人工智能专栏文章汇总:人工智能学习专栏文章汇总-CSDN博客
本篇目录
1. LLMChain
2. Sequential Chains
SimpleSequentialChain
SequentialChain
3. Router Chain
4. Documents Chain
5. Document Loaders(文档加载器)
6. Text Splitter(文本分割器)
7. Vectorstores(向量存储器)
8. Retriever(检索器)
9. Agent(代理)
10. Langchain实战之 - 基于知识库+文心大模型的问答AI
LangChain是一个基于大语言模型(如ChatGPT)用于构建端到端语言模型应用的 Python 框架。它提供了一套工具、组件和接口,可简化创建由大型语言模型 (LLM) 和聊天模型提供支持的应用程序的过程。LangChain 可以轻松管理与语言模型的交互,将多个组件链接在一起,以便在不同的应用程序中使用。
以下分别介绍Langchain的使用方法以及实战代码,本代码全部基于百度文心大模型做了相应修改,全都是实际跑通的代码,可供参考。
Chain链有以下几种主要方式:
1. LLMChain
LLMChain是使用单个语言模型的链式结构。它接收用户的查询,将其发送给语言模型进行处理,并将模型生成的响应返回给用户。结合prompt使用:
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain_wenxin.chat_models import ChatWenxin
from langchain.schema import HumanMessage
WENXIN_APP_Key = "你自己的KEY"
WENXIN_APP_SECRET = "你自己的SECRET"
#创建LLMChain的大模型,这里我们用的是文心大模型
chat = ChatWenxin(
temperature=0.9,
model="ernie-bot-turbo",
baidu_api_key = WENXIN_APP_Key,
baidu_secret_key = WENXIN_APP_SECRET,
verbose=True,
)
#第一种方式:直接用ChatPromptTemplate产生chat messages,并输入给chat模型
print("\n方式一:")
template_str = "描述生产{product}的公司的一个最佳名称是什么?只返回一个答案,答案限定为3到5字。"
prompt_template = ChatPromptTemplate.from_template(template_str)
messages = prompt_template.format_messages(product="肥皂")
res = chat(messages)
print(res.content)
#第二种方式:使用LLMChain,交给LLMChain来处理
print("\n方式二:")
template = "描述生产{product}的公司的一个最佳名称是什么?只返回一个答案,答案限定为3到5字。"
prompt = PromptTemplate(input_variables=["product"], template=template)
llm_chain = LLMChain(prompt=prompt, llm=chat)
res = llm_chain.run(product="糖果")
print(res)这里面Langchain会先生成一个prompt:“描述生产糖果的公司的一个最佳名称是什么?只返回一个答案,答案限定为3到5字。”
然后将这个prompt发给文心一言大模型处理,并获取大模型的响应数据。代码里实现了两种不同的方式,可以更好的理解Langchain的定位。
另外,通过在prompt template里引入{chat_history}变量以及memory机制,Langchain可以实现多轮对话,实例代码如下:
from langchain.chains import LLMChain
from langchain.memory import ConversationBufferMemory
from langchain.prompts import PromptTemplate
from langchain_wenxin.chat_models import ChatWenxin
WENXIN_APP_Key = "你自己的KEY"
WENXIN_APP_SECRET = "你自己的SECRET"
chat = ChatWenxin(
temperature=0.9,
model="ernie-bot-turbo",
baidu_api_key = WENXIN_APP_Key,
baidu_secret_key = WENXIN_APP_SECRET,
verbose=True,
)
template = """You are a chatbot having a conversation with a human. Please answer as briefly as possible.
{chat_history}
Human: {human_input}
Chatbot:"""
prompt = PromptTemplate(
input_variables=["chat_history", "human_input"], template=template
)
memory = ConversationBufferMemory(memory_key="chat_history")
llm_chain = LLMChain(
llm=chat,
prompt=prompt,
verbose=False,
memory=memory,
)
res = llm_chain.run(human_input="彩虹有几种颜色?前三种是哪些?")
print(res)
res = llm_chain.run(human_input="后四种呢?")
