本专栏仅为本人学习研读体会分享,以及实际完成的测试代码。更加详细内容详见该书。
1.1 走进语音识别
1.1.1语音识别的定义
定义:语音识别是让机器具备自动接收和分析人类的语音,并最终输出对应文本的过程。
目标:将输入语音转化为文字的输出
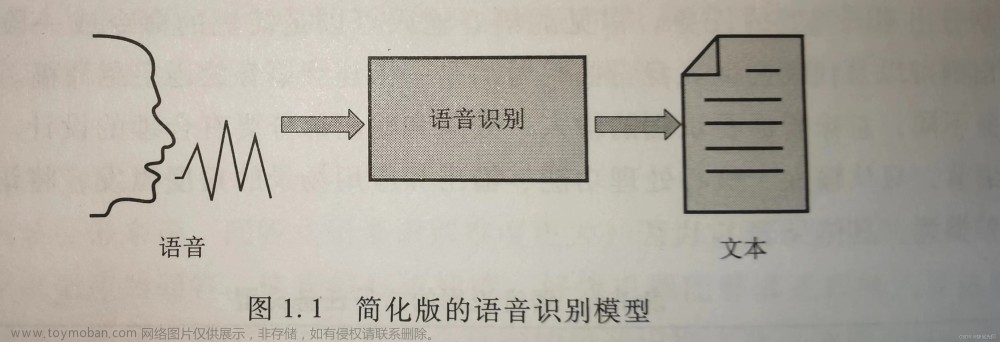
目标实现条件:
提前规定好该系统可以接收的语音输入形式,比如单个词、命令短语和连续语音。
对应的文本输出形式,可以直接翻译出来的对应文本,也可以是经过编码的特殊字符,比如组成发音的基本单位——音素。由此可知,系统的输入和输出不同,决定了语音识别的任务是多种多样的。核心模块包括:
A. 接收输入语音的麦克风设备
B. 负责自动分析语音信号的程序
C. 完成语音到文字的翻译程序
D. 将最终语音到文字的翻译程序
1.1.2 语音识别任务的分类
分类依据:应用场景中的不同任务、从研究者的实现目标
(1) 从应用者角度的分类
【根据输入语音类型和输出文本形式不同】:
| 编号 | 任务类型 | 输入 | 核心功能 | 输出 | 应用场景 |
| 1 | 命令式 | 特定命令的关键词语音 | a.识别唤醒关键词 b.识别命令关键词,搜索程序并控制设备上的程序 c.识别命令并搜索相关业务 d.分析说话人的语音特征并搜索可能的身份 |
a.程序的工作/休眠状态 b.设备上的程序名称或类型,以及相关状态 c.业务名称或类型 d.身份编码 |
a.程序的唤醒 b.操控设备 c.银行业务系统 d.声纹安保系统 |
| 2 | 实时转译 | 一段连续的语音 | 分析和识别语音所表达的文字信息 | 语音对应的文字稿 | a.输入法中的语音输入,文字输出 b.视频加字幕 c.会议实时记录 |
| 3 | 问答式 | 多次口语提问 | 识别每一次提问,搜索可能的回答 | 定制化的文字回答 | a.手机语音助手 b.手机导航 c.机器人助手 |
(2)从研究者角度分类
A. 根据说话的内容不同:孤立词、连接词和连续语音识别
a. 孤立词——要求输入的每个词要有停顿
b.连接词——要求输入的每个词都要吐字清楚,会存在一些连音
c.连续语音——自然状态下的句子输入,会有大量的连音和变音
B.根据说话人的不同:特定人、非特定人,以及多人识别系统
a. 特定人——专门识别某个特定的人
b.非特定人——只强调对语音信号的分析,与发音者无关,要求模型对不同人的语音进行学习
c. 多人识别系统——对目标组内的语音进行分析,最终要能识别出组内人的语音
1.1.3 语音识别是一门交叉学科
(1)语音学
声音的记录和合成(包括麦克风技术和信号处理技术)——过滤背景音、消除混响、突出主体声音
(2)语言学
对语言产生的机制进行了解: 发音规律、句子构成
(3)统计和概率论
都是基于统计学中的概率理论实现的:贝叶斯概率模型(优化器、分类器)、最大似然估计、HMM模型和LSTM模型
(4)数字信号处理
波形图转化为向量和矩阵的形式——>向量则主要通过MFCC的变换得出特征向量
同时,还包括编码和解码的知识
(5)算法式编程
包括python、 R、 matlab
(6)模式识别
语音识别属于模式识别
(7)机器学习
传统机器学习、深度学习
(8)嵌入式开发
将语音识别程序写入DSP芯片,所以要用到C,因为要接触底层硬件操控
(9)框架式编程
Kaldi——清华大学
讯飞开放平台——科大讯飞
HTK——微软
Google Speech API——谷歌
1.1.4 语音识别的应用
(1)自动生成文稿
语音输入法、会议记录、给视频加字幕
(2)人机交互
语音唤醒、自动驾驶、商场导航机器人、语音操控设备、智能音箱
(3)问答式语音助手
