在讨论智能化 Agent 之前,我们首先来了解一下,什么是 Agent?
Agent 是一个通过传感器感知所处环境、通过执行器对环境产生作用的东西。
如果将人类看成一个 Agent,那么传感器就是眼睛、耳朵等器官,执行器就是手、腿等身体的其他部位。
接下来,我们就来介绍一下五种基本的 Agent,包括:
- 简单反射型 Agent
- 基于模型的反射型 Agent
- 基于目标的 Agent
- 基于效用的 Agent
- 学习 Agent
简单反射型 Agent
简单反射型 Agent 基于当前的感知选择行动,忽略其余的感知历史。
简单反射型 Agent 的结构如下:
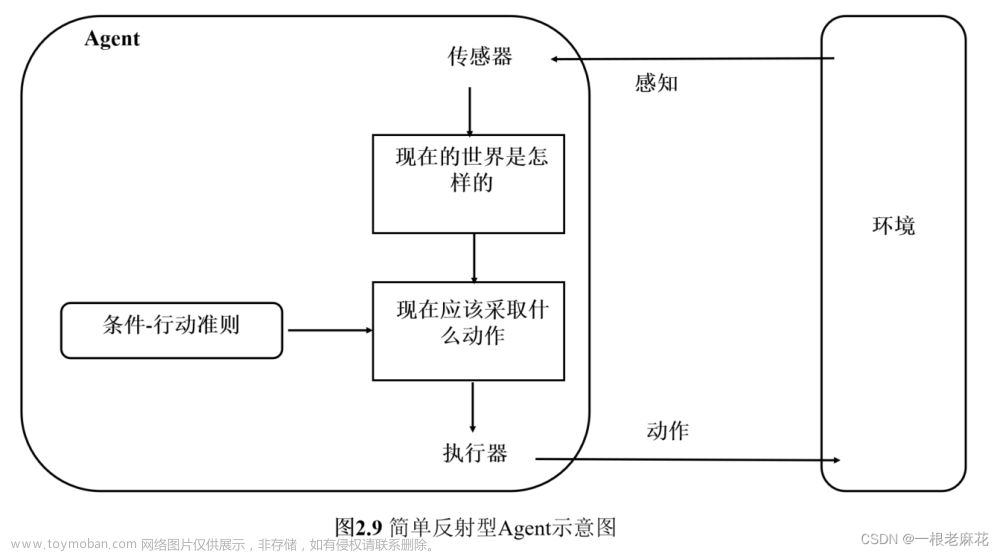
- 传感器:感知当前所处的环境
- 条件 - 行动准则:根据感知信息匹配相应的行动规则。
- 执行器:执行相应的动作,对环境产生作用。
简单反射型 Agent 可以通过建立一个通用的条件 - 行动规则解释器,然后对特定任务环境创建规则集合来实现。例如,在驾驶系统中创建一个规则,即如果前方的车辆在减速刹车,那么系统也开始控制车辆减速刹车。
实现的伪代码如下:

基于模型的反射型 Agent
基于模型的反射型 Agent 在简单反射型 Agent 的基础上,维持了一个取决于历史的内部状态,从而反映当前状态的某些不可观察的方面。为了随时更新内部状态,需要加入两种类型的知识:
- 关于世界如何独立于 Agent 而发展的信息。 例如:超车的汽车在下一时刻会从后方赶上来,更靠近本车。
- 关于 Agent 自身的动作如何影响世界的信息。例如:当 Agent 顺时针转动方向盘时,汽车向右转。