print(res)2. Sequential Chains
是顺序执行的链式结构,可以按照特定的顺序连接多个处理组件。
SimpleSequentialChain
SimpleSequentialChain是最基本的一种Sequential Chains,因为它只有一个输入和一个输出,其中前一个chain的输出为后一个chain的输入。
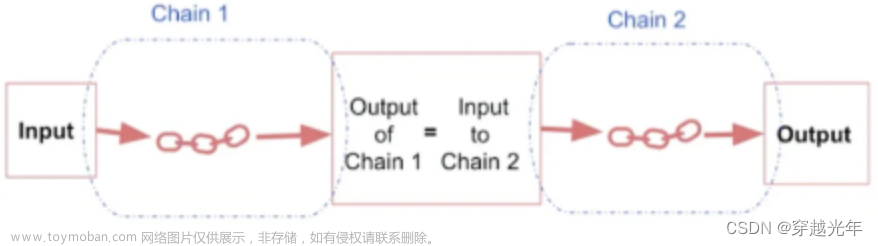
这里需要创建两个chain, 一个chain负责给公司取名字,另一个chain负责就公司的名字生成20个字左右的描述信息,最后将这两个chain组合在一起,创建一个新的chain。
from langchain.prompts import PromptTemplate
from langchain.prompts import ChatPromptTemplate
from langchain.chains import LLMChain
from langchain_wenxin.chat_models import ChatWenxin
from langchain.schema import HumanMessage
from langchain.chains import SimpleSequentialChain
WENXIN_APP_Key = "你自己的KEY"
WENXIN_APP_SECRET = "你自己的SECRET"
#创建LLMChain的大模型,这里我们用的是文心大模型
llm = ChatWenxin(
temperature=0.4,
model="ernie-bot-turbo",
baidu_api_key = WENXIN_APP_Key,
baidu_secret_key = WENXIN_APP_SECRET,
verbose=True,
)
# prompt template 1
first_prompt = ChatPromptTemplate.from_template(
"为生产{product}的公司取一个最佳名称,只返回三个名称。"
)
# Chain 1
chain_one = LLMChain(llm=llm, prompt=first_prompt, output_key="companys")
# prompt template 2
second_prompt = ChatPromptTemplate.from_template(
"为公司名称编写 20 个字的描述:{companys}"
)
# chain 2
chain_two = LLMChain(llm=llm, prompt=second_prompt)
# 将chain1和chain2组合在一起生成一个新的chain.
overall_simple_chain = SimpleSequentialChain(chains=[chain_one, chain_two],
verbose=True
)
#执行新的chain
res = overall_simple_chain.run("糖果")
#print(res)输出结果:

SequentialChain
SequentialChain与SimpleSequentialChain的区别在于它可以有多个输入和输出,而SimpleSequentialChain只有一个输入和输出,如下图所示:

功能是要让llm对前面导入的用户评语进行分析,并给出回复,因为用户的评语可能使用的是多种不同的语言,为此需要让chain能够识别用户评语使用的是那种语言,并将其翻译成中文,最后给出回复,具体来说包含以下功能和步骤:
-
将用户评论翻译成中文
-
用一句话概括用户评论
-
识别出用户评论使用的语言
-
根据2 3的结果按原始评论语言生成回复
-
将回复翻译成中文
from langchain.prompts import PromptTemplate
from langchain.prompts import ChatPromptTemplate
from langchain.chains import LLMChain
from langchain_wenxin.chat_models import ChatWenxin
from langchain.schema import HumanMessage
from langchain.chains import SimpleSequentialChain
from langchain.chains import SequentialChain
WENXIN_APP_Key = "你自己的KEY"
WENXIN_APP_SECRET = "你直接的SECRET"
#创建LLMChain的大模型,这里我们用的是文心大模型
llm = ChatWenxin(
temperature=0.4,
model="ernie-bot",
baidu_api_key = WENXIN_APP_Key,
baidu_secret_key = WENXIN_APP_SECRET,
verbose=True,
)
# prompt template 1: 将评论翻译成中文
first_prompt = ChatPromptTemplate.from_template(
"将下面的评论翻译成中文:"
"\n\n{Review}"
)
# chain 1: input= Review and output= Chinese_Review
chain_one = LLMChain(llm=llm, prompt=first_prompt,
output_key="Chinese_Review"
)
#概括评论
second_prompt = ChatPromptTemplate.from_template(
"你能用 1 句话概括以下评论吗:"
