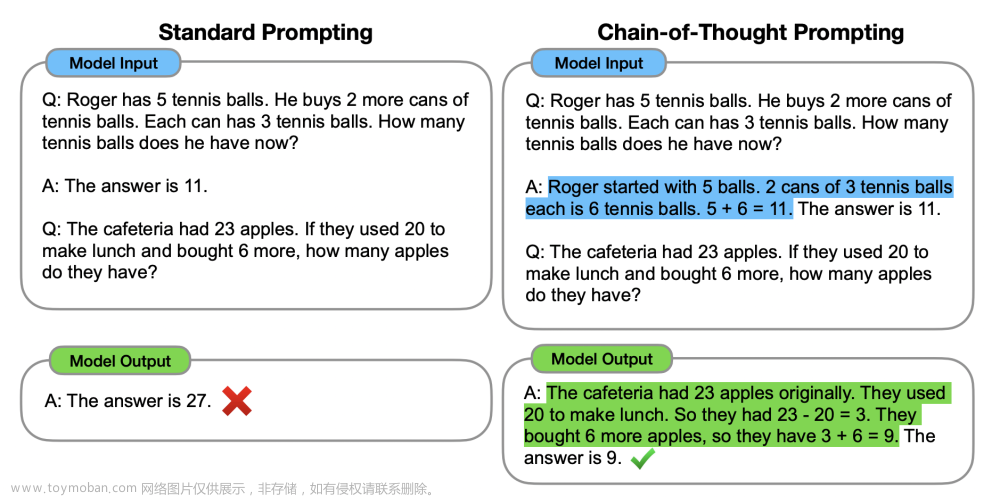
RangeDet: In Defense of Range View for LiDAR-based 3D Object Detection

论文:https://arxiv.org/pdf/2103.10039.pdf
代码:https://github.com/tusen-ai/RangeDet
问题
提出了一个名为RangeDet的新型3D物体检测技术,利用激光雷达数据。
RangeDet的核心在于使用了一种紧凑的表示方法,称为范围视图,与其他常用方法相比,它避免了计算误差。

根据论文中的讨论,使用范围视图(range view)表示法面临几个挑战:
-
尺寸变化问题: 范围视图的一个主要问题是,它继承了传统2D图像检测中的一个典型问题,即物体因距离不同而呈现出的“近大远小”现象,这导致物体尺寸变化多端,给物体检测带来挑战。相比之下,鸟瞰图(Bird’s Eye View, BEV)表示法不会遇到这种问题,但BEV的主要问题在于数据稀疏性和量化损失。
-
处理难度: 第二个挑战是不能简单地采用传统的2D卷积网络处理范围图像。因为在范围图像中,每个像素点都有一个明确的距离值,使得相邻像素之间的实际空间距离各不相同。这一特性要求在处理时必须考虑到像素间的这种空间距离差异。
-
稠密特征的利用: 尽管范围图像相比点云和BEV视图具有更稠密的特征,这理论上可以使得特征学习更加高效,但如何有效地利用这些稠密特征来提高检测精度是一个问题。稠密特征提供了更丰富的信息,但同时也需要更复杂的方法来正确地解析这些信息,并转化为对物体检测有利的形式。
笛卡尔坐标
在论文中提到,对于一个扫描周期内包含m个光束和n次测量的激光雷达,其一次扫描返回的数据构成了一个m乘以n的矩阵,被称为测距仪图像。此测距图像的每一列对应一个方位角,每一行对应一个倾角,这些角度代表了返回点与激光雷达原点之间的相对垂直和水平位置。测距图像中的像素值不仅包括了相应点的距离(深度)、返回激光脉冲的强度(即强度值)等信息,还可能包含其他辅助信息。在测距图像中,每个像素至少囊括了三个几何参数:测距(r)、方位角(θ)和倾角(φ)。
结构图

