框架
- spring cloud
- spring cloud alibaba
Eureka
- eureka-server
- 注册中心
- eureka-client
- 客户端
- 每30s发送心跳
- 服务
- 服务消费者
- 服务提供者
server
依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>
启动类
- 添加注解
- @EnableEurekaServer
配置文件
- application.yml
server:
port: 10086 # 端口号
spring:
application:
name: eurekaserver # eureka服务名称
eureka:
client:
service-url: # eureka的地址,需要将自己注册到eureka中
defaultZone: http://127.0.0.1:10086/eureka
client
依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
配置文件
- application.yml
spring:
application:
name: userservice # 需要注册的服务名称
eureka:
client:
service-url: # 本服务地址,需要注册到eureka中
defaultZone: http://127.0.0.1:10086/eureka
服务拉取和负载均衡
- 添加注解
- @LoadBlanced
@Bean
@LoadBlanced // 负载均衡
public RestTemplate restTemplate(){
return new RestTemplate();
}
- 修改url
// restTemplate请求
String url = "http://userservice/xxx";
Ribbon负载均衡
自定义负载均衡策略
1、定义新的IRule,将轮询策略(默认)变成随机策略
@Bean
public IRule randomRule(){
return new RandomRule();
}
2、配置文件方式
userservice: # 给某个微服务配置负载均衡规则,这里是userservice服务
ribbon:
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule # 负载均衡规则
饥饿加载
-
默认懒加载
- 第一次访问时才会去创建LoadBalanceClient
-
开启饥饿加载
ribbon:
eager-load:
enabled: true
clients: userservice
Nacos
依赖
- 父工程
<dependencyManagement>
<dependencies>
<!--springcloud-->
<!--mysql-->
<!--mybatis plus-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>2.2.6.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
- 客户端
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
spring:
cloud:
nacos:
server-addr: localhost:8848
配置集群
优先选择本地集群
- 添加集群
spring:
cloud:
nacos:
server-addr: localhost:8848
discovery:
cluster-name: xx # 集群名称
- 修改负载均衡规则
userservice:
ribbon:
NFLoadBalancerRuleClassName: com.alibaba.cloud.nacos.ribbon.NacosRule # 负载均衡规则
配置权重
- nacos控制台->实例列表->编辑->修改权重
环境隔离
- Namespace
- Group
- service/data
- Group
配置namespace
- 需要新建namespace
- 修改配置
spring:
cloud:
nacos:
server-addr: localhost:8848
discovery:
cluster-name: xx
namespace: xxxx # 命名空间,填ID
永久实例
- 临时实例
- 果实例宕机超过一定时间,会从服务列表剔除
- 非临时实例/永久实例
- 实例宕机,不会从服务列表剔除
spring:
cloud:
nacos:
discovery:
ephemeral: false # 设置为非临时实例
配置管理
- data id
- xxx-dev.yaml
- group
- default_group
- 配置内容
- 需要热更新的配置有必要放到nacos管理
- 基本不会变更的一些配置保存在微服务本地
依赖
<!--nacos配置管理依赖-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
bootstrao.yaml
spring:
application:
name: userservice # 服务名称
profiles:
active: dev #开发环境
cloud:
nacos:
server-addr: localhost:8848 # Nacos地址
config:
file-extension: yaml # 文件后缀名
配置热更新
-
方式一
- 添加注解
- @RefreshScope
- 添加注解
-
方式二
- @ConfigurationProperties代替@Value
@Component
@Data
@ConfigurationProperties(prefix = "xx")
public class Xxxx {
private String xx;
}
配置共享
-
创建[servename].yaml
- 多环境共享
-
配置文件组成
- [spring.application.name]-[spring.profiles.active].yaml
- 运行环境
- [spring.application.name].yaml
- 公共
- [spring.application.name]-[spring.profiles.active].yaml
配置优先级
- [spring.application.name]-[spring.profiles.active].yaml
- [spring.application.name].yaml
- 本地配置
feign
使用
依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
Application添加注解
- @EnableFeignClients
客户端
@FeignClient("xxxservice")
public interface XxxClient {
}
自定义配置
- 区分全局和单个服务
- feign.client.config.xxservice.loggerLevel
- xxservice服务
- feign.client.config.default.loggerLevel
- 全局
- feign.client.config.xxservice.loggerLevel
- feign.Logger.Level
- 修改日志级别
- NONE
- BASIC
- HEADERS
- FULL
- 修改日志级别
- feign.codec.Decoder
- 响应结果的解析器
- http远程调用的结果做解析
- 解析json字符串为java对象
- 响应结果的解析器
- feign.codec.Encoder
- 请求参数编码
- 将请求参数编码
- 便于通过http请求发送
- 请求参数编码
- feign.Contract
- 支持的注解格式
- 默认是SpringMVC的注解
- 支持的注解格式
- feign.Retryer
- 失败重试机制
使用优化