"\n\n{Chinese_Review}"
)
# chain 2: input= Chinese_Review and output= summary
chain_two = LLMChain(llm=llm, prompt=second_prompt,
output_key="summary"
)
# prompt template 3: 识别评论使用的语言
third_prompt = ChatPromptTemplate.from_template(
"下面的评论使用的是什么语言?:\n\n{Review}"
)
# chain 3: input= Review and output= language
chain_three = LLMChain(llm=llm, prompt=third_prompt,
output_key="language"
)
# prompt template 4: 生成回复信息
fourth_prompt = ChatPromptTemplate.from_template(
"编写对以下摘要的后续回复:"
"\n\n摘要:{summary}"
)
# chain 4: input= summary, language and output= followup_message
chain_four = LLMChain(llm=llm, prompt=fourth_prompt,
output_key="followup_message"
)
# prompt template 5: 将回复信息翻译成英文
five_prompt = ChatPromptTemplate.from_template(
"将下面的评论翻译成英文:"
"\n\n{followup_message}"
)
# chain 5: input= followup_message and output= Chinese_followup_message
chain_five = LLMChain(llm=llm, prompt=five_prompt,
output_key="English_followup_message"
)
overall_chain = SequentialChain(
chains=[chain_one, chain_two, chain_three, chain_four,chain_five],
input_variables=["Review"],
output_variables=["language","Chinese_Review", "summary",
"followup_message","English_followup_message"],
verbose=True
)
review = "this restaurant is very good, i strongly recommend it!"
res = overall_chain(review)
print("res:", res)输出结果:

3. Router Chain
根据信息的内容将其传送到不同的chain,而每个chain的职能是只擅长回答自己所属领域的问题,那么在这种场景下就需要一种具有"路由器"功能的chain来将信息传输到不同职能的chain。

有多个不同职能的chain,它们负责回复关于不同学科领域的用户问题,比如数学chain,历史chain,物理chain,计算机chain,每个chain都只擅长回复自己专业领域的问题,这里我们还有一个路由chain, 它的作用是识别用户所提问题属于哪个领域,然后将问题传输给那个领域的chain,让其来完成回答用户问题的功能。
from langchain.prompts import PromptTemplate
from langchain.prompts import ChatPromptTemplate
from langchain.chains import LLMChain
from langchain_wenxin.chat_models import ChatWenxin
from langchain.schema import HumanMessage
from langchain.chains.router import MultiPromptChain #overall chains
from langchain.chains.router.llm_router import LLMRouterChain, RouterOutputParser
WENXIN_APP_Key = "你自己的KEY"
WENXIN_APP_SECRET = "你自己的SECRET"
#创建LLMChain的大模型,这里我们用的是文心大模型
llm = ChatWenxin(
temperature=0.1,
model="ernie-bot",
baidu_api_key = WENXIN_APP_Key,
baidu_secret_key = WENXIN_APP_SECRET,
verbose=True,
)
physics_template="""你是一位非常聪明的物理学教授。\
你擅长以简洁易懂的方式回答有关物理的问题。 \
当你不知道某个问题的答案时,你就承认你不知道。
这里有一个问题:
{input}"""
math_template="""你是一位非常优秀的数学家。\
你很擅长回答数学问题。 \
你之所以如此出色,是因为你能够将难题分解为各个组成部分,\
回答各个组成部分,然后将它们组合起来回答更广泛的问题。
这里有一个问题:
{input}"""
history_template = """你是一位非常优秀的历史学家。\
你对各个历史时期的人物、事件和背景有深入的了解和理解。 \
你有能力思考、反思、辩论、讨论和评价过去。 \
