session-1 | session-2 |
|---|---|
| BEGIN | BEGIN |
| INSERT t1 values(1) | |
| INSERT t2 values(2) | |
| commit | |
| commit |
对于更多并发线程的场景,可能这些线程不能同时并行复制,但部分事务却可以。以如下一个执行顺序来说,在session-3提交之后,session-2没有新的写入,那么这两个事务是可以并行复制的;而session-3提交后,session-1又插入了一条新的数据,此时无法判定数据冲突,所以session-3和session-1的事务无法并行复制;但session-2提交后,session-1之后没有新数据写入,所以session-2和session-1又可以并行复制。因此,这个场景中,session-2分别可以和session-1,session-3并行复制,但3个事务无法同时并行复制。
| session-1 | session-2 | session-3 |
|---|---|---|
| BEGIN | BEGIN | BEGIN |
| INSERT t1 values(1) | INSERT t2 values(1) | INSERT t3 values(1) |
| INSERT t1 values(2) | INSERT t2 values(2) | |
| commit | ||
| INSERT t1 values(3) | ||
| commit | ||
| commit |
WRITESET
实际上是commit_order+writeset的组合,会先通过commit_order计算出一个last_committed值,然后再通过writeset计算一个新值,最后取两者间的小值作为最终事务gtid的last_committed。
在MySQL中,writeset本质上是对 schema_name + table_name + primary_key/unique_key 计算的hash值,在DML执行语句过程中,通过binlog_log_row生成row_event之前,会将DML语句中所有的主键/唯一键都单独计算hash值,并加入到事务本身的writeset列表中。而如果存在无主键/唯一索引的表,还会对事务设置has_missing_keys=true。
参数设置为WRITESET,但是并不一定就能使用上,其限制如下
- 非DDL语句或者表具有主键或者唯一键或者空事务
- 当前session使用的hash算法与hash map中的一致
- 未使用外键
- hash map的容量未超过binlog_transaction_dependency_history_size的设置
以上4个条件均满足时,则可以使用WRITESET算法,如果有任意一个条件不满足,则会退化为COMMIT_ORDER计算方式

具体WRITESET算法如下,事务提交时:
-
last_committed设置为m_writeset_history_start,此值为m_writeset_history列表中最小的sequence_number
-
遍历事务的writeset列表
a 如果某个writeset在全局m_writeset_history中不存在,构建一个pair<writeset, 当前事务的sequence_number>对象,插入到全局m_writeset_history列表中
b. 如果存在,那么last_committed=max(last_committed, 历史writeset的sequence_number值),并同时更新m_writeset_history中该writeset对应的sequence_number为当前事务值
-
如果has_missing_keys=false,即事务所有数据表均包含主键或者唯一索引,则最后取commit_order和writeset两种方式计算的最小值作为最终的last_committed值

TIPS:基于上面WRITESET规则,就会出现后提交的事务的last_committed比先提交的事务还小的情况
结论分析
结论描述
根据WRITESET的使用限制,对relay-log及事务中涉及到的表结构进行了对比,分析单last_committed的事务组成发现如下两种情况:
- 单last_committed的事务中涉及到的数据和sequence_number存在数据冲突
- 单last_committed的事务中涉及到的表存在无主键的情况,而且这种事务特别多
从上面的分析中可以得出结论:无主键表的事务太多,导致WRITESET退化为COMMIT_ORDER,而由于数据库为TP应用,事务都快速提交,多个事务提交无法保证在一个commit周期内,导致COMMIT_ORDER机制产生的last_committed重复读很低。从库也就只能串行回放这些事务,引起回放延迟。
优化措施
- 从业务侧对表做改造,在允许的情况下给相关表都添加上主键。
- 尝试调大参数binlog_group_commit_sync_delay、binlog_group_commit_sync_no_delay_count从0修改为10000,由于特殊环境限制,该调整并未生效,不同的场景可能会有不同的表现。
Enjoy GreatSQL 😃
关于 GreatSQL
GreatSQL是适用于金融级应用的国内自主开源数据库,具备高性能、高可靠、高易用性、高安全等多个核心特性,可以作为MySQL或Percona Server的可选替换,用于线上生产环境,且完全免费并兼容MySQL或Percona Server。
相关链接: GreatSQL社区 Gitee GitHub Bilibili
GreatSQL社区:
社区博客有奖征稿详情:https://greatsql.cn/thread-100-1-1.html

技术交流群:
微信:扫码添加
GreatSQL社区助手微信好友,发送验证信息加群。文章来源:https://www.toymoban.com/news/detail-848746.html
 文章来源地址https://www.toymoban.com/news/detail-848746.html
文章来源地址https://www.toymoban.com/news/detail-848746.html
到了这里,关于从库延迟案例分析的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!