专栏目录
边缘计算+WEB端应用融合:AI行为识别智能监控系统搭建指南 – 整体介绍(一)
前言
欢迎来到我们的专栏《边缘计算+WEB端应用融合:AI行为识别智能监控系统搭建指南》!在这个专栏中,我们将带您深入探索如何将边缘计算和WEB端应用相结合,打造智能监控系统,实现对各种行为的实时识别和监测。无论您是想在家庭、办公场所还是公共区域建立智能监控系统,本专栏都将为您提供全面的指导和实用的技巧。让我们一起探索边缘计算技术的无限可能,构建出更加智能、高效的监控系统吧!
本专栏系统完整搭建将用到C++(边缘设备程序)、Python(模型训练、网络通信)、JAVA(系统后端)、VUE3(系统前端)、SQL(数据库)等开发语言。在搭建之前我自己也只会JAVA和SQL,所以完全不用担心语言不会导致无法搭建。所有的算力都由边缘设备提供,所以不需要高性能服务器,成本上也可以得到控制。
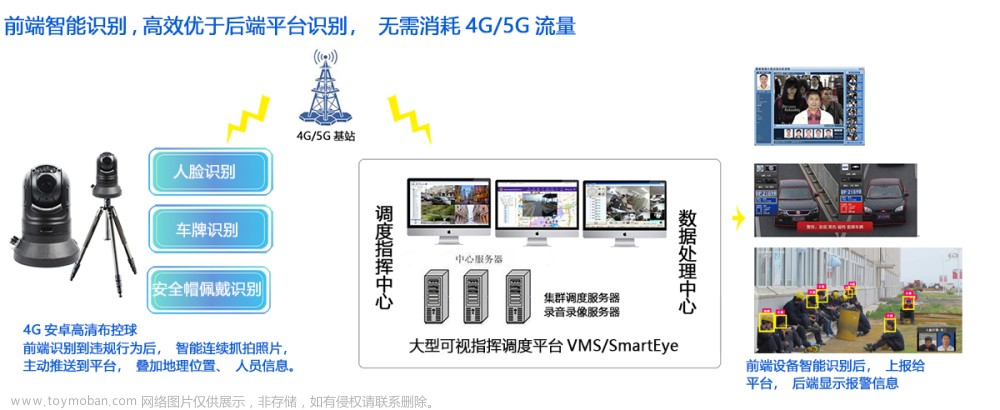
项目特点:低成本搭建视频智能识别、边缘计算终端和网页端完全打通自由控制、除常规标注检测外增加了预警和区域检测功能。
申明:本系统完全由博主自己一人搭建,其中使用到的都是开源项目,如:若依、RKNN、zlmediakit等。
PS:国人的开源项目越来越牛了。
边缘图像识别与推流
整体思路
在上一篇文章中有介绍道,我这个项目所采用的边缘计算设备是基于国产芯片RK3588。目前开发出来的是一代产品的程序包,命名为YunYan_V1.0(云眼1.0)。
YunYan_V1.0采用C++编写,核心采用的是yolov5的图像识别能力,支持多线程的图像识别,充分调用RK3588的三个NPU进行图像识别。并且利用zlmediakit将对视频图像的读推流进行了高度集成。以下是代码的大致思路:
原始视频信号
其中有一个问题就是怎么获取原始的视频流信息?我个人在开发中主要是获取三种流方式:
方式1:模拟视频流
模拟是通过mediamtx和ffmpeg实现的,通过一台局域网内的设备进行模拟信号的输送就可以实现获取rtsp流的目的,我自己用的就是闲置的树莓派。
mediamtx下载地址:https://github.com/bluenviron/mediamtx/releases
ffmpeg官网:https://ffmpeg.org/ffmpeg.html,ffmpeg网上有很多安装教程可以根据自身系统版本搜索。
nohup ./mediamtx mediamtx.yml > mediamtx.log 2>&1 &
nohup ffmpeg -re -stream_loop -1 -i /home/medias/test.mp4 -vcodec copy -acodec copy -b:v 5M -f rtsp -rtsp_transport tcp rtsp://localhost:8554/live.sdp > testffmpeg.log 2>&1 &
rtsp://192.168.124.31:8554/live.sdp
方式2:网络摄像头原始视频流【海康设备】
rtsp://admin:XXXXXX@192.168.124.38:554/h265/ch1/main/av_stream
方式3:网络录像机原始视频流【海康设备】
rtsp://admin:XXXXXXX@192.168.124.29:554/Streaming/Channels/101
部分核心代码
以下是部分 核心代码片:
- 创建线程池
// 创建线程池
yolo_thread_pool = new Yolov5ThreadPool();
// 初始化线程池
// 参数1:模型文件地址
// 参数2:线程数量
// 参数3:非极大值抑制
// 参数4:置信度
// 参数5:模型标签文件路径
// 参数6:标签数量
yolo_thread_pool->setUp(model_path, num_threads, NMS_threshold, box_threshold, model_label_file_path, obj_class_num);
- 定义解码器
MppDecoder *decoder = new MppDecoder(); // 创建解码器
decoder->Init(video_type, app_ctx.source_frame_rate, &app_ctx); // 初始化解码器
// mpp在每次解析后都会回调mpp_decoder_frame_callback方法
decoder->SetCallback(mpp_decoder_frame_callback); // 设置回调函数,用来处理解码后的数据
app_ctx.decoder = decoder;
- 解码后处理
