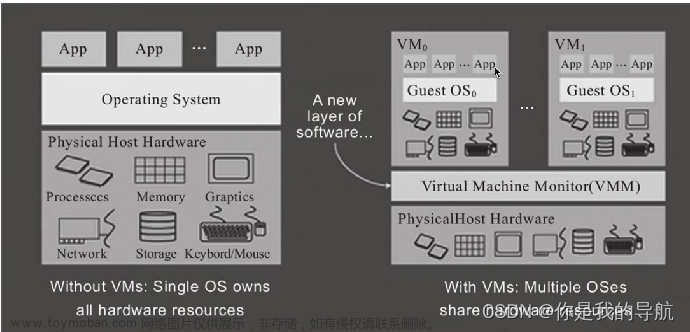
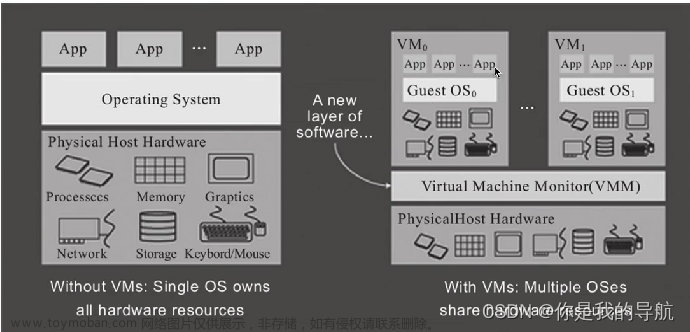
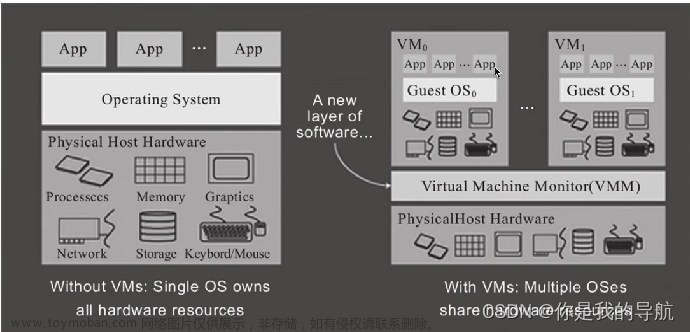
目录
一、案例分析
1.1、案例概述
1.2、案例前置知识点
1)Glusterfs 简介
2)Glusterfs 特点
1.3、案例环境
1)案例环境
2)案例需求
3)案例实现思路
二、案例实施
2.1、安装部署 KVM 虚拟化平台
1)安装 KVM 虚拟化平台
2)验证
3)开启 libvirtd 服务
2.2、部署 GlusterFS
1)关闭防火墙、SELiunx
2)编写 hosts 文件
3)安装软件
4)启动 Glusterfs
5)在 node1 上添加所有节点
6)查看集群状态
2.3、创建 Glusterfs 分布式复制卷
2.4、客户端挂载 Glusterfs 卷
1)安装 glusterfs 客户端软件。
2)创建挂载目录,并挂载 models 卷。
3)查看挂载卷
2.5、KVM 使用卷创建虚拟机
1)创建目录
2)上传镜像
3)创建虚拟机
4)验证存储
一、案例分析
1.1、案例概述
本章案例主要使用之前章节所学的 KVM 及 GlusterFS 技术,结合起来从而实现 KVM 高可用。利用 GlusterFS 分布式复制卷,对 KVM 虚拟机文件进行分布存储和冗余。分布式复制卷主要用于需要冗余的情况下把一个文件存放在两个或两个以上的节点,当其中一个节点 数据丢失或者损坏之后,KVM 仍然能够通过卷组找到另一节点上存储的虚拟机文件,以保证虚拟机正常运行。当节点修复之后,GlusterFS 会自动同步同一组卷组里面有数据的节点数据。
1.2、案例前置知识点
1)Glusterfs 简介
GlusterFS 分布式文件系统是由 Gluster 公司的创始人兼首席技术官 Anand Babu Periasamy 编写。一个可扩展的分布式文件系统,可用于大型的、分布式的、对大量数据进行访问的应用。它可运行于廉价的普通硬件上,并提供容错功能;也可以给大量的用户提供总体性能较高的服务。GlusterFS 可以根据存储需求快速调配存储,内含丰富的自动故障转移功能,且摒弃集中元数据服务器的思想。适用于数据密集型任务的可扩展网络文件系统, 且免费开源。Gluster 于 2011 年 10 月 7 日被 Red Hat 收购。
2)Glusterfs 特点
- GlusterFS 体系结构,将计算、存储和 I/O 资源聚合到全局名称空间中,每台服务器都被视为节点,通过添加附加节点或向每个节点添加额外存储来扩展容量。通过在更多节点之间部署存储来提高性能。
- GlusterFS 支持基于文件的镜像和复制、分条、负载平衡、故障转移、调度、磁盘缓存、存储配额、卷快照等功能。
- GlusterFS 各客户端之间无连接,本身依赖于弹性哈希算法,而不是使用集中式或分布式元数据模型。
- GlusterFS 通过各种复制选项提供数据可靠性和可用性,例如复制卷、分布卷。
1.3、案例环境
1)案例环境
公司由于大规模使用 KVM 虚拟机来运行业务,为了保证公司虚拟机能够安全稳定运行,决定采用 KVM+GlusterFS 模式,来保证虚拟机存储的分布部署,以及分布冗余。避免当虚拟机文件损坏,或者丢失。从而在损坏或就丢失时有实时备份,保证业务正常运行。
本案例环境如下表所示。
| 主机 | 操作系统 | 主机名 / IP地址 | 主要软件及版本 |
| 服务器 | CentOS 7.6 | node1 / 192.168.23.211 | GlusterFS 3.10.2 |
| 服务器 | CentOS 7.6 | node2 / 192.168.23.212 | GlusterFS 3.10.2 |
| 服务器 | CentOS 7.6 | node3 / 192.168.23.213 | GlusterFS 3.10.2 |
| 服务器 | CentOS 7.6 | node4 / 192.168.23.214 | GlusterFS 3.10.2 |
