前言
Selenium Grid 是 Selenium 测试框架的一个关键组件,它为测试人员提供了在多个计算机和浏览器上并行执行测试的能力。通过 Selenium Grid,我们能够更高效地进行大规模测试,并确保应用程序在不同环境中的稳定性和一致性。
我们将从以下几点深入解析Selenium Grid分布式运行的逻辑:
-
Selenium Grid 的核心特性
-
Selenium Grid的组件
-
Selenium Grid 的工作原理
-
Selenium Grid运行环境配置
-
Selenium Grid单机模式(standalone)
-
Selenium Grid中心模式(Hub & Node)
-
Hub and Node在不同的机器上配置
Selenium Grid 的核心特性
Selenium Grid 具有以下核心特性,使其成为分布式测试的首选工具之一:
-
并行执行测试: Selenium Grid 允许在多个计算机上同时运行测试,从而显著缩短测试执行时间。这对于大规模测试套件和需要在不同配置下运行的测试非常有用。
-
支持多浏览器和多平台: Selenium Grid 提供了在不同浏览器(如 Chrome、Firefox、Safari)和操作系统(Windows、Linux、macOS)上同时执行测试的能力。这样,您可以确保应用程序在各种环境中都能够正常工作。
-
节点管理: Selenium Grid 通过节点管理实现测试的分发和执行。Grid 包含一个主节点(Hub)和多个从节点(Node),测试脚本在主节点上启动,然后分发到可用的从节点上执行。
-
灵活的配置选项: Selenium Grid 提供了丰富的配置选项,可以根据测试需求进行灵活配置。您可以选择在本地计算机上设置 Grid,也可以在云服务上创建 Grid 集群。
Selenium Grid的组件
主要包括:
1. 路由器(Router)
2. 分发器(Distributor)
3. 会话映射(Session Map)
4. 新会话队列(New Session Queue)
5. 节点(Node)
6. 事件总线(Event Bus)
示意图:

1. 路由器(Router)
-
作用: 充当 Grid 的入口点,接收所有外部请求,并将它们转发到正确的组件。
-
功能:
-
处理新的会话请求,转发到新会话队列。
-
查询会话映射,将请求转发到相应的节点。
-
平衡负载,将请求发送到更好地处理请求的组件。
-
2. 分发器(Distributor)
-
作用: 注册并跟踪所有节点及其功能,查询新会话队列并处理挂起的新会话请求。
-
功能:
-
注册节点并跟踪其功能。
-
查询新会话队列,处理新会话请求,并将其分配给适当的节点。
-
通过 GridModel 跟踪所有节点的功能。
-
3. 会话映射(Session Map)
-
作用: 保存会话 ID 和运行会话的节点之间的关系。
-
功能:
-
被路由器查询,以确定与会话 ID 相关联的节点。
-
4. 新会话队列(New Session Queue)
-
作用: 以 FIFO 顺序保存所有新的会话请求。
-
功能:
-
将新的会话请求添加到队列中。
-
定期检查队列中的请求是否超时。
-
轮询队列,将请求分配给可用的节点插槽。
-
5. 节点(Node)
-
作用: 管理运行它的机器上可用浏览器的插槽。
-
功能:
-
注册到分发服务器,报告自己的配置。
-
自动注册运行机器上可用的所有浏览器驱动程序。
-
创建浏览器插槽,并执行接收到的命令。
-
6. 事件总线(Event Bus)
-
作用: 充当节点、分发器、新会话队列和会话映射之间的通信路径。
-
功能:
-
处理节点注册事件和其他内部通信。
-
通过消息进行内部通信,避免昂贵的 HTTP 调用。
-
Selenium Grid 的工作原理
Selenium Grid 的工作原理涉及到主节点(Hub)和从节点(Node)之间的协作。以下是 Selenium Grid 的基本工作流程:
-
Hub 启动: 在网络中的一台计算机上启动 Selenium Grid Hub。Hub 负责接收测试脚本的请求,并将其分发给可用的从节点执行。
-
Node 注册: 在每个需要参与分布式测试的计算机上启动 Selenium Grid Node。Node 将自己注册到 Hub,宣告其可用的浏览器和操作系统配置。
-
测试脚本提交: 测试脚本由测试开发人员编写,并通过 Selenium Grid 提交到 Hub。测试脚本包含要执行的测试步骤和所需的浏览器/操作系统配置。
-
分发和执行: Hub 接收到测试脚本后,根据配置选择一个或多个可用的 Node,并将测试脚本分发到这些节点上执行。每个节点负责打开指定浏览器,执行测试脚本,并将结果返回给 Hub。
-
结果聚合: Hub 收集所有节点的测试结果,并提供一个汇总报告。测试人员可以从 Hub 获取整个分布式测试的结果,包括成功的测试用例和失败的断言。
Selenium Grid运行环境配置
-
安装 Java: Selenium Grid 是基于 Java 的,因此您需要安装 Java 运行时环境。
官网下载:Java Downloads | Oracle
选择自己对应的系统类别,电脑支持的位数/芯片,点击
下载地址即可下载(建议使用目前稳定的版本 1.8)