你尊重历史证据,并有能力利用它来支持你的解释和判断。
这里有一个问题:
{input}"""
computerscience_template="""你是一位成功的计算机科学家。\
你有创造力,协作精神,前瞻性思维,自信,有很强的解决问题的能力,\
对理论和算法的理解,以及出色的沟通能力。\
你很擅长回答编程问题。
你是如此优秀,因为你知道如何通过描述一个机器可以很容易理解的命令步骤来解决问题,\
你知道如何选择一个解决方案,在时间复杂度和空间复杂度之间取得良好的平衡。
这里有一个问题:
{input}"""
prompt_infos = [
{
"name": "physics",
"description": "擅长回答有关物理方面的问题",
"prompt_template": physics_template
},
{
"name": "math",
"description": "擅长回答有关数学方面的问题",
"prompt_template": math_template
},
{
"name": "history",
"description": "擅长回答有关历史方面的问题",
"prompt_template": history_template
},
{
"name": "computer science",
"description": "擅长回答有关计算机科学方面的问题",
"prompt_template": computerscience_template
}
]
#创建目标chain {'name': chain}
destination_chains = {}
for p_info in prompt_infos:
name = p_info["name"]
prompt_template = p_info["prompt_template"]
prompt = ChatPromptTemplate.from_template(template=prompt_template)
chain = LLMChain(llm=llm, prompt=prompt)
destination_chains[name] = chain
#print(destination_chains)
#创建要写入prompt的chain string
destinations = [f"{p['name']}: {p['description']}" for p in prompt_infos]
#print("destinations: \n", destinations)
destinations_str = "\n".join(destinations)
#print(destinations_str)
#default prompt,无法被route的input,用default LLM来处理
default_prompt = ChatPromptTemplate.from_template("{input}")
default_chain = LLMChain(llm=llm, prompt=default_prompt)
MULTI_PROMPT_ROUTER_TEMPLATE = """
给定一个原始文本输入到一个语言模型并且选择最适合输入的模型提示语。你会获得可用的提示语的名称以及该提示语最合适的描述。
记住:任何情况下都要使用原始文本输入。
<< FORMATTING >>
返回一个 Markdown 代码片段,其中 JSON 对象的格式如下:
```json
{{{{
"destination": string
"next_inputs": string
}}}}
```
记住: "destination"的值需要从下面"CANDIDATE PROMPTS"里挑选一个和原始文本输入内容最匹配的值。如果没有匹配的则把值设为"default"
记住: "next_inputs"的值就是给定的原始文本输入
<< CANDIDATE PROMPTS >>
{destinations}
<< INPUT >>
{{input}}
<< OUTPUT (must include ```json at the start of the response) >>
<< OUTPUT (must end with ```) >>
"""
router_template = MULTI_PROMPT_ROUTER_TEMPLATE.format(
destinations=destinations_str
)
#print(router_template)
router_prompt = PromptTemplate(
template=router_template,
input_variables=["input"],
output_parser=RouterOutputParser(),
)
#print("\n router_prompt: \n", router_prompt)
#创建route chain
router_chain = LLMRouterChain.from_llm(llm, router_prompt, verbose=True)
chain = MultiPromptChain(router_chain=router_chain,
destination_chains=destination_chains,
default_chain=default_chain, verbose=True
)
#response = chain.run("2+2等于几?")
#response = chain.run("重力是什么?")
#response = chain.run("武则天是谁?")
response = chain.run("python编程语言有什么特点?")
#response = chain.run("爱情是什么?")