- 日志级别尽量用basic
- HttpClient或OKHttp代替URLConnection
- Feign底层发起http请求
- URLConnection
- 默认实现,不支持连接池
- Apache HttpClient
- 支持连接池
- OKHttp
- 支持连接池
- URLConnection
- Feign底层发起http请求
替换为httpclient
- 依赖
<dependency>
<groupId>io.github.openfeign</groupId>
<artifactId>feign-httpclient</artifactId>
</dependency>
- 配置文件
feign:
client:
config:
default: # default全局的配置
loggerLevel: BASIC # 日志级别,BASIC就是基本的请求和响应信息
httpclient:
enabled: true # 开启feign对HttpClient的支持
max-connections: 200 # 最大的连接数
max-connections-per-route: 50 # 每个路径的最大连接数
最佳实践
- 将Feign的Client抽取为独立模块
- 并且把接口有关的POJO、默认的Feign配置都放到这个模块中
- 在服务生产者、消费者中引入该模块
- 指定扫描接口
- @EnableFeignClients(clients = {XXXClient.class})
- @EnableFeignClients(basePackages = “xxx.clients”)
gateway
- 功能
- 身份认证和权限校验
- 服务路由、负载均衡
- 请求限流
搭建
- 依赖
<!--网关-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
<!--nacos服务发现依赖-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
- 启动类
@SpringBootApplication
public class GatewayApplication {
public static void main(String[] args) {
SpringApplication.run(GatewayApplication.class, args);
}
}
- 路由规则
server:
port: 10010 # 网关端口
spring:
application:
name: gateway # 服务名称
cloud:
nacos:
server-addr: localhost:8848 # nacos地址
gateway:
routes: # 网关路由配置
- id: user-service # 路由id,自定义,只要唯一即可
# uri: http://127.0.0.1:8081 # 路由的目标地址 http就是固定地址
uri: lb://userservice # 路由的目标地址 lb就是负载均衡,后面跟服务名称
predicates: # 路由断言,也就是判断请求是否符合路由规则的条件
- Path=/user/** # 这个是按照路径匹配,只要以/user/开头就符合要求
断言工厂
- 断言Path=/xx/**
- org.springframework.cloud.gateway.handler.predicate.PathRoutePredicateFactory处理
- 其他
- 时间断言
- After
- Before
- Between
- 请求
- Cookie
- Header
- Host
- Method
- Path
- Query
- RemoteAddr
- 权重
- Weight
- 时间断言
过滤工厂
-
种类
- AddRequestHeader
- 给当前请求添加一个请求头
- RemoveRequestHeader
- 移除请求中的一个请求头
- AddResponseHeader
- 给响应结果中添加一个响应头
- RemoveResponseHeader
- 从响应结果中移除有一个响应头
- RequestRateLimiter
- 限制请求的流量
- AddRequestHeader
-
局部添加
spring:
cloud:
gateway:
routes:
- id: user-service
uri: lb://userservice
predicates:
- Path=/user/**
filters: # 过滤器
- AddRequestHeader=xx, xxxxx # 添加请求头
- 全局添加
spring:
cloud:
gateway:
routes:
- id: user-service
uri: lb://userservice
predicates:
- Path=/user/**
default-filters: # 默认过滤项
- AddRequestHeader=xx, xxxxx
自定义全局过滤器
@Order(-1)
@Component
public class AuthorizeFilter implements GlobalFilter {
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
// 1.获取请求参数
MultiValueMap<String, String> params = exchange.getRequest().getQueryParams();
// 2.获取authorization参数
String auth = params.getFirst("authorization");
// 3.校验
if ("admin".equals(auth)) {
// 放行
return chain.filter(exchange);
}
// 4.拦截
// 4.1.禁止访问,设置状态码
exchange.getResponse().setStatusCode(HttpStatus.FORBIDDEN);
// 4.2.结束处理
return exchange.getResponse().setComplete();
}
}
过滤器顺序
- 过滤器必须指定一个order值
- order值越小,优先级越高,执行顺序越靠前
- order值一样时,会按照 defaultFilter > 路由过滤器 > GlobalFilter的顺序执行
跨域
spring:
cloud:
gateway:
# 。。。
globalcors: # 全局的跨域处理
add-to-simple-url-handler-mapping: true # 解决options请求被拦截问题
corsConfigurations:
'[/**]':
allowedOrigins: # 允许哪些网站的跨域请求
- "http://localhost:8090"
allowedMethods: # 允许的跨域ajax的请求方式
- "GET"
- "POST"
- "DELETE"
- "PUT"
- "OPTIONS"
allowedHeaders: "*" # 允许在请求中携带的头信息
allowCredentials: true # 是否允许携带cookie
maxAge: 360000 # 这次跨域检测的有效期
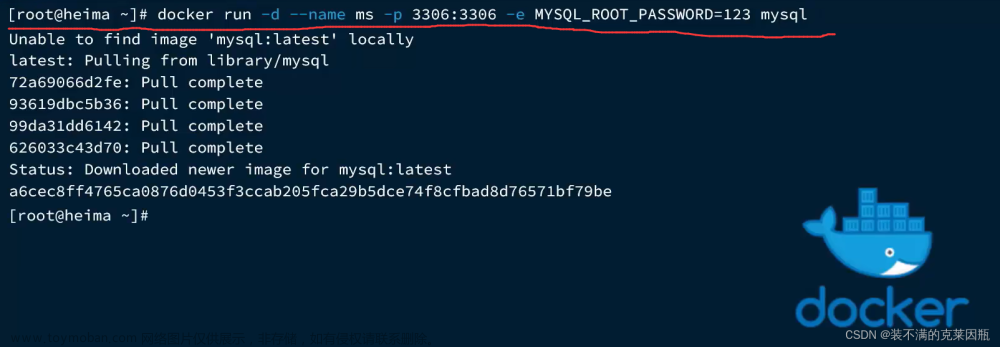
docker
-
架构
- 镜像
- image
- 容器
- container
- 镜像
-
dockerhub
- 镜像托管平台
-
docker
- client
- 向Docker服务端发送指令
- server
- Docker守护进程
- client
-
镜像名称
-
命令
- systemctl start docker
- systemctl stop docker
- systemctl restart docker
- docker -v
- docker --help
-
镜像命令
- docker pull 镜像
- docker push 镜像
- docker rmi 镜像