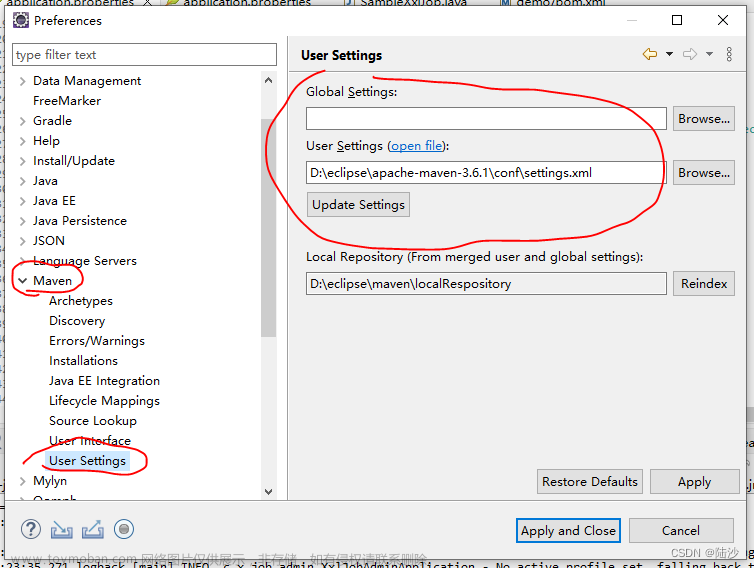
后续进行傻瓜式安装,直接点击 下一步 即可,安装完成后,需要配置JDK的环境变量,按照以下步骤进行:
a. 右键点击 我的电脑→属性→高级系统设置→环境变量

b. 系统变量→新建,新建一个变量名 JAVA_HOME,变量值为JDK的安装目录

c. 系统变量→新建,新建一个变量名 CLASSPATH,变量值为.;%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar;

d. 找到 path 变量,双击开始编辑,点击 新建,输入第一个值 %JAVA_HOME%\bin,再点击 新建,输入第二个值 %JAVA_HOME%\jre\bin