print("response: ", response)输出结果:

4. Documents Chain
下面的 4 种 Chain 主要用于 Document 的处理,在基于文档生成摘要、基于文档的问答等场景中经常会用到。
-
StuffDocumentsChain: 这种链最简单直接,是将所有获取到的文档作为 context 放入到 Prompt 中,传递到 LLM 获取答案。

-
RefineDocumentsChain: 是通过迭代更新的方式获取答案。先处理第一个文档,作为 context 传递给 llm,获取中间结果 intermediate answer。然后将第一个文档的中间结果以及第二个文档发给 llm 进行处理,后续的文档类似处理。

-
MapReduceDocumentsChain: 先通过 LLM 对每个 document 进行处理,然后将所有文档的答案在通过 LLM 进行合并处理,得到最终的结果。

-
MapRerankDocumentsChain: 和 MapReduceDocumentsChain 类似,先通过 LLM 对每个 document 进行处理,每个答案都会返回一个 score,最后选择 score 最高的答案。

5. Document Loaders(文档加载器)
LangChain 通过 Loader 加载外部的文档,转化为标准的 Document 类型。langchain提供了很多文档加载的类,以便进行不同的文件加载,这些类都通过 langchain.document_loaders 引入。
例如加载文本:UnstructuredFileLoader(txt文件读取)、UnstructuredFileLoader(word文件读取)、MarkdownTextSplitter(markdown文件读取)、UnstructuredPDFLoader(PDF文件读取)
from langchain.document_loaders import UnstructuredFileLoader
# 加载单文本
loader = UnstructuredFileLoader("/work/langchain/data/LLM_Survey_Chinese_V1.pdf")
# 将文本转成 Document 对象
document = loader.load()例如加载目录:
from langchain.document_loaders import DirectoryLoader
# 加载文件夹中的所有.md类型的文件
loader = DirectoryLoader('/work/langchain/data/', glob='**/*.txt')
# 将数据转成 Document 对象,每个文件会作为一个 Document
documents = loader.load()6. Text Splitter(文本分割器)
LLM 一般都会限制上下文窗口的大小,有 4k、16k、32k 等。针对大文本就需要进行文本分割,常用的文本分割器为 RecursiveCharacterTextSplitter(默认)、CharacterTextSplitter,可以通过 separators 指定分隔符。其先通过第一个分隔符进行分割,不满足大小的情况下迭代分割。
文本分割主要有 2 个考虑:
1)将语义相关的句子放在一块形成一个 chunk。一般根据不同的文档类型定义不同的分隔符,或者可以选择通过模型进行分割。
2)chunk 控制在一定的大小,可以通过函数去计算。
from langchain.text_splitter import CharacterTextSplitter
# 初始化加载器
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0) # 默认使用\n\n做分割
# 切割加载的 document
split_docs = text_splitter.split_documents(documents)除了控制分割的字符之外,我们还可以控制其他一些内容:
-
length_function:如何计算分块的长度。默认只计算字符数,但通常在这里传递一个标记计数器。
-
chunk_size:分块的最大大小(由长度函数测量)。
-
chunk_overlap:分块之间的最大重叠量。保持一些重叠可以保持分块之间的连续性(例如使用滑动窗口)。
-
add_start_index:是否在元数据中包含每个分块在原始文档中的起始位置。
7. Vectorstores(向量存储器)
通过 Text Embedding models,将文本转为向量,可以进行语义搜索,在向量空间中找到最相似的文本片段。目前支持常用的向量存储有 Faiss、Chroma 等。
Embedding 模型支持 OpenAIEmbeddings、HuggingFaceEmbeddings加载本地模型 等。
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import Chroma
# 初始化 embeddings 对象
embeddings = HuggingFaceEmbeddings(model_name='/shareData/text2vec-base-chinese')
# 将 document 计算 embedding 向量信息并临时存入 Chroma 向量数据库,用于后续匹配查询
db = Chroma.from_documents(split_docs, embeddings, persist_directory="/work/langchain/Chromadb")
# 持久化数据
db.persist()8. Retriever(检索器)
Retriever 接口用于根据非结构化的查询获取文档,一般情况下是文档存储在向量数据库中。
文本检索:
# 文本检索
query = "进程间通信方式有哪些"
docs = db.similarity_search(query)
print('文本检索:%s' % query)
print(docs[0].page_content)向量检索:
# 向量检索
embedding_vector = embeddings.embed_query(query)
docs = db.similarity_search_by_vector(embedding_vector)
print('向量检索:%s' % embedding_vector[0:8])
print(docs[0].page_content)构建本地知识库问答机器人完整示例:
from langchain import PromptTemplate
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import Chroma
from langchain.text_splitter import CharacterTextSplitter