- docker images
- docker save -o xxx 镜像
- docker load -i xxx
-
容器命令
- docker run --name 容器名 -p 宿主机port:容器内port -d 镜像
- d:后运行
- docker pause
- docker unpause
- docker start
- docker stop
- docker logs -f 容器名
- f:持续
- docker ps
- docker exec -it 容器名 bash
- it:进去当前容器创建标准输入输出终端
- bash:进入后执行命令
- docker rm -f 容器名
- docker run --name 容器名 -p 宿主机port:容器内port -d 镜像
数据卷
-
volume
- 虚拟目录,指向宿主机文件系统中的某个目录
-
命令
- docker volume create
- docker volume inspect
- docker volume ls
- docker volume prune
- docker volume rm
-
挂载
- docker run -name mn -v xxxx:/xx/xx -p xx:xx xxx
- 宿主机目录可直接挂载
dockerfile
- 镜像结构
- 入口:镜像应用启动命令
- 层layer
- 基础镜像
- dockerfile
- 指令
- FROM
- ENV
- COPY
- RUN
- EXPOSE
- ENTRYPOINT
- 指令
dockercompose
- 功能
- 快速的部署分布式应用,无需手动一个个创建和运行
MQ
- MQ
- RabbitMQ
- ActiveMQ
- RocketMQ
- Kafka
RabbitMQ
- publisher:生产者
- consumer:消费者
- exchange个:交换机,负责消息路由
- queue:队列,存储消息
- virtualHost:虚拟主机,隔离不同租户的exchange、queue、消息的隔离
消息模型
- 基本消息队列
- 工作消息队列
- 发布订阅
- 广播
- 路由
- 主题
demo
ConnectionFactory factory = new ConnectionFactory();
// 1.1.设置连接参数,分别是:主机名、端口号、vhost、用户名、密码
factory.setHost("192.168.150.101");
factory.setPort(5672);
factory.setVirtualHost("/");
factory.setUsername("itcast");
factory.setPassword("123321");
// 1.2.建立连接
Connection connection = factory.newConnection();
// 2.创建通道Channel
Channel channel = connection.createChannel();
// 3.创建队列
String queueName = "simple.queue";
channel.queueDeclare(queueName, false, false, false, null);
// 4.发送消息
String message = "hello, rabbitmq!";
channel.basicPublish("", queueName, null, message.getBytes());
System.out.println("发送消息成功:【" + message + "】");
// 5.关闭通道和连接
channel.close();
connection.close();
// 1.建立连接
ConnectionFactory factory = new ConnectionFactory();
// 1.1.设置连接参数,分别是:主机名、端口号、vhost、用户名、密码
factory.setHost("192.168.150.101");
factory.setPort(5672);
factory.setVirtualHost("/");
factory.setUsername("itcast");
factory.setPassword("123321");
// 1.2.建立连接
Connection connection = factory.newConnection();
// 2.创建通道Channel
Channel channel = connection.createChannel();
// 3.创建队列
String queueName = "simple.queue";
channel.queueDeclare(queueName, false, false, false, null);
// 4.订阅消息
channel.basicConsume(queueName, true, new DefaultConsumer(channel){
@Override
public void handleDelivery(String consumerTag, Envelope envelope,
AMQP.BasicProperties properties, byte[] body) throws IOException {
// 5.处理消息
String message = new String(body);
System.out.println("接收到消息:【" + message + "】");
}
});
System.out.println("等待接收消息。。。。");
SpringAMQP
- 父工程依赖
<!--AMQP依赖,包含RabbitMQ-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
- 消息发送
spring:
rabbitmq:
host: localhost # 主机名
port: 5672 # 端口
virtual-host: / # 虚拟主机
username: xxx # 用户名
password: xxx # 密码
@Autowired
private RabbitTemplate rabbitTemplate;
@Test
public void testSimpleQueue() {
// 队列名称
String queueName = "simple.queue";
// 消息
String message = "hello, spring amqp!";
// 发送消息
rabbitTemplate.convertAndSend(queueName, message);
}
- 消息接收
spring:
rabbitmq:
host: localhost # 主机名
port: 5672 # 端口
virtual-host: / # 虚拟主机
username: xxx # 用户名
password: xxx # 密码
@RabbitListener(queues = "simple.queue")
public void listenSimpleQueueMessage(String msg) throws InterruptedException {
System.out.println("spring 消费者接收到消息:【" + msg + "】");
}
WorkQueue
让多个消费者绑定到一个队列,共同消费队列中的消息
- 消息发送
public void testWorkQueue() throws InterruptedException {
// 队列名称
String queueName = "simple.queue";
// 消息
String message = "hello, message_";
for (int i = 0; i < 50; i++) {
// 发送消息
rabbitTemplate.convertAndSend(queueName, message + i);
Thread.sleep(20);
}
}
- 消息接收
@RabbitListener(queues = "simple.queue")