语音助手、机器人客服、智能机器人
(4)保安系统
(5)语音合成
1.2发展概况
总体来说两个阶段:
一、模拟人类发音,记录语音和合成语音
二、对语音信号的解析,并逐步将分析的过程自动化
1.2.1 人工语音识别
(1)孤立词的语音合成
A.模仿肺部呼吸的压力腔;
B.声带的震动弹簧;
C.一个皮革制的管道模仿声音传输
(2)连续语音的记录和合成
一个听筒,用于接收说话人的语音,通过内部的传声管,可以自动操控另一头的刻画机,随着说话,将这些信息以字符的形式被一行行地雕刻在转轴的蜡桶上
A. 听写机
B. 蜡桶
C.回放机
D.打磨机——重复使用刮去蜡桶上的记录
(3)听写机的先进性与不足
人类发明的以机械手段收集语音信号和保存语音信息方面的重大贡献。1889-1930爱迪生发明了一系列听写机,投入商用30年——机械化语音合成技术时代
(4)电子语音合成技术
1906年真空三极管的发明为标志
1930年实现了将声音信息刻画到塑料制成的光盘和磁带上。
1.2.2 自动化语音识别
20世纪50年代,1952年Bell实验室的Audrey系统,做到了机器自动识别特定说话人发出的数字语音。
(1)技术突破
A. 第一阶段(1950-1960年)
Audry发明
B. 第二阶段(1960-1979年)
语音编码算法,如:LPC(linear predictive coding)、DTW(dynamic time warping),卡内基梅隆大学的亚历山大发明的Harpy
C.第三个阶段(1980-2007年)
1987年随着语言模型N-gram被引入语音识别系统中,才开始识别连续语音。1992年黄雪冬发明的Sphinx-II
IBM发明的Tangora系统使用HMM表示语音信号,MHH直到2000年仍是当时最流行的算法之一。知道长短记忆网络LSTM的出现,世界上第一个连续语音识别器正式诞生。
D.(2008年至今)
机器学习,尤其是深度学习发展为语音识别技术带来了很大突破。2010苹果公司Siri语音助手
深度学习模型DNN融合MHH形成DNN-MHH
端到端(end-to-end)语音识别系统成为最新的技术趋势,免除了GMM-HMM模型中训练三音素的过程
(2)典型的声学模型和算法
目前语音识别系统的实现框架以机器学习算法为核心,通常需要经过训练和应用两个必要的阶段。
如下图:
训练阶段——针对语音数据的声学模型、针对文本数据的语言模型
应用阶段——针对当前输入的语音,采用同样的特征提取发,产生语音的特征向量并表示。在这种特征表示的基础上,应用训练好的声学模型、发音字典和语言模型,并结合搜索算法,找到特征对应的最佳文本匹配。

A. 声学模型
当语音信号输入后,第一个任务就是特征提取,目的是将原始语音的信号以少量的数据向量表示——数据降维。作为训练数据。
B.语言模型
准备一个文本数据库,根据一些规则训练一个语言模型。(一个单词在一句话中的顺序、位置、语法构成)
C.发音字典和搜索算法
为了找到发音和文本的对应关系,需要用到一个包含所有发音的字典;同时,为了完成发音和文本之间的匹配关系,还要用到搜索算法。最终才能实现语音和文本的唯一映射。
结合上图,模型和算法的产出,以音素为声学建模单位,语音识别中各个处理模块的具体描述:
A.语音数据是一个经过PCM编码的.WAV格式的文件
B.特征提取的结果是一组向量,比如(0.1,0.3,0.4,0.7......0.9)
C. 声学模型是指根据特征向量,得出音素的表示序列。即已知(0.1,0.3,0.4,0.7......0.9),得出ni3hen3piao4liang0
D.字典是发音顺序到文字的一一映射:尼ni2,你ni3,狠hen3.....