from langchain.document_loaders import DirectoryLoader
from langchain.chains import RetrievalQA
from YiYan import YiYan
# 加载文件夹中的所有.md类型的文件
loader = DirectoryLoader('/work/langchain/data/', glob='**/*.md')
# 将数据转成 document 对象,每个文件会作为一个 document
documents = loader.load()
# 初始化加载器
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
# 切割加载的 document
split_docs = text_splitter.split_documents(documents)
# 初始化 embeddings 对象
embeddings = HuggingFaceEmbeddings(model_name='/shareData/text2vec-base-chinese')
# 将 document 计算 embedding 向量信息并临时存入 Chroma 向量数据库,用于后续匹配查询
# 持久化数据
docsearch = Chroma.from_documents(split_docs, embeddings, persist_directory="/work/langchain/Chromadb")
docsearch.persist()
# 加载数据
docsearch = Chroma(persist_directory="/work/langchain/Chromadb", embedding_function=embeddings)
# 创建问答对象
llm = YiYan()
prompt_template = """基于以下已知信息,简洁和专业的来回答用户的问题。
如果无法从中得到答案,请说 "根据已知信息无法回答该问题" 或 "没有提供足够的相关信息",不允许在答案中添加编造成分,答案请使用代码。
已知内容:
{context}
问题:
{question}"""
prompt = PromptTemplate(template=prompt_template, input_variables=["context", "question"])
chain_type_kwargs = {"prompt": prompt}
qa = RetrievalQA.from_chain_type(llm=llm, retriever=docsearch.as_retriever(), chain_type="stuff",
chain_type_kwargs=chain_type_kwargs, return_source_documents=True)
# 进行问答
query = "mongodb和redis的区别是什么"
res = qa({"query": query})
answer, docs = res['result'], res['source_documents']
print("\n\n> 问题:")
print(query)
print("\n> 回答:")
print(answer)
for document in docs:
print("\n> " + document.metadata["source"] + ":")过程分析:1)将本地文件进行向量化存入Chromadb,2)进行问答请求,本地返回与问题相似度较高的大量文本,调用大模型进行知识抽取问答,返回结果。
9. Agent(代理)
Agents可以看做是一个智能化的流程封装。它基于LLM的CoT能力,动态串联多个Tool或Chain,完成对复杂问题的自动推导和执行解决。
Tool可以认为是Agent中每个单独功能的封装,这些功能可以由第三方在线服务,本地服务,本地可执行程序等不同方式实现,通过开发者自定义Tools封装。通过定义不同的tool,agent就能够通过tool的描述,拼装相关提示,让LLM在特定场景下选择特定的tool来完成任务。可以说,agent的能力很大程度上取决于tool池的深度和广度,以及LLM如何选择tool的能力。

10. Langchain实战之 - 基于知识库+文心大模型的问答AI
方案流程如下:
1. 从文本中构建知识库
2. 将知识库构建为向量库
3. 用问题在向量库中查询相似度最高的文本
4. 将问题和匹配文本一起生成一个prompt
5. 将生成的prompt发送给文心大模型,并获取大模型返回的数据

from langchain.document_loaders import UnstructuredFileLoader
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import FAISS
from sentence_transformers import SentenceTransformer
from langchain.embeddings import HuggingFaceEmbeddings
import requests
#构建知识库loader
loaders = [
PyPDFLoader('car.pdf'),
PyPDFLoader('carbon.pdf')
]
#load知识到知识库docs
docs = []
for loader in loaders:
docs.extend(loader.load())
#print(len(docs))
#print(docs[50])
#将知识库按chunk_size分段
text_splitter = CharacterTextSplitter(chunk_size=300, chunk_overlap=30, separator='\n')
splits = text_splitter.split_documents(docs)
#print(len(splits))
#print(splits[150])
#获取embedding函数
#embeddings = HuggingFaceEmbeddings(model_name='moka-ai/m3e-base')
embeddings = HuggingFaceEmbeddings(model_name="C:\\Users\\aric\\.models\\paraphrase-multilingual-MiniLM-L12-v2")
#构建知识库embedding向量库
vector_store = FAISS.from_documents(splits, embeddings)
question = '政府发布了哪些双碳政策文件'
# 在知识库文本-向量数据库中,匹配相关段落,按相关性倒序排序
K = 5