// 这里利用了rk3588自带的rga进行颜色通道的转换:YUV420SP -> RGB888
// 也可以使用opencv
origin = wrapbuffer_fd(fd, width, height, RK_FORMAT_YCbCr_420_SP, width_stride, height_stride);
src = wrapbuffer_fd(mpp_frame_fd, width, height, RK_FORMAT_YCbCr_420_SP, width_stride, height_stride);
cv::Mat origin_mat = cv::Mat::zeros(height, width, CV_8UC3);
rga_buffer_t rgb_img = wrapbuffer_virtualaddr((void *)origin_mat.data, width, height, RK_FORMAT_RGB_888);
imcopy(origin, rgb_img);
// 提交推理任务给线程池
yolo_thread_pool->submitTask(origin_mat, job_cnt++);
- 获取处理结果并绘制预警
std::vector<Detection> objects;
// 获取推理结果
auto ret_code = yolov5_thread_pool->getTargetResultNonBlock(objects, result_cnt);
// 遍历检测结果并且进行判断
for (const auto &object : objects)
{
auto iter = ctx->labels_map.find(object.className);
// 设置参数判断是否全图警戒,1为全图
bool temp_ret = true;
if (ctx->enable_region == 1 && ctx->g_ploygon.size() > 0)
{
Point p = {
object.box.x + object.box.width / 2,
object.box.y + object.box.height / 2};
// 判断是否在预警区域中
temp_ret = isInside(ctx->g_ploygon, p);
}
double value = iter->second;
// 判断识别对象是否在识别要素中,同时判断要素是否在警戒区域中,执行度大于设定值
if (iter != ctx->labels_map.end() && temp_ret && object.confidence >= value)
{
cv::rectangle(img, object.box, cv::Scalar(255, 0, 0), 2);
// class name with confidence
std::string draw_string = object.className + " " + std::to_string(object.confidence);
cv::putText(img, draw_string, cv::Point(object.box.x, object.box.y - 5), cv::FONT_HERSHEY_SIMPLEX, 1,
cv::Scalar(255, 0, 0), 2);
// 在迭代中发现了存在异常的标记,进行临时变量标记,此变量可能会在过程中重复赋值。
if_warning_hold = true;
}
else
{
cv::rectangle(img, object.box, object.color, 2);
// class name with confidence
std::string draw_string = object.className + " " + std::to_string(object.confidence);
cv::putText(img, draw_string, cv::Point(object.box.x, object.box.y - 5), cv::FONT_HERSHEY_SIMPLEX, 1,
cv::Scalar(255, 0, 255), 2);
}
}
- 检测结果推流
// mk的参数初始化
char *ini_path = mk_util_get_exe_dir(ctx->mk_file_path.c_str());
mk_config config = {
.thread_num = 10,
.log_level = 0,
.log_mask = LOG_CONSOLE,
.log_file_path = NULL,
