目录
前言
A.建议
B.简介
一 代码实现
二 时空复杂度
A.时间复杂度:
B.空间复杂度:
C.总结:
三 优缺点
A.优点:
B.缺点:
四 现实中的应用
前言
A.建议
1.学习算法最重要的是理解算法的每一步,而不是记住算法。
2.建议读者学习算法的时候,自己手动一步一步地运行算法。
B.简介
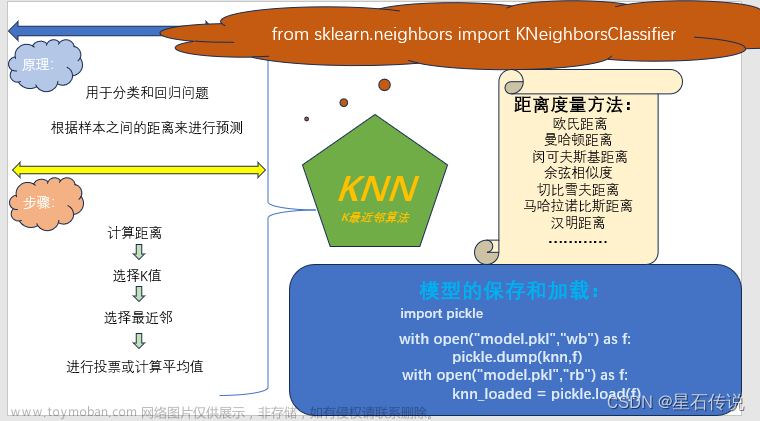
k最近邻(K-Nearest Neighbor, KNN)算法是一种基于实例的学习方法,主要用于分类和回归问题。在机器学习中,它不预先假设数据分布模型,而是直接存储训练样本,并在预测阶段根据新样本与已有训练样本之间的相似度进行决策。
一 代码实现
使用C语言实现K最近邻(K-Nearest Neighbor, KNN)算法通常涉及以下步骤:
定义数据结构: 首先,需要定义存储训练样本和测试样本的数据结构。这可能包括特征向量、类标签以及用于计算距离的函数指针等。
typedef struct {
double *features; // 特征向量,例如double features[N_FEATURES];
int label; // 类别标签
} Sample;
// 假设我们已经有了一个预处理好的样本集
Sample trainingSet[TRAINING_SET_SIZE];计算距离: 选择一种距离度量方法,如欧氏距离或曼哈顿距离,并编写函数来计算测试样本与每个训练样本之间的距离。
double euclideanDistance(Sample s1, Sample s2) {
int i;
double distance = 0.0;
for (i = 0; i < N_FEATURES; ++i) {
distance += pow(s1.features[i] - s2.features[i], 2);
}
return sqrt(distance);
}
// 或者用曼哈顿距离
double manhattanDistance(Sample s1, Sample s2) {
int i;
double distance = 0.0;
for (i = 0; i < N_FEATURES; ++i) {
distance += abs(s1.features[i] - s2.features[i]);
}
return distance;
}排序邻居: 对于给定的测试样本,计算它与所有训练样本的距离,并根据距离从近到远排序。
#include <stdlib.h>
#include <stdio.h>
// 假设有函数对距离进行排序
void sortSamplesByDistance(Sample* samples, double* distances, int n) {
// 这里应实现一个快速排序、归并排序或其他合适算法对distances数组进行排序,并相应调整samples顺序
}
// 应用排序函数
Sample sortedNeighbors[TRAINING_SET_SIZE];
double distances[TRAINING_SET_SIZE];
for (int i = 0; i < TRAINING_SET_SIZE; ++i) {
distances[i] = euclideanDistance(testSample, trainingSet[i]);
}
sortSamplesByDistance(trainingSet, distances, TRAINING_SET_SIZE);确定K个最近邻及其类别: 取出排序后最近的K个邻居,并统计各个类别的出现次数。
int classCounts[NUM_CLASSES] = {0};
for (int k = 0; k < K_VALUE; ++k) {
int currentClass = sortedNeighbors[k].label;
classCounts[currentClass]++;
}
// 找到出现次数最多的类别
int predictedClass;
int maxCount = 0;
for (int c = 0; c < NUM_CLASSES; ++c) {
