ElasticSearch 底层读写原理
写请求是写入 primary shard,然后同步给所有的 replica shard;读请求可以从 primary shard 或 replica shard 读取,采用的是随机轮询算法。
1、ES写入数据的过程
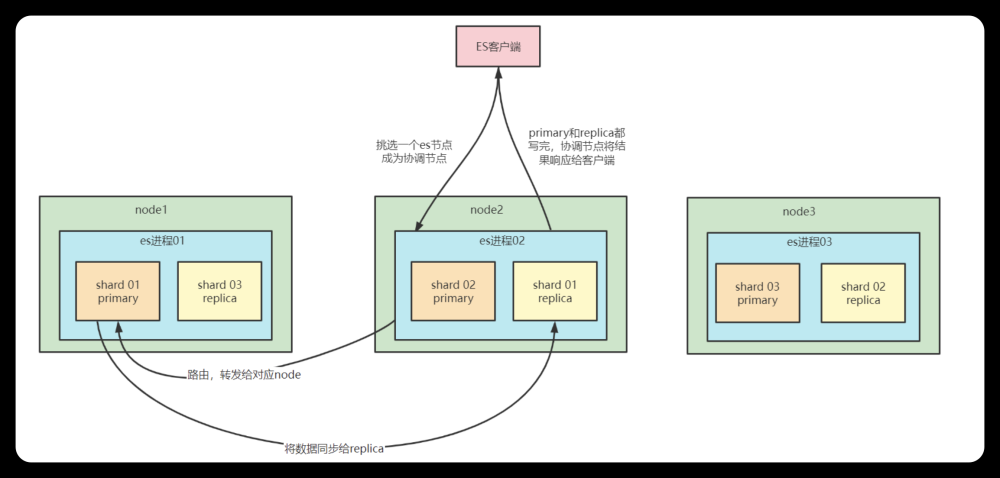
1.选择任意一个DataNode发送请求,例如:node2。此时,node2就成为一个coordinating node(协调节点)
2.计算得到文档要写入的分片 shard = hash(routing) % number_of_primary_shards routing 是一个可变值,默认是文档的 _id
3.coordinating node会进行路由,将请求转发给对应的primary shard所在的DataNode(假设primary shard在node1、replica shard在node2)
4.node1节点上的Primary Shard处理请求,写入数据到索引库中,并将数据同步到Replica shard
5.Primary Shard和Replica Shard都保存好了文档,返回client.
注意:es路由分片规则是 shard = hash(routing) % number_of_primary_shards,其中number_of_primary_shards为分片数。
2、ES读取数据的过程
2.1根据id查询数据的过程
根据 doc id 进行 hash,判断出来当时把 doc id 分配到了哪个 shard 上面去,从那个 shard 去查询。
- 客户端发送请求到任意一个 node,成为 coordinate node 。
- coordinate node 对 doc id 进行哈希路由,将请求转发到对应的 node,此时会使用 round-robin 随机轮询算法,在 primary shard 以及其所有 replica 中随机选择一个,让读请求负载均衡。
- 接收请求的 node 返回 document 给 coordinate node 。
- coordinate node 返回 document 给客户端。
2.2根据关键词查询数据的过程
- 客户端发送请求到一个 coordinate node 。
- 协调节点将搜索请求转发到所有的 shard 对应的 primary shard 或 replica shard ,都可以。
- query phase:每个 shard 将自己的搜索结果返回给协调节点,由协调节点进行数据的合并、排序、分页等操作,产出最终结果。
- fetch phase:接着由协调节点根据 doc id 去各个节点上拉取实际的 document 数据,最终返回给客户端。
3、写数据底层原理
核心概念
segment file: 存储倒排索引的文件,每个segment本质上就是一个倒排索引,每秒都会生成一个segment文件,当文件过多时es会自动进行segment merge(合并文件),合并时会同时将已经标注删除的文档物理删除。
commit point: 记录当前所有可用的segment,每个commit point都会维护一个.del文件,即每个.del文件都有一个commit point文件(es删除数据本质是不属于物理删除),当es做删改操作时首先会在.del文件中声明某个document已经被删除,文件内记录了在某个segment内某个文档已经被删除,当查询请求过来时在segment中被删除的文件是能够查出来的,但是当返回结果时会根据commit point维护的那个.del文件把已经删除的文档过滤掉
translog日志文件: 为了防止elasticsearch宕机造成数据丢失保证可靠存储,es会将每次写入数据同时写到translog日志中。
**os cache:**操作系统里面,磁盘文件其实都有一个东西,叫做os cache,操作系统缓存,就是说数据写入磁盘文件之前,会先进入os cache,先进入操作系统级别的一个内存缓存中去。

Refresh
- 将文档先保存在Index buffer中,以refresh_interval为间隔时间,定期清空buffer,生成 segment,借助文件系统缓存的特性,先将segment放在文件系统缓存中,并开放查询,以提升搜索的实时性
Translog文章来源:https://www.toymoban.com/news/detail-848755.html
- Segment没有写入磁盘,即便发生了宕机,重启后,数据也能恢复,从ES6.0开始默认配置是每次请求都会落盘
Flush文章来源地址https://www.toymoban.com/news/detail-848755.html
- 删除旧的translog 文件
- 生成Segment并写入磁盘│更新commit point并写入磁盘。ES自动完成,可优化点不多
到了这里,关于ElasticSearch 底层读写原理的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
![五、浅析[ElasticSearch]底层原理与分组聚合查询](https://imgs.yssmx.com/Uploads/2024/02/560240-1.png)