这个过程针对处理激光雷达的范围图像(Range Image)采用了一种特殊的框架,其中范围图像被看作是一个具有8个通道的2D图像。这些通道分别代表不同的测量和几何特性,包括距离、反射率、伸长率、X、Y、Z坐标、方位角和倾角。这样的多维表示富含了环境的详细信息,对于后续的处理至关重要。
接下来,这个8通道的2D图像会依次经过两个基础块(BasicBlock),这是何凯明等人在ResNet架构中提出的一种结构单元。第一个BasicBlock按照原始设计进行处理,而第二个BasicBlock则采用了一种被称为Meta-Kernel的特殊卷积核,旨在捕获和提炼更丰富的特征信息,生成所谓的特征图(Featuremap)。
在第二个BasicBlock中,作者还引入了特征金字塔网络(FPN)的结构,通过不同尺度的特征图上采样和聚合,进一步丰富了特征表示。这一步骤在处理深度学习任务中常见,特别是在需要捕获多尺度信息的视觉任务中。
文章中的另一大创新点是范围条件金字塔分配(Range Conditioned Pyramid Assignment),这个方法根据物体距离的远近,将标签分配到不同尺度的特征图中。这种策略使得模型能够针对不同距离范围的目标,更加精准地处理信息,尤其是对近距离和远距离的目标进行了优化处理。
最后,模型通过四个3x3的卷积层分别构造了分类和回归的头部(head),并采用了Varifocal loss和Smooth L1 Loss作为损失函数来优化模型。这些设计和优化策略共同提高了模型对于3D物体检测的性能,特别是在处理复杂的激光雷达数据时的准确性和鲁棒性。
Varifocal loss
Smooth L1 Loss
IoU target calculation
-
左图: 描述的是一个方法,其中对于模型考虑的每一个点,都将以该点为中心,而且该点的x轴被定义为局部x轴。这种方法简单地将每个点自身作为坐标系的起点,而不考虑任何外部的方向信息或者点的方位角。
-
右图: 在这个方法中,每个点的方位角方向被定义为局部x轴。这意味着,与左图的方法相比,局部坐标系的定义考虑到了每个点的方位,使得局部x轴的定义更加动态,依赖于每个点相对于全局坐标系的方向。
在模型处理回归任务,特别是在计算回归损失之前,将采用左图的目标方式转换成右图的目标方式。这样的转换是为了利用方位角信息,从而更精确地定义局部坐标系,提高模型对于物体位置和方向的估计精度。
Meta-Kernel Convolution

在这个过程中,首先通过一个3x3的采样网格,我们确定了九个邻近点的位置,这些位置的坐标被转换成相对于中心点的直角坐标系统下的位置。这一步骤的目的是获取空间上邻近点的布局信息。
接着,使用一个共享的多层感知器_MLP对这些相对坐标进行处理。MLP是一种简单的神经网络,它可以从输入数据中学习复杂的函数映射。在这里,它被用来根据邻近中心的相对坐标生成九个不同的权重向量(w1到w9)。这些权重向量反映了每个邻近点相对于中心点的空间重要性或贡献度。
然后,对应于这九个位置的输入特征向量(f1到f9)被采样。这些特征向量可能包含了那些位置上的物体的形状、纹理等信息。
最后,通过一个特殊的操作,将这九个邻域的输出(oi)组合起来。这通常通过连接(concatenating)这些输出并应用一个1x1的卷积来实现。1x1卷积在这里的作用是将来自不同通道和不同采样位置的信息汇总,生成一个输出特征向量。这个输出特征向量综合了周围邻域的信息。
总结来说,这个过程通过分析邻近点的空间布局和特征信息,以及它们相对于中心点的重要性,有效地生成了融合了局部信息的输出特征向量。这种方法可以增强模型对于空间信息的理解和利用,从而提高其性能。
参考文章来源:https://www.toymoban.com/news/detail-849965.html
https://zhuanlan.zhihu.com/p/526985263文章来源地址https://www.toymoban.com/news/detail-849965.html
到了这里,关于论文阅读RangeDet: In Defense of Range View for LiDAR-based 3D Object Detection的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!