E. 语言模型是从候选的文字中找出概率最大的字符串序列:你0.072,你很0.634,票0.056,漂0.045,漂亮0.768
F. 通过结合语言模型和搜索算法,得出最终的输出文本为“你很漂亮”
(3)常见的声学模型
现在主流观点认为,语音识别可以根据采用声学模型方法的不同,将语音识别技术分为三类:
A. 基于HMM(隐马尔可夫)的声学模型
HMM能很好地体现语音信号在一段时间内的变化特征,因此目前仍有一些公司采用HMM作为建立声学模型的主要方法。实验证明,以HMM为主的语音识别框架即使在数据量不足的情况下,也能取得较好的识别效果。随着数据量的增加,能加强声学哦行的鲁棒性。
B. 基于深度学习的声学模型
通过神经网络结构自动计算特征并完成声学模型的建立;免去了特征那个提取的先验知识,取而代之的是,直接将语音信号的频率变换结果(即傅里叶变换后的结果)直接作为神经网络输入数据,经过多隐藏层的计算得出不同级别的特征,通过多轮训练得出不同特征的权值,最终采用最佳的网络完成声学模型的构建
C.基于端到端的算法(end-to-end)
端到端是比前两种方法要高级的一些算法。一端是音频序列的输入,一端是文字序列的输出,其中省去了声学模型和语言模型的对应。目前端到端算法包括CTC和基于注意力机制的编码-解码算法。
虽然端到端语音识别模型不再需要单独训练声学模型和语言模型,实现过程比较简单。但是在一些复杂场景下,其识别结果不够稳定。
1.3 面临的挑战
通用场景的精确识别和非特定人的识别技术尚不成熟。总的来看,目前面临的挑战可以分为以下五个方面:
(1)语音信号自身体现出的复杂性;
(2)分析语音信号的模型也存在无法避免的弊端
(3)麦克风阵列和GPU运算等硬件设备发展遇到的问题
(4)应用场景提出的巨大挑战;
(5)收集语音的数据会涉及人们的隐私,引发伦理问题
1.3.1 语音信号的复杂性
(1)说话人的差异
不同在于发音器官、口音、说话风格的影响。为了对齐到固定长度的文本,发明了DTW(dynamic time warping,动态时间规整)算法。该技术主要用于识别孤立词。
(2)噪声影响
此为目前最大难题
1.3.2机器学习模型的局限性
(1)大数据不完全可靠
(2)深度学习“黑箱”操作
A. 无法分辨出哪一层的特征是关键的,无法准确知道一共需要多少层;
B.无法确定出错的原因;
C. 面对未知数据,束手无策
1.3.3 硬件设备的制约
(1)麦克风
(2)高算力的GPU
1.3.4 应用场景的复杂性
在下面三个场景中,语音识别仍然面临巨大挑战:
(1)含有专业词汇的听写应用
(2)问答式应用
无法正确理解人类意思
(3)远场识别文章来源:https://www.toymoban.com/news/detail-849336.html
1.3.5伦理问题
下一篇:《语音识别模式、算法设计与实践》——第二章 必知必会的数学基础知识——向量与矩阵文章来源地址https://www.toymoban.com/news/detail-849336.html
到了这里,关于《语音识别模式、算法设计与实践》——第一章 语音识别概述的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!