public void listenWorkQueue1(String msg) throws InterruptedException {
System.out.println("消费者1接收到消息:【" + msg + "】" + LocalTime.now());
Thread.sleep(20);
}
@RabbitListener(queues = "simple.queue")
public void listenWorkQueue2(String msg) throws InterruptedException {
System.err.println("消费者2........接收到消息:【" + msg + "】" + LocalTime.now());
Thread.sleep(200);
}
- 取消消息预取
spring:
rabbitmq:
listener:
simple:
prefetch: 1 # 每次只能获取一条消息,处理完成才能获取下一个消息
发布订阅
fanout exchange
广播,将消息交给所有绑定到交换机的队列
- 声明队列和交换机
@Configuration
public class FanoutConfig {
/**
* 声明交换机
* @return Fanout类型交换机
*/
@Bean
public FanoutExchange fanoutExchange(){
return new FanoutExchange("itcast.fanout");
}
/**
* 第1个队列
*/
@Bean
public Queue fanoutQueue1(){
return new Queue("fanout.queue1");
}
/**
* 绑定队列和交换机
*/
@Bean
public Binding bindingQueue1(Queue fanoutQueue1, FanoutExchange fanoutExchange){
return BindingBuilder.bind(fanoutQueue1).to(fanoutExchange);
}
/**
* 第2个队列
*/
@Bean
public Queue fanoutQueue2(){
return new Queue("fanout.queue2");
}
/**
* 绑定队列和交换机
*/
@Bean
public Binding bindingQueue2(Queue fanoutQueue2, FanoutExchange fanoutExchange){
return BindingBuilder.bind(fanoutQueue2).to(fanoutExchange);
}
}
- 发布
// 队列名称
String exchangeName = "itcast.fanout";
// 消息
String message = "hello, everyone!";
rabbitTemplate.convertAndSend(exchangeName, "", message);
- 订阅
@RabbitListener(queues = "fanout.queue1")
public void listenFanoutQueue1(String msg) {
System.out.println("消费者1接收到Fanout消息:【" + msg + "】");
}
@RabbitListener(queues = "fanout.queue2")
public void listenFanoutQueue2(String msg) {
System.out.println("消费者2接收到Fanout消息:【" + msg + "】");
}
Direct
定向,把消息交给符合指定routing key 的队列
- 基于注解声明队列和交换机
@RabbitListener(bindings = @QueueBinding(
value = @Queue(name = "direct.queue1"),
exchange = @Exchange(name = "itcast.direct", type = ExchangeTypes.DIRECT),
key = {"red", "blue"}
))
public void listenDirectQueue1(String msg){
System.out.println("消费者接收到direct.queue1的消息:【" + msg + "】");
}
@RabbitListener(bindings = @QueueBinding(
value = @Queue(name = "direct.queue2"),
exchange = @Exchange(name = "itcast.direct", type = ExchangeTypes.DIRECT),
key = {"red", "yellow"}
))
public void listenDirectQueue2(String msg){
System.out.println("消费者接收到direct.queue2的消息:【" + msg + "】");
}
- 发布
@Test
public void testSendDirectExchange() {
// 交换机名称
String exchangeName = "itcast.direct";
// 消息
String message = "xxx";
// 发送消息
rabbitTemplate.convertAndSend(exchangeName, "red", message);
}
Topic
通配符,把消息交给符合routing pattern(路由模式) 的队列
- 发布
@Test
public void testSendTopicExchange() {
// 交换机名称
String exchangeName = "itcast.topic";
// 消息
String message = "xxx";
// 发送消息
rabbitTemplate.convertAndSend(exchangeName, "china.news", message);
}
- 订阅
@RabbitListener(bindings = @QueueBinding(
value = @Queue(name = "topic.queue1"),
exchange = @Exchange(name = "itcast.topic", type = ExchangeTypes.TOPIC),
key = "china.#"
))
public void listenTopicQueue1(String msg){
System.out.println("消费者接收到topic.queue1的消息:【" + msg + "】");
}
@RabbitListener(bindings = @QueueBinding(
value = @Queue(name = "topic.queue2"),
exchange = @Exchange(name = "itcast.topic", type = ExchangeTypes.TOPIC),
key = "#.news"
))
public void listenTopicQueue2(String msg){
System.out.println("消费者接收到topic.queue2的消息:【" + msg + "】");
}
消息序列化
- 依赖
<dependency>
<groupId>com.fasterxml.jackson.dataformat</groupId>
<artifactId>jackson-dataformat-xml</artifactId>
<version>2.9.10</version>
</dependency>
- 配置bean
@Bean
public MessageConverter jsonMessageConverter(){
return new Jackson2JsonMessageConverter();
}
- 发送对象