if (classCounts[c] > maxCount) {
maxCount = classCounts[c];
predictedClass = c;
}
}完整代码示例: 下面是一个简化的KNN分类器的整体框架,但请注意,实际应用中还需要考虑边界检查、内存管理、更高效的搜索策略(如kd树或球树)以及异常处理等问题。
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#define N_FEATURES 10 // 示例特征数量
#define TRAINING_SET_SIZE 1000 // 示例训练集大小
#define K_VALUE 5 // K值
typedef struct {
double features[N_FEATURES];
int label;
} Sample;
double euclideanDistance(Sample s1, Sample s2) {/* 实现欧氏距离计算 */}
void knnClassifier(Sample testSample, Sample trainingSet[], int numTrainingSamples, int K) {
double distances[numTrainingSamples];
Sample sortedSamples[numTrainingSamples];
// 计算距离并排序
for (int i = 0; i < numTrainingSamples; ++i) {
distances[i] = euclideanDistance(testSample, trainingSet[i]);
}
// 这里假设已有一个排序函数
sortDistancesAndSamples(distances, sortedSamples, trainingSet, numTrainingSamples);
// 统计K个最近邻的类别
int classCounts[NUM_CLASSES] = {0};
for (int k = 0; k < K; ++k) {
int currentClass = sortedSamples[k].label;
classCounts[currentClass]++;
}
// 确定预测类别
int predictedClass = findMaxCountClass(classCounts);
printf("Predicted class: %d\n", predictedClass);
}
int main() {
// 初始化训练集、加载测试样本
// ...
Sample testSample;
// 假设testSample已经被初始化
knnClassifier(testSample, trainingSet, TRAINING_SET_SIZE, K_VALUE);
return 0;
}上述代码仅为说明目的,并未提供完整的排序和查找最大计数类别的函数实现。在实际编程时,请根据项目需求和实际情况完善这些部分。
二 时空复杂度
A.时间复杂度:
-
训练阶段: KNN算法在训练阶段并不需要构建模型,只是简单地存储训练数据,因此训练时间复杂度为,即与训练样本的数量无关。
-
预测阶段:
- 对于每一个待分类或回归的新样本,KNN都需要计算其与所有训练样本的距离。在最坏的情况下,对于每个新样本,计算个训练样本的距离所需的时间复杂度是,其中n表示训练集中的样本数量,表示特征维度。
- 找出k个最近邻,通常需要对距离进行排序,这在没有优化的情况下时间复杂度是,但实际应用中我们往往只需要找出前小的距离,可以使用优先队列等方法将这一部分的时间复杂度降低至近似。
- 因此,总的预测时间复杂度是
或者采用更高效的数据结构和算法后可能是
。
B.空间复杂度:
-
训练阶段: KNN算法需要存储所有的训练样本及其对应的标签,所以空间复杂度为O(n*d),其中n是训练样本数,d是每个样本的特征维度。
-
预测阶段: 在预测过程中,除了存储训练数据之外,可能还需要额外的空间来存储中间结果,如距离矩阵、优先队列等,但这一般相对于存储训练数据所需的内存来说较小。
C.总结:
- KNN算法在大数据集上运行时可能会非常耗时,特别是当特征维度很高时。