这种关于世界如何运转的知识,称为世界模型。使用这样模型的 Agent 称为基于模型的 Agent。
【深度学习中的 LSTM(长短时记忆)、和注意力机制等属于基于模型的反射型 Agent】
基于模型的反射型 Agent 结构如下:
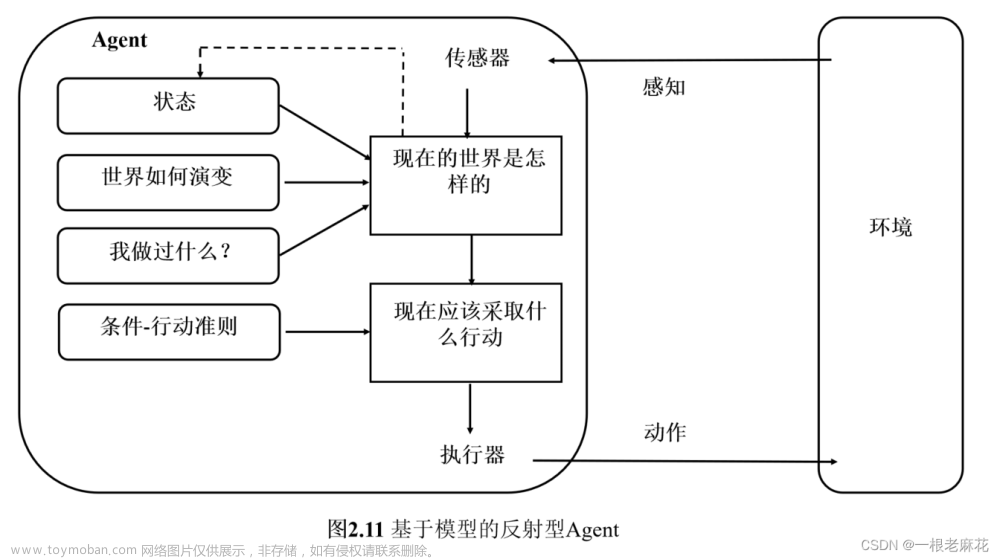
实现的伪代码如下:

- rules 代表世界如何演变。
- 初始的 action 代表我做过什么,更新后的 action 表示现在应该采取什么行动。
基于目标的 Agent
基于目标的 Agent 不仅需要当前状态的描述,而且需要某种目标信息来描述想要达到的状况。例如:乘客的目的地。Agent 程序会把目标信息和可能动作的结果结合起来,评估不同动作的优劣,从而选择最有利于实现目标的动作。【路径规划、8 数码问题等属于基于目标的 Agent】
基于目标的 Agent 结构如下:
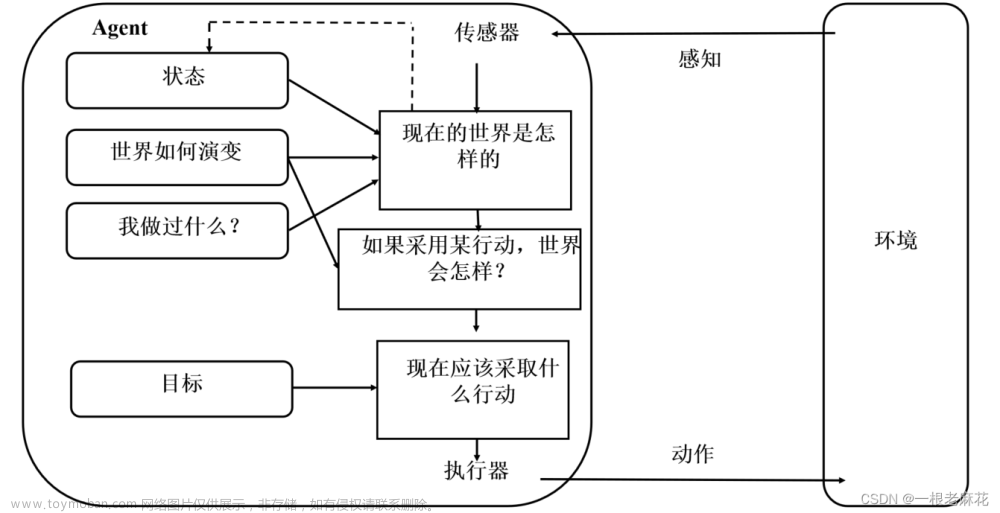
基于模型和目标的 Agent,既要追踪记录世界的状态(前方车辆是否减速、后方车辆是否准备超车),又要记录要达到的目标集(车辆行驶的目的地),并选择能最终到达目标的动作(方向盘不同还是左打右打)
基于效用的 Agent
在很多环境下,单靠目标很难产生好的行为。例如:有很多路线可以令出租车到达目的地。但是有的路线更快、更安全、更可靠、或者更便宜。如果一个世界状态比另一个更受偏好,则对 Agent 来说有更高的效用。
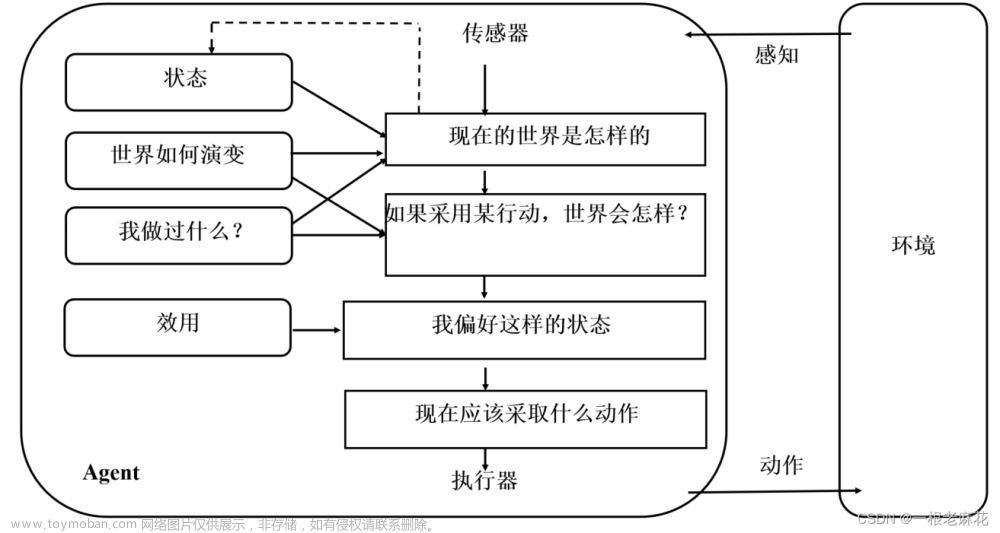