// 准备消息
Map<String,Object> msg = new HashMap<>();
msg.put("name", "Jack");
msg.put("age", 21);
// 发送消息
rabbitTemplate.convertAndSend("simple.queue","", msg);
- 接收
@RabbitListener(queues = "simple.queue")
public void listenSimpleQueueMessage(Map<String,Object> msg) throws InterruptedException {
System.out.println("spring 消费者接收到消息:【" + msg + "】");
}
elasticsearch
- 包含
- elasticsearch
- kibana 可视化界面
- ik分词器
- ik_smart
- 智能切分,粗粒度
- ik_max_word
- 最细切分,细粒度
- 可以配置扩展词和停用词条
- ik_smart
开源搜索引擎
- 倒排索引
- 文档(Document)
- 词条(Term)
- 索引(Index)
- 相同类型的文档的集合
- 索引当做是数据库中的表
- 映射(mapping)
- 索引中文档的字段约束信息
- 类似表的结构约束
- 文档(Document)
- 类似数据库中的行(Row)
- 字段(Field)
- 类似数据库中的列(Column)
- DSL
- JSON风格的请求语句,用来操作elasticsearch,实现CRUD
索引库操作
-
mapping
- type
- 字符串:text,keyword
- 数值:long,integer,short,byte,double,float
- 布尔:boolean
- 日期:date
- 对象:object
- index
- 是否创建索引
- 默认 true
- analyzer
- 使用哪种分词器
- properties
- 字段的子字段
- type
-
创建索引库
PUT /索引库名称
{
"mappings":{
"properties":{
"字段1":{
"type":"text",
"analyzer":"ik_smart"
},
"字段2":{
"type":"keyword",
"index":"false"
},
"字段3":{
"properties":{
"子字段1":{
"type":"keyword"
}
}
}
}
}
}
- 查询
GET /索引库名称
- 删除
DELETE /索引库名称
- 添加新字段
PUT /索引库名称/_mapping
{
"properties":{
"新字段名":{
"type":"integer"
}
}
}
文档操作
- 新增
POST /索引库名称/_doc/文档id
{
"字段1":"值1",
"字段2":"值2",
"字段3":"值3",
"字段4":{
"子字段1":"值"
}
}
- 查询
GET /索引库名称/_doc/id
- 删除
DELETE /索引库名称/_doc/id
- 修改文档
全量修改
PUT /索引库名称/_doc/文档id
{
"字段1":"值1",
"字段2":"值2",
"字段3":"值3",
"字段4":{
"子字段1":"值"
}
}
局部修改
POST /索引库名称/_update/文档id
{
"doc":{
"字段1":"新值"
}
}
``
## RestClient
- 依赖
```xml
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
</dependency>
- 覆盖elasticsearch版本
<properties>
<java.version>1.8</java.version>
<elasticsearch.version>7.12.1</elasticsearch.version>
</properties>
- RestHighLevelClient
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(
HttpHost.create("http://xx.xx.xx.xx:9200")
));
// 关闭
// client.close()
索引库操作
- 创建索引库
// 1.创建Request对象
CreateIndexRequest request = new CreateIndexRequest("hotel");
// 2.准备请求的参数:DSL语句
// MAPPING_TEMPLATE 创建索引库语句
request.source(MAPPING_TEMPLATE, XContentType.JSON);
// 3.发送请求
client.indices().create(request, RequestOptions.DEFAULT);
- 删除索引库
// 1.创建Request对象
DeleteIndexRequest request = new DeleteIndexRequest("hotel");
// 2.发送请求
client.indices().delete(request, RequestOptions.DEFAULT);
- 判断索引库是否存在
// 1.创建Request对象
GetIndexRequest request = new GetIndexRequest("hotel");
// 2.发送请求
boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);
// 3.输出
System.err.println(exists?"存在":"不存在");
文档操作
- 新增
// 1.根据id查询酒店数据
Hotel hotel = hotelService.getById(id);
// 2.转换为文档类型
HotelDoc hotelDoc = new HotelDoc(hotel);
// 3.将HotelDoc转json
String json = JSON.toJSONString(hotelDoc);
// 1.准备Request对象
IndexRequest request = new IndexRequest("hotel").id(hotelDoc.getId().toString());
// 2.准备Json文档
request.source(json, XContentType.JSON);
// 3.发送请求
client.index(request, RequestOptions.DEFAULT);
- 查询
// 1.准备Request
GetRequest request = new GetRequest("hotel", id);
// 2.发送请求,得到响应
GetResponse response = client.get(request, RequestOptions.DEFAULT);
// 3.解析响应结果
String json = response.getSourceAsString();
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
System.out.println(hotelDoc);
- 删除
// 1.准备Request
DeleteRequest request = new DeleteRequest("hotel", id);
// 2.发送请求
client.delete(request, RequestOptions.DEFAULT);
- 修改
// 1.准备Request
UpdateRequest request = new UpdateRequest("hotel", id);
// 2.准备请求参数
request.doc(
"price", "xxx",
"starName", "xxx"
);
// 3.发送请求
client.update(request, RequestOptions.DEFAULT);
- 批量导入
// 批量查询酒店数据