- 空间复杂度较高,因为必须存储整个训练集以供查询,这对于大规模数据集是一个明显的挑战。
- 可以通过诸如KD树、球树等数据结构来优化搜索过程,减少不必要的距离计算,从而改善时间复杂度,尤其是在低维到中等维度空间中效果显著。但在高维空间中,由于所谓的“维数灾难”,这些优化的效果会大打折扣。
三 优缺点
A.优点:
-
简单直观:KNN算法概念简单,易于实现和理解。它是一种非参数方法,不需要对数据进行复杂的建模。
-
理论成熟:适用于多种类型的数据集,无论是数值型还是离散型特征,都可以处理分类和回归问题。
-
可适应性强:无需预先假设数据分布,对于复杂或非线性边界的数据集表现良好。
-
可用于大规模数据集:尽管计算复杂度随数据量增大而增加,但在有足够内存的情况下,理论上可以处理任意大小的训练集。
-
在线学习:随着新样本的出现,可以直接将其添加到训练集中,无需重新训练模型。
-
无数据输入假定:对于异常值不太敏感,因为它是基于实例的学习,而不是基于概率统计模型。
-
多类别处理:天然支持多类别分类任务,通过多数表决或加权投票机制确定类别。
B.缺点:
-
计算复杂度高:在预测阶段,计算一个新样本与所有训练样本的距离是非常耗时的,尤其当样本数n很大时,时间复杂度为O(n*d),其中d是特征维度。
-
空间复杂度大:需要存储整个训练集,占用大量内存资源,空间复杂度为O(n*d)。
-
对样本数量不均衡的问题敏感:如果不同类别的样本数量差异悬殊,在做决策时容易偏向于样本多的类别。
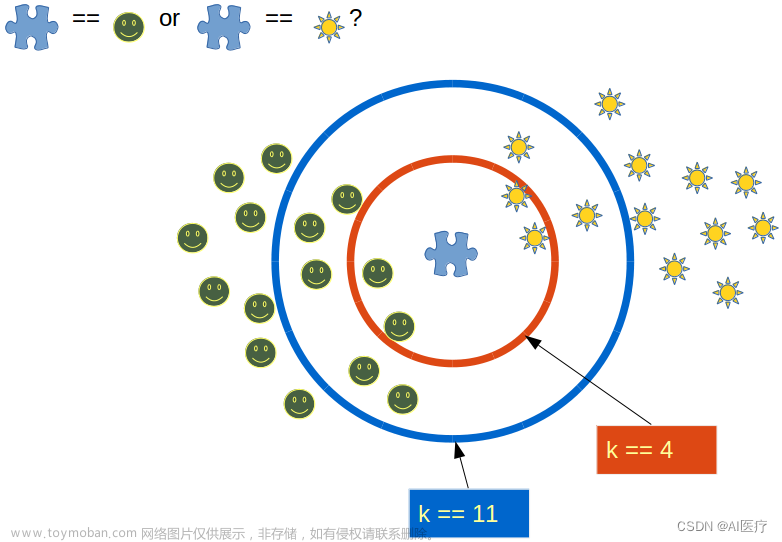
-
选择k值困难:k值的选择直接影响模型性能,过小可能导致模型过拟合噪声,过大可能使得模型过于平滑,边界模糊不清。
-
不适合大规模高维数据集:随着维度的增加,“维数灾难”现象会变得严重,距离计算的效果会减弱,且搜索最近邻所需的时间显著增加。
-
对连续属性的处理:未经过特征缩放的连续属性可能会比其他属性更主导距离计算结果,从而影响最终预测准确性。
-
不适用于实时预测:由于每次预测都需要遍历整个训练集,对于实时应用或者要求快速响应的场景,KNN并不高效。
四 现实中的应用
-
图像识别与计算机视觉:
- KNN用于图像分类任务,例如区分不同种类的植物、动物或物体。通过计算新图像特征向量与训练集中图像特征的距离,找出最接近的k个邻居,根据这些邻居的类别来预测新图像所属类别。
-
医疗诊断:
- 在医学影像分析中,KNN可以用来辅助医生进行疾病诊断,如通过对病理切片图像的特征提取后使用KNN分类器来判断肿瘤的良恶性。
- 生物信息学中,利用基因表达数据或其他生物标志物特征,KNN可帮助预测病人的疾病类型或预后。
-
推荐系统:
- KNN常被应用于协同过滤推荐算法中,通过找到用户历史行为记录中最相似的k个邻居用户,然后推荐他们喜欢的商品或服务给目标用户。
-
手写字符识别:
- 对于手写数字或字母的识别问题,KNN可以根据特征向量之间的距离确定输入图案最可能对应的手写字符。
-
金融风控:
- 在信贷审批中,KNN可用于信用评分模型,通过分析客户的类似属性(如收入、年龄、职业等),预测潜在的违约风险。
-
地理信息系统(GIS):
- 在地理数据分析中,KNN可用于查找邻近的服务设施、进行空间聚类分析,或者进行地理定位时提供“附近地点”推荐。
-
农业和环境科学:
- 利用气象数据和其他作物生长相关特征,KNN可用于预测农作物产量或病虫害发生的可能性。
-
市场细分与客户分类:文章来源:https://www.toymoban.com/news/detail-849551.html
- 市场营销中,根据客户购买历史、人口统计学特征等因素,KNN可以帮助划分客户群体,实现更精准的产品推广和服务定制。
-
语音识别:文章来源地址https://www.toymoban.com/news/detail-849551.html
- 在语音信号处理中,KNN可以用于将未知声音片段与已知库中的样本进行匹配,从而识别出说话者或翻译成文本。
到了这里,关于C语言经典算法之k最近邻(K-Nearest Neighbor, KNN)算法的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!