e. 点击 确定,关闭所有已打开的环境变量配置窗口,打开一个新的CMD命令窗口,输入 java -version,检查安装java的版本,再输入 java,查看输出内容是否正确(只要出现相关的提示即可),再输入 javac,一样的进行检查
java -version的检查结果:
java version "1.8.0_341"
Java(TM) SE Runtime Environment (build 1.8.0_341-b10)
Java HotSpot(TM) 64-Bit Server VM (build 25.341-b10, mixed mode)java的检查结果:
用法: java [-options] class [args...]
(执行类)
或 java [-options] -jar jarfile [args...]
(执行 jar 文件)
其中选项包括:
-d32 使用 32 位数据模型 (如果可用)
-d64 使用 64 位数据模型 (如果可用)
-server 选择 "server" VM
默认 VM 是 server,
因为您是在服务器类计算机上运行。
-cp <目录和 zip/jar 文件的类搜索路径>
-classpath <目录和 zip/jar 文件的类搜索路径>
用 : 分隔的目录, JAR 档案
和 ZIP 档案列表, 用于搜索类文件。
-D<名称>=<值>
设置系统属性
-verbose:[class|gc|jni]
启用详细输出
-version 输出产品版本并退出
-version:<值>
警告: 此功能已过时, 将在
未来发行版中删除。
需要指定的版本才能运行
-showversion 输出产品版本并继续
-jre-restrict-search | -no-jre-restrict-search
警告: 此功能已过时, 将在
未来发行版中删除。
在版本搜索中包括/排除用户专用 JRE
-? -help 输出此帮助消息
-X 输出非标准选项的帮助
-ea[:<packagename>...|:<classname>]
-enableassertions[:<packagename>...|:<classname>]
按指定的粒度启用断言
-da[:<packagename>...|:<classname>]
-disableassertions[:<packagename>...|:<classname>]
禁用具有指定粒度的断言
-esa | -enablesystemassertions
启用系统断言
-dsa | -disablesystemassertions
禁用系统断言
-agentlib:<libname>[=<选项>]
加载本机代理库 <libname>, 例如 -agentlib:hprof
另请参阅 -agentlib:jdwp=help 和 -agentlib:hprof=help
-agentpath:<pathname>[=<选项>]
按完整路径名加载本机代理库
-javaagent:<jarpath>[=<选项>]
加载 Java 编程语言代理, 请参阅 java.lang.instrument
-splash:<imagepath>
使用指定的图像显示启动屏幕
有关详细信息, 请参阅 http://www.oracle.com/technetwork/java/javase/documentation/index.html。
javac的检查结果:
用法: javac <options> <source files>
其中, 可能的选项包括:
-g 生成所有调试信息
-g:none 不生成任何调试信息
-g:{lines,vars,source} 只生成某些调试信息
-nowarn 不生成任何警告
-verbose 输出有关编译器正在执行的操作的消息
-deprecation 输出使用已过时的 API 的源位置
-classpath <路径> 指定查找用户类文件和注释处理程序的位置
-cp <路径> 指定查找用户类文件和注释处理程序的位置
-sourcepath <路径> 指定查找输入源文件的位置
-bootclasspath <路径> 覆盖引导类文件的位置
-extdirs <目录> 覆盖所安装扩展的位置
-endorseddirs <目录> 覆盖签名的标准路径的位置
-proc:{none,only} 控制是否执行注释处理和/或编译。
-processor <class1>[,<class2>,<class3>...] 要运行的注释处理程序的名称; 绕过默认的搜索进程
-processorpath <路径> 指定查找注释处理程序的位置
-parameters 生成元数据以用于方法参数的反射
-d <目录> 指定放置生成的类文件的位置
-s <目录> 指定放置生成的源文件的位置
-h <目录> 指定放置生成的本机标头文件的位置
-implicit:{none,class} 指定是否为隐式引用文件生成类文件
-encoding <编码> 指定源文件使用的字符编码
-source <发行版> 提供与指定发行版的源兼容性
-target <发行版> 生成特定 VM 版本的类文件
-profile <配置文件> 请确保使用的 API 在指定的配置文件中可用
-version 版本信息
-help 输出标准选项的提要
-A关键字[=值] 传递给注释处理程序的选项
-X 输出非标准选项的提要
-J<标记> 直接将 <标记> 传递给运行时系统
-Werror 出现警告时终止编译
@<文件名> 从文件读取选项和文件名-
下载 Selenium Grid JAR 文件: 下载 Selenium Grid 的 JAR 文件。
官网地址:https://github.com/SeleniumHQ/selenium/releases/tag/selenium-4.5.0

Selenium Grid单机模式(standalone)
启动命令(打开CMD命令窗口运行以下命令,要在jar包所在的目录运行命令才可,否则的话要给出jar存放的路径,包名最好使用Tab自动补全,防止写错字符):
java -jar selenium-server-4.5.0.jar standalone
启动后的命令窗口页面:

成功后用浏览器访问页面(http://127.0.0.1:4444):

启动成功后,需要在脚本中对浏览器对象进行配置(将WebDriver指向到启动的监听服务):
from selenium import webdriver
chrome_options = webdriver.ChromeOptions()
driver = webdriver.Remote(
command_executor='http://127.0.0.1:4444',
options=chrome_options
)
创建简单的自动化用例:
import time
from selenium import webdriver
chrome_options = webdriver.ChromeOptions()
driver = webdriver.Remote(
command_executor='http://127.0.0.1:4444',
options=chrome_options
)
driver.get("http://www.baidu.com")
driver.find_element("id", "kw").send_keys("Selenium Grid")
time.sleep(10)
driver.quit()
通过浏览器访问 Grid 的控制台,查看测试的执行情况和结果(运行用例的时候,打开Grid 的控制台进行查看):
Selenium Grid中心模式(Hub & Node)
Hub(主控制节点)
Hub 是 Selenium Grid 的中心控制节点,负责管理和分发测试请求。Hub 接收来自测试脚本的请求,然后将这些请求分发给连接到 Grid 的各个 Node 上执行。
功能:
-
管理测试分发: Hub 负责将测试分发给 Grid 中可用的 Node。
-
维护节点信息: Hub 会维护连接到它的各个 Node 的信息,包括节点的浏览器类型和版本。
-
处理测试结果: Hub 负责收集并汇总各个 Node 返回的测试结果。
启动命令(打开CMD命令窗口运行以下命令,要在jar包所在的目录运行命令才可,否则的话要给出jar存放的路径,包名最好使用Tab自动补全,防止写错字符):
java -jar selenium-server-4.5.0.jar hub
启动后的命令窗口页面:

成功后用浏览器访问页面(http://127.0.0.1:4444),此时是没有服务被监听的,需要添加node节点才行:

Node(执行测试的节点)
Node 是 Selenium Grid 中的工作节点,负责实际执行测试用例。一个 Grid 中可以有多个 Node,每个 Node 都可以运行在不同的机器上,甚至可以具有不同的操作系统和浏览器组合。
启动命令(打开CMD命令窗口运行以下命令,要在jar包所在的目录运行命令才可,否则的话要给出jar存放的路径,包名最好使用Tab自动补全,防止写错字符):
java -jar selenium-server-4.5.0.jar node # 可以通过不同的端口号,启动多个node节点 # 示例: java -jar selenium-server-4.5.0.jar node --port 6666
启动后的命令窗口页面:

成功后用浏览器访问页面(http://127.0.0.1:4444),会发现添加了node节点到hub中心监控平台:

启动成功后,需要在脚本中对浏览器对象进行配置(将WebDriver指向到启动的监听服务):
from selenium import webdriver
chrome_options = webdriver.ChromeOptions()
driver = webdriver.Remote(
command_executor='http://127.0.0.1:4444',
options=chrome_options
)
创建简单的自动化用例(利用pytest框架中的多线程并发运行的模式):
import time
import pytest
from selenium import webdriver
chrome_options = webdriver.ChromeOptions()
driver = webdriver.Remote(
command_executor='http://127.0.0.1:4444',
options=chrome_options
)
def testcase01():
driver.get("http://www.baidu.com")
driver.find_element("id", "kw").send_keys("Selenium Grid")
time.sleep(10)
driver.quit()
def testcase02():
driver.get("http://www.baidu.com")
driver.find_element("id", "kw").send_keys("Selenium Grid")
time.sleep(10)
driver.quit()
def testcase03():
driver.get("http://www.baidu.com")
driver.find_element("id", "kw").send_keys("Selenium Grid")
time.sleep(10)
driver.quit()
if __name__ == '__main__':
pytest.main(['-n', '3'])
通过浏览器访问 Grid 的控制台,查看测试的执行情况和结果(运行用例的时候,打开Grid 的控制台进行查看):

Hub and Node在不同的机器上配置
在其他服务器上执行添加的命令(要把监听服务指向主控制节点,并且要确保两者的ip可以互相ping通才行):
java -jar selenium-server-4.5.0.jar node --hub http://{主控制节点的IP}:4444
其他服务器上命令启动的页面:

添加成功后的页面:
创建简单的自动化用例(利用pytest框架中的多线程并发运行的模式):
import time
import pytest
from selenium import webdriver
chrome_options = webdriver.ChromeOptions()
driver = webdriver.Remote(
command_executor='http://127.0.0.1:4444',
options=chrome_options
)
def testcase01():
driver.get("http://www.baidu.com")
driver.find_element("id", "kw").send_keys("Selenium Grid")
time.sleep(10)
driver.quit()
def testcase02():
driver.get("http://www.baidu.com")
driver.find_element("id", "kw").send_keys("Selenium Grid")
time.sleep(10)
driver.quit()
def testcase03():
driver.get("http://www.baidu.com")
driver.find_element("id", "kw").send_keys("Selenium Grid")
time.sleep(10)
driver.quit()
def testcase04():
driver.get("http://www.baidu.com")
driver.find_element("id", "kw").send_keys("Selenium Grid")
time.sleep(10)
driver.quit()
def testcase05():
driver.get("http://www.baidu.com")
driver.find_element("id", "kw").send_keys("Selenium Grid")
time.sleep(10)
driver.quit()
def testcase06():
driver.get("http://www.baidu.com")
driver.find_element("id", "kw").send_keys("Selenium Grid")
time.sleep(10)
driver.quit()
if __name__ == '__main__':
pytest.main(['-n', '6'])
运行时的页面: 文章来源:https://www.toymoban.com/news/detail-849287.html
文章来源:https://www.toymoban.com/news/detail-849287.html
结语
Selenium Grid 提供了强大的分布式测试能力,使测试人员能够更高效地执行测试,并确保应用程序在不同环境和配置下的稳定性。通过理解 Selenium Grid 的核心特性、工作原理以及正确的配置和使用方法,您可以充分利用这一强大工具,提升测试效率和覆盖范围。在日益复杂和多样化的 web 应用环境中,Selenium Grid 是确保软件质量的重要工具之一。文章来源地址https://www.toymoban.com/news/detail-849287.html
到了这里,关于Python中的分布式运行:Selenium Grid的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!