List<Hotel> hotels = hotelService.list();
// 1.创建Request
BulkRequest request = new BulkRequest();
// 2.准备参数,添加多个新增的Request
for (Hotel hotel : hotels) {
// 2.1.转换为文档类型HotelDoc
HotelDoc hotelDoc = new HotelDoc(hotel);
// 2.2.创建新增文档的Request对象
request.add(new IndexRequest("hotel")
.id(hotelDoc.getId().toString())
.source(JSON.toJSONString(hotelDoc), XContentType.JSON));
}
// 3.发送请求
client.bulk(request, RequestOptions.DEFAULT);
DSL查询
- DSL查询分类
- 查询所有
- match_all
- 全文检索(full text)查询
- match
- multi_match
- 精确查询
- ids
- range
- term
- 地理(geo)查询
- geo_distance
- geo_bounding_box
- 复合(compound)查询
- bool
- function_score
- 查询所有
查询所有
GET /indexName/_search
{
"query": {
"查询类型": {
"查询条件": "条件值"
}
}
}
全文检索
GET /indexName/_search
{
"query": {
"match": {
"FIELD": "TEXT"
}
}
}
GET /indexName/_search
{
"query": {
"multi_match": {
"query": "TEXT",
"fields": ["FIELD1", " FIELD12"]
}
}
}
精确查询
// term查询
GET /indexName/_search
{
"query": {
"term": {
"FIELD": {
"value": "VALUE"
}
}
}
}
// range查询
GET /indexName/_search
{
"query": {
"range": {
"FIELD": {
"gte": xxx, // 这里的gte代表大于等于,gt则代表大于
"lte": xxx // lte代表小于等于,lt则代表小于
}
}
}
}
地理坐标查询
// geo_bounding_box查询
GET /indexName/_search
{
"query": {
"geo_bounding_box": {
"FIELD": {
"top_left": { // 左上点
"lat": xxx,
"lon": xxx
},
"bottom_right": { // 右下点
"lat": xxx,
"lon": xxx
}
}
}
}
}
// geo_distance 查询
GET /indexName/_search
{
"query": {
"geo_distance": {
"distance": "15km", // 半径
"FIELD": "xxx,xxx" // 圆心
}
}
}
复合查询
GET /hotel/_search
{
"query":{
"function_score":{
"query":{"match":{"all":"xx"}}, // 原始查询
"functions":[ //算分函数
{
"filter":{"term":{"id":"xx"}}, // 过滤条件
"weight":10 // 算分权重
}
],
"boost_mode":"multiply" // 加权模式
}
}
}
GET /hotel/_search
{
"query": {
"bool": {
"must": [ // 与
{"term": {"city": "xx" }}
],
"should": [ // 或
{"term": {"brand": "xx" }},
{"term": {"brand": "xx" }}
],
"must_not": [ // 非
{ "range": { "price": { "lte": x } }}
],
"filter": [ // 必须匹配
{ "range": {"score": { "gte": xx } }}
]
}
}
}
排序
- 普通字段排序
GET /indexName/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"FIELD": "desc" // 排序字段、排序方式ASC、DESC
}
]
}
- 地理坐标排序
GET /indexName/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"_geo_distance" : {
"FIELD" : "纬度,经度", // 文档中geo_point类型的字段名、目标坐标点
"order" : "asc", // 排序方式
"unit" : "km" // 排序的距离单位
}
}
]
}
分页
GET /hotel/_search
{
"query": {
"match_all": {}
},
"from": 0, // 分页开始的位置,默认为0
"size": 10, // 期望获取的文档总数
"sort": [
{"price": "asc"}
]
}
GET /hotel/_search
{
"query": {
"match_all": {}
},
"from": 990, // 分页开始的位置,默认为0
"size": 10, // 期望获取的文档总数
"sort": [
{"price": "asc"}
]
}
高亮
GET /hotel/_search
{
"query": {
"match_all": {}
},
"from": 0, // 分页开始的位置,默认为0
"size": 10, // 期望获取的文档总数
"sort": [
{"price": "asc"}
],
"highlight":{
"fields":{
"name":{ // 高亮字段
"require_field_match":"false",
"pre_tags":"<em>",
"post_tags":"</em>"
}
}
}
}
RestClient
- handleResponse
private void handleResponse(SearchResponse response) {
// 4.解析响应
SearchHits searchHits = response.getHits();
// 4.1.获取总条数
long total = searchHits.getTotalHits().value;
System.out.println("共搜索到" + total + "条数据");
// 4.2.文档数组
SearchHit[] hits = searchHits.getHits();
// 4.3.遍历
for (SearchHit hit : hits) {
// 获取文档source
String json = hit.getSourceAsString();
// 反序列化
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
System.out.println("hotelDoc = " + hotelDoc);
}
}
- match_all
// 1.准备Request
SearchRequest request = new SearchRequest("hotel");
// 2.准备DSL
request.source().query(QueryBuilders.matchAllQuery());
// 3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析响应
handleResponse(response);
- match
// 1.准备Request
