笔记本也能部署本地AI模型进行聊天啦!
博主是AI新手,如有不对还请评论区指教~
这里介绍mac的部署方式,win也可以实现。
本案例使用到:ollama + nextjs + langchain.js + milvus 来实现知识库问答和聊天。
ollama:本地运行模型服务
nextjs:前端框架项目
langchain.js:调用模型服务并对话
milvus:向量数据库
开源代码:GitHub - huangj17/gemma-nextjs: 使用nextjs本地化部署AI大模型gemma
1、下载 ollama 在本地运行
- 安装教程:22K star的超强工具:Ollama,一条命令在本地跑 Llama2 - 知乎
- 官方文档:gemma 安装后使用 ollama run gemma:2b 命令把gemma:2b模型拉取到本地运行
2、创建一个nextjs项目
- 安装教程:Getting Started: Installation | Next.js (前端小伙伴就很清楚啦~)
- 创建后安装langchainjs依赖包,yarn add langchain @langchain/community Installation | 🦜️🔗 Langchain
- 安装完成yarn dev跑起来
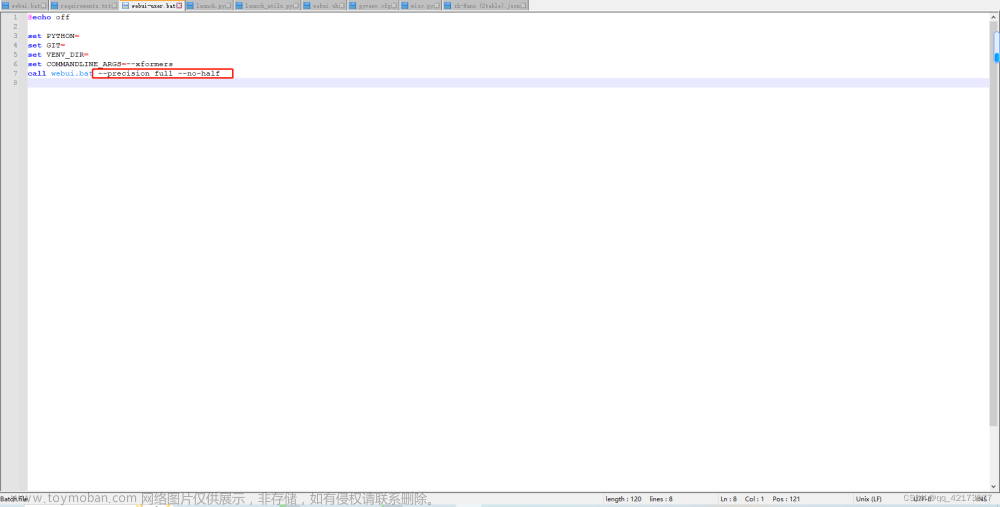
- 创建一个ollama实例:
import { ChatOllama } from "@langchain/community/chat_models/ollama"; const chatModel = new ChatOllama({ baseUrl: "http://localhost:11434", // Default value model: "gemma:2b", }); - 发起对话:
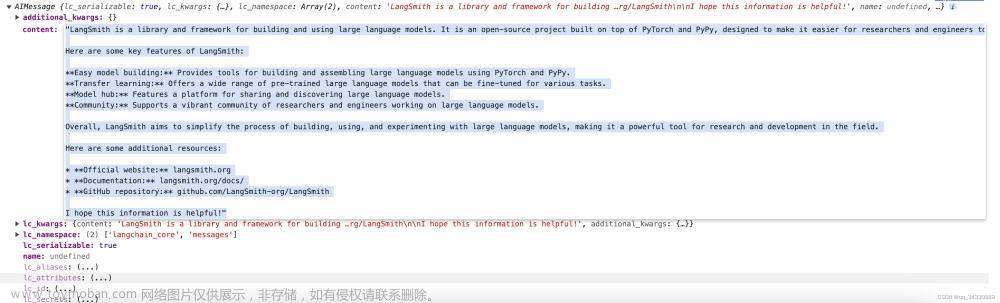
await chatModel.invoke("what is LangSmith?"); -
你就会得到一个结果:
 文章来源:https://www.toymoban.com/news/detail-850263.html
文章来源:https://www.toymoban.com/news/detail-850263.html
3、安装Milvus向量数据库
- 安装教程:Install Milvus Standalone with Docker Milvus documentation 从官网下载安装。
- 安装完成后可以使用官方桌面化工具 Attu 来进行连接查看向量数据。
- 输入默认Milvus服务地址进行连接

- 连接后可以查看集合也可以进行向量查询

4、使用langchainjs连接向量库
- cd到next项目安装milvus依赖包(注意milvus包仅限node环境运行)
yarn add @zilliz/milvus2-sdk-node - 在next项目中 src/pages/api 新建milvus.ts文件
import { OllamaEmbeddings } from "@langchain/community/embeddings/ollama"; import { Milvus } from "@langchain/community/vectorstores/milvus"; import type { NextApiRequest, NextApiResponse } from "next"; type ResponseData = { result: any; }; export default async function handler( req: NextApiRequest, res: NextApiResponse<ResponseData> ) { const embeddings = new OllamaEmbeddings({ model: "gemma:2b", baseUrl: "http://localhost:11434", }); const vectorStore = await Milvus.fromTexts( [ "Tortoise: Labyrinth? Labyrinth? Could it Are we in the notorious Little\ Harmonic Labyrinth of the dreaded Majotaur?", "Achilles: Yiikes! What is that?", "Tortoise: They say-although I person never believed it myself-that an I\ Majotaur has created a tiny labyrinth sits in a pit in the middle of\ it, waiting innocent victims to get lost in its fears complexity.\ Then, when they wander and dazed into the center, he laughs and\ laughs at them-so hard, that he laughs them to death!", "Achilles: Oh, no!", "Tortoise: But it's only a myth. Courage, Achilles.", ], [{ id: 2 }, { id: 1 }, { id: 3 }, { id: 4 }, { id: 5 }], embeddings, { collectionName: "goldel_escher_bach", clientConfig: { address: "localhost:19530", token: "root:Milvus", ssl: false, }, } ); const response = await vectorStore.similaritySearch("scared", 2); res.status(200).json({ result: response }); }注意:OllamaEmbeddings第一个参数填写本地运行的ollama环境配置。clientConfig为milvus配置文章来源地址https://www.toymoban.com/news/detail-850263.html
- 返回前端页面index.tsx中使用axios或者fetch调用上面的接口 /api/milvus GET 就能看到返回的查询向量结果了
5、用向量结果配合ollama运行的gemma模型进行提问
- 回到前端页面,创建ollama聊天模型,创建提示词结合上下文来进行对话
const chatModel = new ChatOllama({ baseUrl: "http://localhost:11434", model: "gemma:2b", }); const prompt = ChatPromptTemplate.fromMessages([ ["user", "{input}"], [ "system", `您是一位经验丰富的文档编写专家。使用所提供的上下文:\n\n{context},尽最大努力回答用户的问题。生成给定问题的简明答案。不要发重复文字!`, ], ]); const documentChain = await createStuffDocumentsChain({ llm: chatModel, prompt: prompt, }); const invoke = await documentChain.invoke({ input: 'Who is Tortoise talking to?', context: result.map((item: any) => new Document({ ...item })), // result接口返回的向量结果 }); - 搞定!打印invoke就可以看到最终结果啦!
到了这里,关于使用nextjs本地化部署AI大模型gemma的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!