docs_and_scores = vector_store.similarity_search_with_score(question, k=K)
"""
for i in range(len(docs_and_scores)):
source = docs_and_scores[i][0].metadata['source']
content = docs_and_scores[i][0].page_content
similarity = docs_and_scores[i][1]
print('来源 {} 字数 {} 匹配度 {:.2f}'.format(source, len(content), similarity))
#print(content[:30] + '……')
print(content)
print('------------------')
"""
#生成背景上下文
context = ''
for doc in docs_and_scores:
context += doc[0].page_content
context += '\n\n'
#print(context)
#生成提示词
prompt = '你是一个学习助手,请根据下面的已知信息回答问题,你只需要回答和已知信息相关的问题,如果问题和已知信息不相关,你可以直接回答"不知道" \n问题:{} \n已知信息:{}'.format(question, context)
print(prompt)
#链接百度文心大模型
#声明百度ERNIE类
class BaiduErnie:
host: str = "https://aip.baidubce.com"
client_id: str = ""
client_secret: str = ""
access_token: str = ""
def __init__(self, client_id: str, client_secret: str):
self.client_id = client_id
self.client_secret = client_secret
self.get_access_token()
def get_access_token(self) -> str:
url = f"{self.host}/oauth/2.0/token?grant_type=client_credentials&client_id={self.client_id}&client_secret={self.client_secret}"
response = requests.get(url)
if response.status_code == 200:
self.access_token = response.json()["access_token"]
return self.access_token
else:
raise Exception("获取access_token失败")
def chat(self, messages: list, user_id: str) -> tuple:
if not self.access_token:
self.get_access_token()
url = f"{self.host}/rpc/2.0/ai_custom/v1/wenxinworkshop/chat/eb-instant?access_token={self.access_token}"
data = {"messages": messages, "user_id": user_id}
response = requests.post(url, json=data)
if response.status_code == 200:
resp = response.json()
return resp["result"], resp
else:
raise Exception("请求失败")
#填入文心大模型后台你自己的API信息
user_id = ""
client_id = ""
client_secret = ""
baidu_ernie = BaiduErnie(client_id, client_secret)
def chat(prompt):
messages = []
messages.append({"role": "user", "content": prompt}) # 用户输入
result, response = baidu_ernie.chat(messages, user_id) # 调用接口
return result
chat(prompt)打印结果:
发送给文心大模型的问题:
你是一个学习助手,请根据下面的已知信息回答问题,你只需要回答和已知信息相关的问题,如果问题和已知信息不相关,你可以直接回答"不知道"
问题:政府发布了哪些双碳政策文件
已知信息:8 银行保险机构碳中和战略白皮书1.3中国体系日益完善 ,“双碳”顶层设 计初步完成....
文心大模型的回答:
根据提供的信息,政府已经发布了以下双碳政策文件:
中共中央国务院印发 《关于完整准确全面贯彻新发展理念做好碳达峰碳中和工作的意见》,这份文件是党中央对碳达峰 、碳中和工作进行的系统谋划和总体部署,覆盖碳达峰 、碳中和两个阶段,明确了我国实现碳达峰 、碳中和的时间表,部署了碳达峰 、碳中和工作的路线图、施工图,是总管长远的顶层设计,在碳达峰 、碳中和政策体系中发挥统领作用,是“1+N”中的“1”。
2019年银保监会发布 《绿色信贷项目节能减排量测算指引》,为碳效益的测算提供了方法,同时为绿色信贷项目测算节能减排量提供基准。
2021年,中国人民银行发布 《金融机构环境信息披露指南》,对金融机构投融资业务的碳核算提出披露要求,填补了相关领域绿色金融行业标准的空白;同年印发 《金融机构环境信息披露操作手册(试行)》和《金融机构碳核算技术指南(试行)》,在绿色金融改革流程,指导分行加大对碳减排重点领域支持力度 。
此外,安永提供金融碳中和战略制定框架,协助金融机构在实现碳中和过程中落地四个重要阶段和相应的核心步骤,并应用完整的解决方案。同时,某国有银行A制定了《某国有银行A碳达峰碳中和工作方案(试行)》,将“双碳”工作定位为绿色金融工作的重要组成部分。针对金融机构的碳核算,我国金融监管部门在气候信息披露的要求上也愈加严格,陆续出台多项政策为金融机构碳核算路径予以指导。——————————————————————————————————————文章来源:https://www.toymoban.com/news/detail-850458.html
关注微信公众号【数字众生】即刻获取干货满满的 “AI学习大礼包” 和 “AI副业变现指南”文章来源地址https://www.toymoban.com/news/detail-850458.html
到了这里,关于人工智能学习与实训笔记(九):Langchain + 百度大模型实战案例的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!