SearchRequest request = new SearchRequest("hotel");
// 2.准备DSL
request.source().query(QueryBuilders.matchQuery("all", "如家"));
// 3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析响应
handleResponse(response);
- term
// 2.准备DSL
request.source().query(QueryBuilders.termQuery("city", "xxx"));
- range
// 2.准备DSL
request.source().query(QueryBuilders.rangeQuery("price").gte(100).lte(150));
- bool
// 1.准备Request
SearchRequest request = new SearchRequest("hotel");
// 2.准备DSL
// 2.1.准备BooleanQuery
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
// 2.2.添加term
boolQuery.must(QueryBuilders.termQuery("city", "杭州"));
// 2.3.添加range
boolQuery.filter(QueryBuilders.rangeQuery("price").lte(250));
request.source().query(boolQuery);
// 3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析响应
handleResponse(response);
- 排序分页
// 页码,每页大小
int page = 1, size = 5;
// 1.准备Request
SearchRequest request = new SearchRequest("hotel");
// 2.准备DSL
// 2.1.query
request.source().query(QueryBuilders.matchAllQuery());
// 2.2.排序 sort
request.source().sort("price", SortOrder.ASC);
// 2.3.分页 from、size
request.source().from((page - 1) * size).size(5);
// 3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析响应
handleResponse(response);
- 高亮
// 1.准备Request
SearchRequest request = new SearchRequest("hotel");
// 2.准备DSL
// 2.1.query
request.source().query(QueryBuilders.matchQuery("all", "如家"));
// 2.2.高亮
request.source().highlighter(new HighlightBuilder().field("name").requireFieldMatch(false));
// 3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析响应
SearchHits searchHits = response.getHits();
// 4.1.获取总条数
long total = searchHits.getTotalHits().value;
System.out.println("共搜索到" + total + "条数据");
// 4.2.文档数组
SearchHit[] hits = searchHits.getHits();
// 4.3.遍历
for (SearchHit hit : hits) {
// 获取文档source
String json = hit.getSourceAsString();
// 反序列化
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
// 获取高亮结果
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
if (!CollectionUtils.isEmpty(highlightFields)) {
// 根据字段名获取高亮结果
HighlightField highlightField = highlightFields.get("name");
if (highlightField != null) {
// 获取高亮值
String name = highlightField.getFragments()[0].string();
// 覆盖非高亮结果
hotelDoc.setName(name);
}
}
System.out.println("hotelDoc = " + hotelDoc);
}
数据聚合
-
种类
- 桶(Bucket)聚合
- TermAggregation,文档字段值分组
- Date Histogram,日期阶梯分组
- 度量(Metric)聚合
- Avg:求平均值
- Max:求最大值
- Min:求最小值
- Stats:同时求max、min、avg、sum
- 管道(pipeline)聚合
- 其它聚合的结果为基础做聚合
- 桶(Bucket)聚合
-
Bucket
GET /hotel/_search
{
"size": 0, // 设置size为0,结果中不包含文档,只包含聚合结果
"aggs": { // 定义聚合
"brandAgg": { //给聚合起个名字
"terms": { // 聚合的类型,按照品牌值聚合,所以选择term
"field": "brand", // 参与聚合的字段
"size": 20 // 希望获取的聚合结果数量
}
}
}
}
- 聚合排序
GET /hotel/_search
{
"size": 0,
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"order": {
"_count": "asc" // 按照_count升序排列
},
"size": 20
}
}
}
}
- 限定范围
GET /hotel/_search
{
"query": {
"range": {
"price": {
"lte": 200 // 只对200元以下的文档聚合
}
}
},
"size": 0,
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"size": 20
}
}
}
}
- Metric
GET /hotel/_search
{
"size": 0,
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"size": 20,
"order": {
"scoreAgg.avg": "desc" // scoreAgg avg排序
},
},
"aggs": { // 是brands聚合的子聚合,也就是分组后对每组分别计算
"score_stats": { // 聚合名称
"stats": { // 聚合类型,这里stats可以计算min、max、avg等
"field": "score" // 聚合字段,这里是score
}
}
}
}
}
}
RestApi
// 入口
public Map<String, List<String>> filters(RequestParams params) {
try {
// 1.准备Request
SearchRequest request = new SearchRequest("hotel");
// 2.准备DSL
// 2.1.query
buildBasicQuery(params, request);
// 2.2.设置size