.log_file_days = 0,
.ini_is_path = 1,
.ini = ini_path,
.ssl_is_path = 1,
.ssl = NULL,
.ssl_pwd = NULL
};
// memset(&config, 0, sizeof(mk_config));
// config.log_mask = LOG_CONSOLE;
// 初始化环境,调用该库前需要先调用此函数
mk_env_init(&config);
mk_free(ini_path);
// 在端口80上启动HTTP服务器
if (ctx->enable_http == 1)
mk_http_server_start(ctx->push_http_port, 0);
// 在端口554上启动RTSP服务器
if (ctx->enable_rtsp == 1)
mk_rtsp_server_start(ctx->push_rtsp_port, 0);
// 在端口1935上启动RTMP服务器
if (ctx->enable_rtmp == 1)
mk_rtmp_server_start(ctx->push_rtmp_port, 0);
if (ctx->enable_rtc == 1)
mk_rtc_server_start(ctx->push_rtc_port);
// 创建一个新的Codeium播放器
ctx->player = mk_player_create();
ctx->stream_url = url;
// 设置处理播放事件的回调函数
mk_player_set_on_result(ctx->player, on_mk_play_event_func, ctx);
// 设置播放被异常中断的回调
mk_player_set_on_shutdown(ctx->player, on_mk_shutdown_func, ctx);
// 播放来自提供的RTSP URL的视频流
mk_player_play(ctx->player, ctx->stream_url);
// 推流
ret = mk_media_input_h264(ctx->media, enc_data, enc_data_size, millis, millis);
根据以上代码无法完整完成编码工作,由于本专栏主要方向是关于边缘计算设备和WEB端应用的融合,实现AI行为识别的智能监控系统。所以不会对终端设备的实际使用技术及代码原理进行特别详细的描述。如果读者有需要可以留言,我可以出一个关于RK3588的独立专栏。
其实本质上边缘计算设备无论是选择RK3588,还是带有GPU的主机都可以,本项目是为了减少项目的搭建预算所以找的更便宜的解决方案,同时也能符合国产化、信创需要。
配置文件清单
以下是YunYan_V1.0提供的参数清单:
[YUNYAN]
# 进程的唯一编号,这是一个uid
CEProcessId = b6cf4e7e-b952-4bf5-be29-0225f71d7f57
# 模型路径,必须是完整路径yolo5s_cx_200
ModelPath = /home/YunYan-V1/weights/yolov5s.rknn
# IOU
NMSThreshold = 0.65
# 置信度
BoxThreshold = 0.4
# 模型的labels文件路径
ModelLabelsFilePath = /home/YunYan-V1/coco_80_labels_list.txt
# 推理类型数量 yolov5 80
ObjClassNum = 80
# 流地址
StreamUrl = rtsp://192.168.124.31:8554/live3.sdp
# 视频流类型264/265,default 264,265格式目前不支持
VideoType = 264
# 原始视频帧率
SourceFrameRate = 25
# 启动监测的线程数,default 12
NumThreads = 20
# 是否开启hls播放功能,default 0,需要和EnableHttp同时开启
EnableHls = 0
# 是否开启hls播放功能,default 0
EnableHttp = 0
# http推流端口,default 80
PushHttpPort = 80
# 是否开启rtsp推流
EnableRtsp = 1
# rstp推流端口,default 554
PushRtspPort = 554
# 是否开启rtsp推流
EnableRtmp = 0
# rtmp推流端口,default 1935
PushRtmpPort = 1935
# 是否开启rtc
EnableRtc = 0