| 服务器 | CentOS 7.6 | kvm / 192.168.23.215 | KVM \ Gluster-client |
环境列表
 案例拓扑
案例拓扑
2)案例需求
- 部署 GlusterFS 文件系统
- 实现 KVM 虚拟主机不会因宿主机宕机而宕机
3)案例实现思路
- 安装 KVM
- 所有节点部署 GlusterFS
- 客户端挂载 GlusterFS
- KVM 使用挂载的 GlusterFS 目录创建虚拟机
二、案例实施
2.1、安装部署 KVM 虚拟化平台
1)安装 KVM 虚拟化平台
在 CentOS 的系统光盘镜像中,已经提供了安装 KVM 所需软件。通过部署基于光盘镜像的本地 YUM 源,直接使用 YUM 命令安装所需软件即可,安装 KVM 所需软件具体包含以下几个。
[root@kvm ~]# yum -y install qemu-kvm qemu-kvm-tools virt-install qemu-img btidge-utils libvirt2)验证
重启系统后,查看 CPU 是否支持虚拟化,对于 Intel 的服务器可以通过以下命令查看, 只要有输出就说明 CPU 支持虚拟化;AMD 服务器可用 cat/proc/cpuinfo | grep smv 命令查 看。
[root@kvm ~]# cat /proc/cpuinfo | grep vmx
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon rep_good nopl xtopology tsc_reliable nonstop_tsc eagerfpu pni pclmulqdq vmx ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch invpcid_single ssbd ibrs ibpb stibp ibrs_enhanced tpr_shadow vnmi ept vpid fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid rdseed adx smap clflushopt clwb sha_ni xsaveopt xsavec xgetbv1 arat umip pku ospke gfni vaes vpclmulqdq movdiri movdir64b md_clear spec_ctrl intel_stibp flush_l1d arch_capabilities检查 KVM 模块是否安装。
[root@kvm ~]# lsmod | grep kvm
kvm_intel 188740 0
kvm 637515 1 kvm_intel
irqbypass 13503 1 kvm
3)开启 libvirtd 服务
安装完成后还需要开启 libvirtd 服务,以开启相关支持。
[root@kvm ~]# systemctl start libvirtd
[root@kvm ~]# systemctl enable libvirtd2.2、部署 GlusterFS
在所有节点上执行如下命令:
1)关闭防火墙、SELiunx
将 4 台服务器的主机名分别更改为 node1、node2、node3、node4。下面以 node1 为例进行操作演示。
[root@node1 ~]# systemctl stop firewalld && systemctl disable firewalld
[root@node1 ~]# hostname
node1
[root@node1 ~]# getenforce
Disabled
2)编写 hosts 文件
在所有服务上面操作
[root@node1 ~]# vim /etc/hosts
......//省略部分内容
192.168.23.211 node1
192.168.23.212 node2
192.168.23.213 node3
192.168.23.214 node4
192.168.23.215 kvm3)安装软件
