本专栏内容为:算法学习专栏,分为优选算法专栏,贪心算法专栏,动态规划专栏以及递归,搜索与回溯算法专栏四部分。 通过本专栏的深入学习,你可以了解并掌握算法。
💓博主csdn个人主页:小小unicorn
⏩专栏分类:算法从入门到精通
🚚代码仓库:小小unicorn的代码仓库🚚
🌹🌹🌹关注我带你学习编程知识
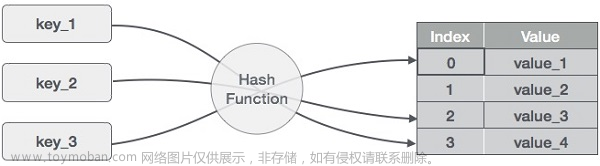
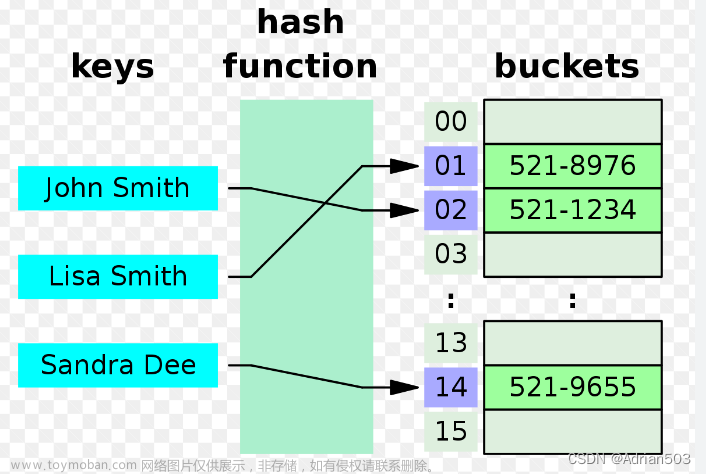
哈希表简介
在介绍本专题前,我们先介绍一下什么是哈希表
哈希表就是一个容器,它的用途就是可以快速查找元素,它的时间复杂度是O(1)级别,空间复杂度就是O(N)也就是用空间换时间。
什么时候用哈希表?
介绍了什么是哈希表,那么什么时候可以用哈希表?
记住一点,当我们要频繁的进行查找某一个数的时候,这时候我们就可以考虑用哈希表。当然提到查找也不要忘了我们之前学过的二分算法,也可用来查找元素。
怎么用哈希表?
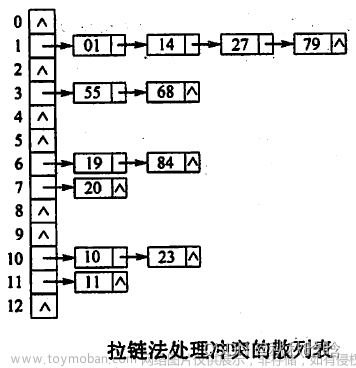
提到怎么用,通常情况下容器里面的哈希表我们可以直接拿来用,其次就是我们可以用一个数组来模拟哈希表。
通常会用在两个场景,一是在处理字符串中的字符的时候,我们可以用数组来建议模拟哈希表,方便做到快速查找。
其次当数据量很小的时候,我们也可以直接考虑用数组来模拟哈希表。
面试题 01.02. 判定是否互为字符重排
题目来源:Leetcode面试题 01.02. 判定是否互为字符重排
给定两个由小写字母组成的字符串 s1 和 s2,请编写一个程序,确定其中一个字符串的字符重新排列后,能否变成另一个字符串。
算法原理:
在判断字符重不重排,首先我们要先判断这两个字符串的长度是否一致,长度都不一致,肯定无法重排。
判断两个字符串能否构成重排,最暴力就是直接仍在两个哈希表里,然后判断这两个哈希表是否相等,但是这样太麻烦了。
我们可以进行优化,用数组模拟哈希表,因为全都是小写字母,那么我们直接开一个大小为26的一个字符数组。
遍历第一个数组,碰到一个字母就对应++,然后遍历第二个数组,碰到对应字符数组中字母相同就对应–。同时,判断数组下标,如果说下标<0了,那就说明,该字符在第一个数组中就不存在,不能构成重排。
代码实现:文章来源地址https://www.toymoban.com/news/detail-850120.html
class Solution
{
public:
bool CheckPermutation(string s1, string s2)
{
int n=s1.size(),m=s2.size();
if(n!=m)
return false;
char hash[26];
//遍历第一个数组
for(auto S1:s1)
{
hash[S1-'a']++;
}
//遍历第二个数组
for(auto S2:s2)
{
hash[S2-'a']--;
if(hash[S2-'a']<0)
return false;
}
return true;
}
};
存在重复元素
题目来源:Leetcode217存在重复元素
给你一个整数数组 nums 。如果任一值在数组中出现 至少两次 ,返回 true ;如果数组中每个元素互不相同,返回 false 。
算法原理:
解法用哈希表,
固定1位置,看1位置前面有没用相同元素,没有就继续向后移动,看2位置前面有没有相同元素,没有就继续向后移动,依次内推。
代码实现
class Solution
{
public:
bool containsDuplicate(vector<int>& nums)