# rtc推流端口,default 8000
PushRtcPort = 8001
# 推流地址设定1
PushPathFirst = yunyan-live
# 推流地址设定2
PushPathSecond = test
# 工作时间设置{8,30,13,30}${14,0,17,30}
WorkTimeRanges = {11,00,17,10}
# 识别的labels,用英文$分割
# {clock,0.8}${chair,0.8}
LabelsAndConfidence = {person,0.5}
#一场追踪到多少秒才触发预警视频的录制
WarningHoldUpTime = 3
# 预警间隔时间秒,如果设置数值过小会导致视频文件未完成存储就连续存储问题
WarningIntervalTime = 60
# 预警视频长度秒
WarningShowTime = 5
# 预警视频帧率,这个帧率设置的是视频输出,但是实际帧率会和原始帧率有关。
# 如果原始帧率25,预警帧率是5,将会每5帧记录一次可以帧除。
# 如果原始帧率25,预警帧率10,将会每2帧记录一次,视频感觉感觉会变慢。
WarningShowFrameRate = 10
# 预警视频保存路径
WarningFilePath = /home/yunyan_warning/
# 预警视频的信息字段
WarningFileInfo = _bad_
# 是否启动区域检测,default 0
EnableRegion = 1
# 区域检测点位文件地址
RegionFilePath = /home/YunYan-V1/region.txt
# MK配置文件地址
MkFilePath = mk_config.ini
程序包部署
由于边缘计算设备都是采用相同的系统版本,所以整体上有2种部署模式。
模式1:TF卡烧录部署
如果玩过小机器的基本对这种都不陌生,但是在这个项目中并不推荐。TF烧录是对系统内容原模原样的复制,可能会导致设备的IP冲突。路由器在给设备分配IP的时候是通过系统的特征mac进行分配的,但是烧录的系统mac地址都是相同的。如果局域网内只有一台设备不会有问题,如果存在多台设备需要通过一些补丁方式来修复,反正我不是很喜欢。
如果用这种方式可以参考:https://blog.csdn.net/Altitude_/article/details/131593735
模式2:程序包部署
打包
YunYan_V1.0的打包编译管理使用的是cmake,通过cmake打包成yunyan-1.0.0-Linux.deb。边缘计算设备只需要安装上默认的ubuntu系统后使用dpkg -i yunyan-1.0.0-Linux.deb 就可以安装。
如果是第一次安装需要根据readme中的要求对两个py脚本进行定时器配置,之后就可以全自动运行了。
##需要python安装requests
sudo apt-get python3-pip
pip install requests
#设定激活函数定时任务
#默认yunyan-cv.py每5分钟执行一次并记录执行日志
crontab -e
*/5 * * * * /usr/bin/python3 /usr/local/yunyancv/yunyan-cv.py >> /usr/local/yunyancv/yunyan-cv-py.log 2>&1
#设定预警函数定时任务
#默认yunyan-warning.py每5分钟执行一次并记录执行日志
crontab -e
*/5 * * * * /usr/bin/python3 /usr/local/yunyancv/yunyan-warning.py >> /usr/local/yunyancv/yunyan-warning-py.log 2>&1
yunyan-cv.py主要负责和云端系统进行通讯,告知平台设备的存活状态,并且会从云端系统获取最新的配置信息,如果需要配置会主动驱动进程进行在线更新。同时这也是一个进程保护程序,如果发现进程死亡会自动重启进程。yunyan-warning.py主要是负责将预警视频和预警信息推送给云端,并保证本地存储的健康,定期删除无用文件。文章来源:https://www.toymoban.com/news/detail-850167.html
如果你喜欢这篇博客请点赞留言,后续会更新在部署完成后怎么打破网络限制在公网进行通信。文章来源地址https://www.toymoban.com/news/detail-850167.html
到了这里,关于边缘计算+WEB端应用融合:AI行为识别智能监控系统搭建指南 -- 边缘设备图像识别及部署(二)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!