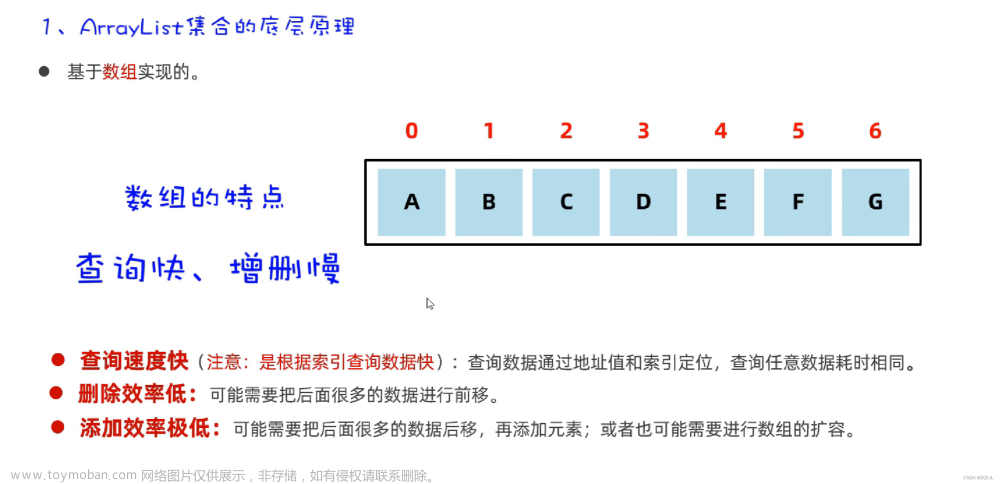
JDK版本为1.8.0_271,以插入和删除元素为例,LinkedList部分源码如下:
//属性,底层结构为双向链表
transient Node<E> first; //记录第一个结点的位置
transient Node<E> last; //记录最后一个结点的尾元素
transient int size = 0; //记录链表的元素个数
//内部Node类定义如下
private static class Node<E> {
E item; //节点数据
Node<E> next; //下一个结点
Node<E> prev; //前一个结点
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
//构造器
public LinkedList() {
}
//方法:add()相关方法
public boolean add(E e) {
linkLast(e); //默认把新元素链接到链表尾部
return true;
}
// 尾部插入一个新节点
void linkLast(E e) {
final Node<E> l = last; //用 l 记录原来的最后一个结点
//创建新结点
final Node<E> newNode = new Node<>(l, e, null);
//现在的新结点是最后一个结点了
last = newNode;
//如果l==null,说明原来的链表是空的
if (l == null)
//那么新结点同时也是第一个结点
first = newNode;
else
//否则把新结点链接到原来的最后一个结点的next中
l.next = newNode;
//元素个数增加
size++;
//修改次数增加
modCount++;
}
//方法:获取get()相关方法
public E get(int index) {
// 校验index是否越界,合法范围:[0,size)
checkElementIndex(index);
return node(index).item;
}
//方法:插入add()相关方法
public void add(int index, E element) {
checkPositionIndex(index); // 校验index是否越界,合法范围:[0,size)
if (index == size)//如果index==size,链接到当前链表的尾部
linkLast(element);
else
linkBefore(element, node(index));
}
// 查找index位置节点
Node<E> node(int index) {
// assert isElementIndex(index);
/*
index < (size >> 1)采用二分思想,先将index与长度size的一半比较,如果index<size/2,就只从位置0往后遍历到位置index处;如果index>size/2,就只从位置size往前遍历到位置index处。这样可以减少一部
分不必要的遍历。
*/
//如果index<size/2,就从前往后找目标结点
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {//否则从后往前找目标结点
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
//把新结点插入到[index]位置的结点succ前面,succ是[index]位置对应的结点
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
final Node<E> pred = succ.prev; //[index]位置的前一个结点
//新结点的prev是原来[index]位置的前一个结点
//新结点的next是原来[index]位置的结点
final Node<E> newNode = new Node<>(pred, e, succ);
//[index]位置对应的结点的prev指向新结点
succ.prev = newNode;
//如果原来[index]位置对应的结点是第一个结点,那么现在新结点是第一个结点
if (pred == null)
first = newNode;
else
pred.next = newNode;//原来[index]位置的前一个结点的next指向新结点
size++;
modCount++;
}
//方法:remove()相关方法
public boolean remove(Object o) {
//分o是否为空两种情况
if (o == null) {
//找到o对应的结点x
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);//删除x结点
return true;
}
}
} else {
//找到o对应的结点x
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);//删除x结点
return true;
}
}
}
return false;
}
// 将节点x从链表中取下
E unlink(Node<E> x) {//x是要被删除的结点
// assert x != null;
final E element = x.item;//被删除结点的数据
final Node<E> next = x.next;//被删除结点的下一个结点
final Node<E> prev = x.prev;//被删除结点的上一个结点
//如果被删除结点的前面没有结点,说明被删除结点是第一个结点
if (prev == null) {
//那么被删除结点的下一个结点变为第一个结点
first = next;
} else {//被删除结点不是第一个结点
//被删除结点的上一个结点的next指向被删除结点的下一个结点
prev.next = next;
//断开被删除结点与上一个结点的链接
x.prev = null;//使得GC回收
}
//如果被删除结点的后面没有结点,说明被删除结点是最后一个结点
if (next == null) {
//那么被删除结点的上一个结点变为最后一个结点
last = prev;
} else {//被删除结点不是最后一个结点
//被删除结点的下一个结点的prev执行被删除结点的上一个结点
next.prev = prev;
//断开被删除结点与下一个结点的连接
x.next = null;//使得GC回收
}
//把被删除结点的数据也置空,使得GC回收
x.item = null;
//元素个数减少
size--;
//修改次数增加
modCount++;
//返回被删除结点的数据
return element;
}
// 删除index位置的节点
public E remove(int index) { //index是要删除元素的索引位置
// 校验index范围
checkElementIndex(index);
// 将节点x从链表中取下
return unlink(node(index));
}
// 插入新节点链表头结点
public void addFirst(E e) {
linkFirst(e);
}
// 链接节点到链表头
private void linkFirst(E e) {
final Node<E> f = first; // 获取链表头节点
final Node<E> newNode = new Node<>(null, e, f); // 新建节点
first = newNode; // 更新头结点
if (f == null) // 原链表为空时
last = newNode; // 将链表last指向新的头结点
else
// 双端链表,将原头结点的prev指向新的头结点
f.prev = newNode;
size++; // 链表节点数+1
modCount++; // 链表修改次数+1
}
// 获取链表的头结点的元素
public E getFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return f.item;
}
// addLast尾插法插入节点,getLast获取链表尾结点
插入删除结点的过程如图所示:
- 只有1个元素的LinkedList

- 包含4个元素的LinkedList

- add(E e)方法

- add(int index,E e)方法

- remove(Object obj)方法
 文章来源:https://www.toymoban.com/news/detail-849773.html
文章来源:https://www.toymoban.com/news/detail-849773.html
- remove(int index)方法
 文章来源地址https://www.toymoban.com/news/detail-849773.html
文章来源地址https://www.toymoban.com/news/detail-849773.html
到了这里,关于LinkedList部分底层源码分析的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!