{
unordered_set<int> hash;
for(auto x:nums)
{
//存在相同元素
if(hash.count(x))
return true;
else
hash.insert(x);
}
return false;
}
};
存在重复元素 II
题目来源:Leetcode219存在重复元素 II
给你一个整数数组 nums 和一个整数 k ,判断数组中是否存在两个 不同的索引 i 和 j ,满足 nums[i] == nums[j] 且 abs(i - j) <= k 。如果存在,返回 true ;否则,返回 false 。
算法原理:
本题跟上一题的思路基本一样,但是本题要保证两个相同元素的下标差的绝对值要小于K。
哈希表里面第一个存nums[i]用来判断有没有重复元素,第二个存对应的下标。因为要判断下标关系是否符合要求。跟第一题私立基本一样,固定一个数,看前面有没有重复元素。
没有就向右移动。
代码实现:
class Solution
{
public:
bool containsNearbyDuplicate(vector<int>& nums, int k)
{
unordered_map<int,int> hash;
for(int i=0;i<nums.size();i++)
{
if(hash.count(nums[i]))
{
if(i-hash[nums[i]]<=k)
return true;
}
//找不到把当前下标插入到哈希表里面
hash[nums[i]]=i;
}
return false;
}
};
字母异位词分组
题目来源:49.字母异位词分组
给你一个字符串数组,请你将 字母异位词 组合在一起。可以按任意顺序返回结果列表。
字母异位词 是由重新排列源单词的所有字母得到的一个新单词。

算法原理:
先把题目例子分析一遍,可以将例子进行分组。
最后把每个组输出即可。
- 那么如何判断两个字符串是否是字母异位词呢?
这里我们可以排序,我们将字符串排完序,如果可以字母异位,那么他们排完序后的ASLL码值肯定都是一样的。
2.如何进行分组?
这里我们就要合理用我们的哈希表。
我们将key定义为string,将val定义为字符串数组。
遍历字符串数组,遍历第一个字符排序,然后看在不在哈希表,不在就加入到key,和val,然后遍历第二个字符串,排完序,看跟哈希表里面key匹不匹配,匹配就加入到val,循环此过程,遍历完整个字符串数组后,把哈希表里面的val全部取出来即可。文章来源:https://www.toymoban.com/news/detail-850120.html
代码实现:
class Solution
{
public:
vector<vector<string>> groupAnagrams(vector<string>& strs)
{
unordered_map<string,vector<string>> hash;
//1.把所有的异位字母词分组
for(auto & s:strs)
{
string tmp=s;
sort(tmp.begin(),tmp.end());
hash[tmp].push_back(s);
}
//2.提取结果
vector<vector<string>> ret;
for(auto &[x,y]: hash)
{
ret.push_back(y);
}
return ret;
}
};
到了这里,关于【优选算法专栏】专题十:哈希表(一)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!