本实验采用官方 YUM 源安装 GlusterFS 所需要软件,具体安装方法如下(在所有节点上操作)。下面以 node1 为例进行操作演示。
[root@node1 ~]# yum -y install centos-release-gluster
[root@node1 ~]# yum -y install glusterfs glusterfs-server glusterfs-fuse
4)启动 Glusterfs
在所有节点执行以下操作,下面以 node1 为例进行操作演示。
[root@node1 ~]# systemctl start glusterd
[root@node1 ~]# systemctl enable glusterd 5)在 node1 上添加所有节点
如果报错请检查防火墙、SELinux、主机名及 hosts 文件是否正确。
[root@node1 ~]# gluster peer probe node2
peer probe: success
[root@node1 ~]# gluster peer probe node3
peer probe: success
[root@node1 ~]# gluster peer probe node4
peer probe: success6)查看集群状态
[root@node1 ~]# gluster peer status
Number of Peers: 3
Hostname: node2
Uuid: aed68c41-fb56-4577-90a0-0e7a039a4011
State: Peer in Cluster (Connected)
Hostname: node3
Uuid: 1fd11f2a-6b76-49f8-8a7e-e07d5838ec33
State: Peer in Cluster (Connected)
Hostname: node4
Uuid: 8451c042-3334-45c9-88ed-381f4a8073a8
State: Peer in Cluster (Connected)
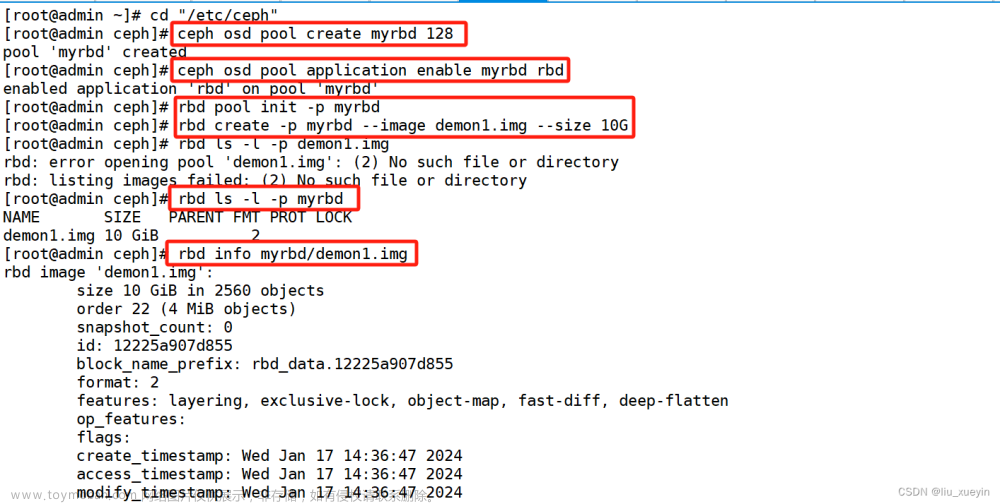
2.3、创建 Glusterfs 分布式复制卷
当前一共有四个节点,设置为 2x2=4,就是 2 个节点为一组,一个卷组两个节点会有相同的数据。从而达到虚拟机数据分布式存储并有冗余备份。分布式复制卷详细介绍已在之 前章节讲解过,这里不再赘述。
在所有节点创建/data 目录。
[root@node1 ~]# mkdir /data创建分布式复制卷。 (node1 上操作)
[root@node1 ~]# gluster volume create models replica 2 node1:/data node2:/data node3:/data node4:/data force
volume create: models: success: please start the volume to access data查看 models 卷。
[root@node1 ~]# gluster volume info models
Volume Name: models
Type: Distributed-Replicate
Volume ID: def78fce-bd55-4f78-b69e-002b6c678d43
Status: Created
Snapshot Count: 0
Number of Bricks: 2 x 2 = 4
Transport-type: tcp
Bricks:
Brick1: node1:/data
Brick2: node2:/data
Brick3: node3:/data
Brick4: node4:/data
Options Reconfigured:
cluster.granular-entry-heal: on
storage.fips-mode-rchecksum: on
transport.address-family: inet
nfs.disable: on
performance.client-io-threads: off
启动 models 卷。
