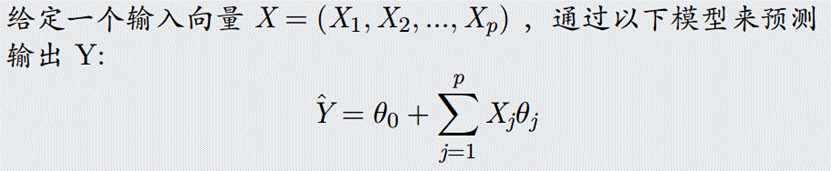本文讲述两个经典机器学习逻辑回归(Logistic Regression)和线性回归(Linear Regression)算法的异同,有助于我们在面对实际问题时更好的进行模型选择。也能帮助我们加深对两者的理解,掌握这两类基础模型有助于进一步理解更复杂的模型结构,例如逻辑回归是许多复杂分类算法的基础模型之一,对其深入理解有助于后续学习神经网络、支持向量机等更为复杂的模型。
如果对这两个模型的基本知识有所遗忘,可以观看我之前的文章哦:
【机器学习300问】15、什么是逻辑回归模型?【机器学习300问】8、为什么要设计代价函数(损失函数)?它有什么用?
一、逻辑回归于线性回归的区别
(1)区别1:使用场景不同
逻辑回归和线性回归的核心区别在于它们的目的和适用场景,逻辑回归处理的是分类问题,线性回归处理的是回归问题,这是两者的最本质的区别。
① 逻辑回归
虽然名称中有“回归”二字,但实际上主要用于解决分类问题,尤其是二分类问题,当然也可以通过扩展应用到多分类问题上。逻辑回归模型预测的是一个事件发生的概率,输出的是介于0和1之间的概率值,然后可以设定一个阈值来决定最终的类别归属,例如预测用户是否会点击广告、病人是否有某种疾病等。
② 线性回归
是一种回归模型,用于估计因变量(目标变量)和一个或多个自变量之间的连续关系,输出是一个连续的数值,适合于解决那些需要预测具体数值的问题,如预测房价、销售额、体重增长等。
简单来说,线性回归关注的是“多少”的数值,逻辑回归关注的是“是与否”的可能性。在模型内部,逻辑回归确实采用了类似线性回归的加权求和形式,但是最后会通过一个非线性函数(通常是Sigmoid函数)将线性部分映射到概率空间。
(2)区别2:输出值的形式不同
此外两者还在输出值(因变量)的形式上有差异,逻辑回归中的输出值是离散的,线性回归中的输出值是连续的。
① 逻辑回归
逻辑回归模型内部采用线性函数对输入特征进行加权求和(也就是线性组合),但随后会对这个线性组合应用一个非线性函数,通常是sigmoid函数,将其映射到(0,1)之间,表达的是一个概率值。由于最终的概率被设定一个阈值来决定类别(例如,概率大于0.5则判为正类,否则为负类),因此其输出值实际应用中往往转化为离散的类别标签。
② 线性回归
线性模型的输出值是连续的,直接反映了预测变量与因变量之间的线性关系。线性回归的目标是找到最优的直线或超平面来拟合数据点,其预测结果可以是任何实数,没有限制在特定范围内,因此非常适合于预测像房价、销售额、身高、体重等连续型数值变量。
(3)区别3:损失函数不同
① 逻辑回归
通常使用均方误差(MSE)作为损失函数,来度量预测值与实际值之间的差异。
② 线性回归
使用对数损失函数,也称为交叉熵损失,它度量的是实际分类和预测分类概率分布之间的差距。
二、逻辑回归于线性回归的相似之处
(1)相似1:都使用了极大似然估计
无论是线性回归还是逻辑回归,两者都使用了最大似然估计来对训练样本进行建模。只不过它们背后的概率分布假设和优化的目标函数有所不同。
① 逻辑回归
针对二分类问题,由于响应变量是分类变量(通常是0和1)它的最大似然函数会有所不同。因变量被看作是服从伯努利分布或者多项式分布(在多分类问题中对应的是多项式 logistic 回归)。逻辑回归同样使用极大似然估计,只是这时是在伯努利分布条件下,通过最大化所有样本观测到的结果(0或1)出现的概率之乘积来估计模型参数。
② 线性回归
如果假设因变量(响应变量)遵循正态分布(即满足高斯分布假设),那么最小二乘估计可以被视为最大似然估计的一种特殊情况。当误差项独立同分布,均值为0,方差为常数时,通过最大化似然函数(等价于最小化误差的平方和),可以得到模型参数。
(2)相似2:都使用了梯度下降算法
两者都可以在求解参数的过程中,使用梯度下降算法。梯度下降是一种通用的优化方法,可用于求解各种模型的损失函数最小化问题。文章来源:https://www.toymoban.com/news/detail-849070.html
不论是线性回归模型最小化均方误差(Mean Squared Error, MSE),还是逻辑回归模型最大化似然函数(通过最小化负对数似然函数,即交叉熵损失函数),都可以运用梯度下降或其变种(如随机梯度下降、批量梯度下降、小批量梯度下降等)来迭代更新模型参数。这种迭代过程使得模型参数逐步向着减少损失函数值的方向变化,从而达到优化模型的目的。文章来源地址https://www.toymoban.com/news/detail-849070.html
到了这里,关于【机器学习300问】61、逻辑回归与线性回归的异同?的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!