request.source().size(0);
// 2.3.聚合
buildAggregation(request);
// 3.发出请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析结果
Map<String, List<String>> result = new HashMap<>();
Aggregations aggregations = response.getAggregations();
// 4.1.根据品牌名称,获取品牌结果
List<String> brandList = getAggByName(aggregations, "brandAgg");
result.put("品牌", brandList);
// 4.2.根据品牌名称,获取品牌结果
List<String> cityList = getAggByName(aggregations, "cityAgg");
result.put("城市", cityList);
// 4.3.根据品牌名称,获取品牌结果
List<String> starList = getAggByName(aggregations, "starAgg");
result.put("星级", starList);
return result;
} catch (IOException e) {
throw new RuntimeException(e);
}
}
private void buildAggregation(SearchRequest request) {
request.source().aggregation(AggregationBuilders
.terms("brandAgg")
.field("brand")
.size(100)
);
request.source().aggregation(AggregationBuilders
.terms("cityAgg")
.field("city")
.size(100)
);
request.source().aggregation(AggregationBuilders
.terms("starAgg")
.field("starName")
.size(100)
);
}
private List<String> getAggByName(Aggregations aggregations, String aggName) {
// 4.1.根据聚合名称获取聚合结果
Terms brandTerms = aggregations.get(aggName);
// 4.2.获取buckets
List<? extends Terms.Bucket> buckets = brandTerms.getBuckets();
// 4.3.遍历
List<String> brandList = new ArrayList<>();
for (Terms.Bucket bucket : buckets) {
// 4.4.获取key
String key = bucket.getKeyAsString();
brandList.add(key);
}
return brandList;
}
自动补全
-
分词器(analyzer)
- character filters
- 在tokenizer之前对文本进行处理。例如删除字符、替换字符
- tokenizer
- 将文本按照一定的规则切割成词条(term)。例如keyword,就是不分词;还有ik_smart
- tokenizer filter
- 将tokenizer输出的词条做进一步处理。例如大小写转换、同义词处理、拼音处理等
- character filters
-
拼音分词器文章来源:https://www.toymoban.com/news/detail-849903.html
- https://github.com/medcl/elasticsearch-analysis-pinyin
-
自定义分词器文章来源地址https://www.toymoban.com/news/detail-849903.html
PUT /test
{
"settings": {
"analysis": {
"analyzer": { // 自定义分词器
"my_analyzer": { // 分词器名称
"tokenizer": "ik_max_word",
"filter": "py"
}
},
"filter": { // 自定义tokenizer filter
"py": { // 过滤器名称
"type": "pinyin", // 过滤器类型,这里是pinyin
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
},
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "my_analyzer",
"search_analyzer": "ik_smart"
}
}
}
}
- 自动补全
- 参与补全查询的字段必须是completion类型
// 自动补全查询
GET /test/_search
{
"suggest": {
"title_suggest": {
"text": "s", // 关键字
"completion": {
"field": "title", // 补全查询的字段
"skip_duplicates": true, // 跳过重复的
"size": 10 // 获取前10条结果
}
}
}
}
// 1.准备Request
SearchRequest request = new SearchRequest("hotel");
// 2.准备DSL
request.source().suggest(new SuggestBuilder().addSuggestion(
"suggestions",
SuggestBuilders.completionSuggestion("suggestion")
.prefix(prefix)
.skipDuplicates(true)
.size(10)
));
// 3.发起请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析结果
Suggest suggest = response.getSuggest();
// 4.1.根据补全查询名称,获取补全结果
CompletionSuggestion suggestions = suggest.getSuggestion("suggestions");
// 4.2.获取options
List<CompletionSuggestion.Entry.Option> options = suggestions.getOptions();
// 4.3.遍历
List<String> list = new ArrayList<>(options.size());
for (CompletionSuggestion.Entry.Option option : options) {
String text = option.getText().toString();
list.add(text);
}
return list;
数据同步
- 数据同步方案
- 同步调用
- 优点:实现简单,粗暴
- 缺点:业务耦合度高
- 异步通知(mq)
- 优点:低耦合,实现难度一般
- 缺点:依赖mq的可靠性
- 监听binlog
- 优点:完全解除服务间耦合
- 缺点:开启binlog增加数据库负担、实现复杂度高
- 同步调用
到了这里,关于学习笔记-微服务基础(黑马程序员)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
![[学习笔记]黑马程序员python教程](https://imgs.yssmx.com/Uploads/2024/02/723818-1.png)

![[学习笔记]黑马程序员-Hadoop入门视频教程](https://imgs.yssmx.com/Uploads/2024/02/648432-1.png)