[root@node1 ~]# gluster volume start models
volume start: models: success2.4、客户端挂载 Glusterfs 卷
1)安装 glusterfs 客户端软件。
[root@kvm ~]# yum -y install glusterfs glusterfs-fuse2)创建挂载目录,并挂载 models 卷。
[root@kvm ~]# mkdir /kvmdata
[root@kvm ~]# mount -t glusterfs node1:models /kvmdata/3)查看挂载卷
文件系统 容量 已用 可用 已用% 挂载点
devtmpfs 3.9G 0 3.9G 0% /dev
tmpfs 3.9G 0 3.9G 0% /dev/shm
tmpfs 3.9G 12M 3.9G 1% /run
tmpfs 3.9G 0 3.9G 0% /sys/fs/cgroup
/dev/mapper/centos-root 28G 2.0G 27G 8% /
/dev/sda1 1014M 139M 876M 14% /boot
tmpfs 797M 0 797M 0% /run/user/0
node1:models 200G 2.1G 198G 2% /kvmdata2.5、KVM 使用卷创建虚拟机
KVM 指定虚拟机安装路径到已挂载的目录下,从而达到虚拟机文件分布式存储并有冗余功能。
1)创建目录
[root@kvm ~]# cd /kvmdata/
[root@kvm kvmdata]# mkdir iso
[root@kvm kvmdata]# mkdir store
[root@kvm kvmdata]# ls
iso store2)上传镜像
将镜像上传到 iso 目录
[root@kvm ~]# ls /kvmdata/iso/
CentOS-7-x86_64-DVD-2207-02.iso3)创建虚拟机
[root@kvm ~]# virt-install -n test01 -r 1024 --vcpus=1 --disk path=/kvmdata/store/test01.qcow2,size=10 -w bridge:br0 --virt-type=kvm --accelerate --autostart -c /kvmdata/iso/CentOS-7-x86_64-DVD-2207-02.iso --vnc --vncport=5901 --vnclisten=0.0.0.0
[root@kvm ~]# virsh list --all
Id 名称 状态
----------------------------------------------------
2 test01 running4)验证存储
在四台节点上查看目录里是否存在虚拟机文件。可以看出虚拟机文件已经存放在第一组 node1、node2 里。 文章来源:https://www.toymoban.com/news/detail-850245.html
[root@node1 ~]# ll /data/store/
总用量 2154316
-rw------- 2 107 107 10739318784 4月 12 23:18 test01.qcow2
[root@node2 ~]# ll /data/store/
总用量 2154316
-rw------- 2 107 107 10739318784 4月 12 23:18 test01.qcow2
[root@node3 ~]# ll /data/store/
总用量 0
[root@node4 ~]# ll /data/store/
总用量 0从上面结果看,虚拟机文件已同步到卷组 node1、node2 当中,再发生宿主机宕机后, 将不会影响虚拟机正常使用。文章来源地址https://www.toymoban.com/news/detail-850245.html
到了这里,关于KVM + GFS 分布式存储的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!