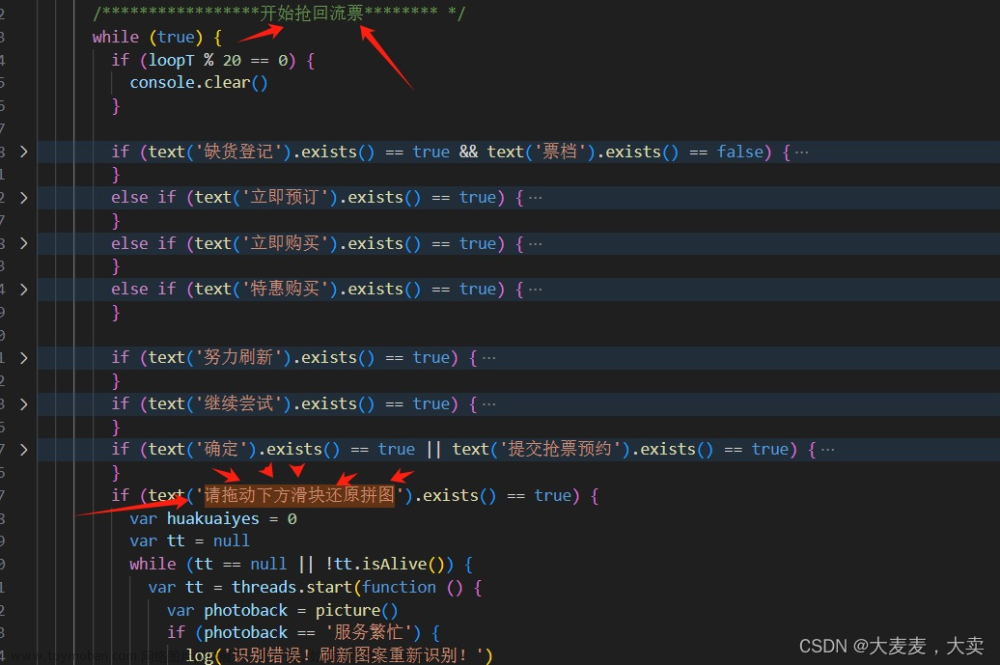
请注意,编写或使用抢票脚本可能违反相关网站的服务条款和法律法规。以下内容仅供学习和了解技术原理之用,不鼓励或支持任何违反规定的行为。
在Python中编写大麦网抢票脚本通常涉及以下几个步骤:
### 1. 分析网站结构
- 使用浏览器的开发者工具(如Chrome的Inspect功能)分析大麦网的页面结构和网络请求。
- 确定抢票过程中需要交互的页面元素和提交的表单数据。
### 2. 发送网络请求
- 使用`requests`库发送HTTP请求,模拟浏览器操作。
- 处理登录、获取票务信息、提交订单等步骤。
### 3. 处理验证码
- 如果网站有验证码,可能需要使用图像处理库(如`PIL`或`opencv`)来自动识别,或者使用第三方验证码识别服务。
### 4. 优化性能
- 使用多线程或异步IO(如`asyncio`库)来提高脚本的运行效率。
- 合理设置请求间隔,避免因频繁请求被服务器封禁。
### 5. 遵守法律法规
- 确保脚本的使用不违反相关法律法规和服务条款。
- 考虑到其他用户的权益,不要过度占用服务器资源。
### 示例代码(仅供参考)
```python
import requests
from bs4 import BeautifulSoup
# 基本的请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3',
'Referer': 'https://www.damai.cn/',
'Cookie': '你的大麦网登录cookie'
}
# 登录URL
login_url = 'https://www.damai.cn/login'
# 抢票URL(示例)
ticket_url = 'https://www.damai.cn/some-ticket-page'
# 发送登录请求
session = requests.Session()
login_data = {
'username': '你的账号',
'password': '你的密码'
}
response = session.post(login_url, data=login_data, headers=headers)
if '登录成功' in response.text:
print('登录成功')
# 发送抢票请求
ticket_data = {
'concert_id': '演唱会ID',
'ticket_type': '票档'
}
response = session.post(ticket_url, data=ticket_data, headers=headers)
if '订单创建成功' in response.text:
print('抢票成功')
```文章来源:https://www.toymoban.com/news/detail-849094.html
请记住,实际的抢票过程可能比这个示例更复杂,涉及到的技术和步骤也更多。此外,大麦网和其他票务平台可能会采取各种措施来防止自动化脚本的使用,包括但不限于验证码、IP限制、行为分析等。因此,即使技术上可行,使用抢票脚本也存在一定的风险和不确定性。在使用任何自动化工具之前,请确保你了解并遵守相关的法律法规和服务条款。文章来源地址https://www.toymoban.com/news/detail-849094.html
到了这里,关于Python 大麦抢票脚本的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!