基于效用的 Agent 在目基于目标的 Agent 的基础上,增加了一个效用模块,用于存储 Agent 对不同状态或结果的偏好或满意度。这样,Agent 就可以根据世界状态、要达到的目标集以及效用函数,选择导致最佳期望效用的动作。【机场选址、雄安新区选址、高铁路线设计、人生目标的选择等决策,属于基于效用 Agent】
基于效用的 Agent 结构如下:
学习 Agent
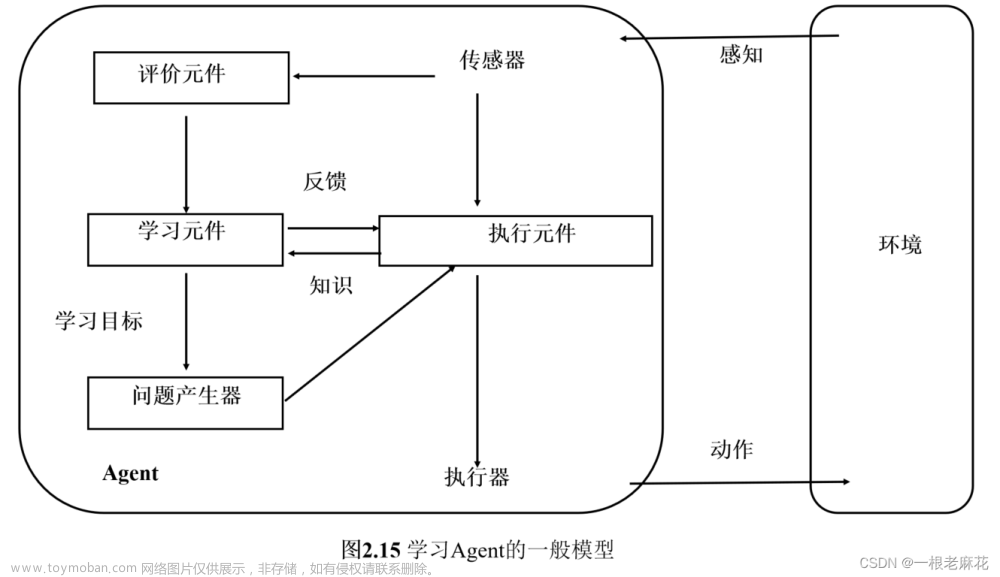
学习 Agent 可以划分为四个概念上的组件,根据外部的反馈和内部的评价来改进 Agent 的行为。
学习 Agent 结构如下:文章来源:https://www.toymoban.com/news/detail-849025.html
 文章来源地址https://www.toymoban.com/news/detail-849025.html
文章来源地址https://www.toymoban.com/news/detail-849025.html
- 评价元件:根据固定的性能标准来评估 Agent 在环境中的行为表现,给 Agent 提供正向或反向的反馈信号,以指导 Agent 的学习过程。例如,根据棋局的优劣来给Agent一个分数;根据 Agent 是否赢得比赛来给 Agent 一个奖励或惩罚。
- 学习元件:利用来自评价元件的反馈,评价Agent做得如何,并决定应该如何修改执行元件以在未来做得更好。
- 执行元件:执行外部动作,同时为学习元件提供知识。
- 问题产生器:负责提议可以产生新的、有启发式价值的经验的动作。
到了这里,关于人工智能 | 一文介绍五种基本 Agent的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!