目录
一、目的与要求
二、实验内容
三、实验步骤
1、安装Hadoop和Spark
2、HDFS常用操作
3、Spark读取文件系统的数据
四、结果分析与实验体会
一、目的与要求
1、掌握在Linux虚拟机中安装Hadoop和Spark的方法;
2、熟悉HDFS的基本使用方法;
3、掌握使用Spark访问本地文件和HDFS文件的方法。
二、实验内容
1、安装Hadoop和Spark
进入Linux系统,完成Hadoop伪分布式模式的安装。完成Hadoop的安装以后,再安装Spark(Local模式)。
2、HDFS常用操作
使用Hadoop提供的Shell命令完成如下操作:
(1)启动Hadoop,在HDFS中创建用户目录“/user/你的名字的拼音”。以张三同学为例,创建 /user/zhangsan ,下同;
(2)在Linux系统的本地文件系统的“/home/zhangsan”目录下新建一个文本文件test.txt,并在该文件中至少十行英文语句,然后上传到HDFS的“/user/zhangsan”目录下;
(3)把HDFS中“/user/zhangsan”目录下的test.txt文件,下载到Linux系统的本地文件系统中的“/tmp”目录下;
(4)将HDFS中“/user/zhangsan”目录下的test.txt文件的内容输出到终端中进行显示;
(5)在HDFS中的“/”目录下,创建子目录input,把HDFS中“/user/zhangsan”目录下的test.txt文件,复制到“/input”目录下;
(6)删除HDFS中“/user/zhangsan”目录下的test.txt文件;
(7)查找HDFS中所有的 .txt文件;
(8)使用hadoop-mapreduce-examples-3.1.3.jar程序对/input目录下的文件进行单词个数统计,写出运行命令,并验证运行结果。
3、Spark读取文件系统的数据
(1)在pyspark中读取Linux系统本地文件“/home/zhangsan/test.txt”,然后统计出文件的行数;
(2)在pyspark中读取HDFS系统文件“/user/zhangsan/test.txt”,然后统计出文件的行数;
(3)编写独立应用程序,读取HDFS系统文件“/user/zhangsan/test.txt”,然后统计出文件的行数;通过 spark-submit 提交到 Spark 中运行程序。
三、实验步骤
1、安装Hadoop和Spark
进入Linux系统,完成Hadoop伪分布式模式的安装。完成Hadoop的安装以后,再安装Spark(Local模式)。具体安装步骤可以参照我前面写的博客:
大数据存储技术(1)—— Hadoop简介及安装配置-CSDN博客https://blog.csdn.net/Morse_Chen/article/details/134833801Spark环境搭建和使用方法-CSDN博客https://blog.csdn.net/Morse_Chen/article/details/134979681
2、HDFS常用操作
(1)启动Hadoop,在HDFS中创建用户目录“/user/你的名字的拼音”。以张三同学为例,创建 /user/zhangsan ,下同;
[root@bigdata zhc]# start-dfs.sh
[root@bigdata zhc]# jps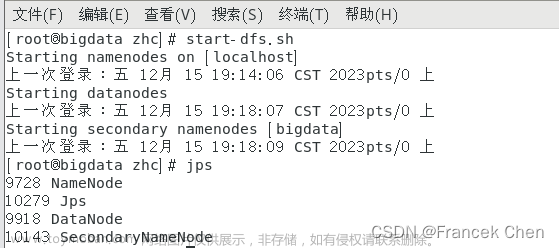
[root@bigdata zhc]# hdfs dfs -mkdir -p /user/zhc
[root@bigdata zhc]# hdfs dfs -ls /user 
(2)在Linux系统的本地文件系统的“/home/zhangsan”目录下新建一个文本文件test.txt,并在该文件中至少十行英文语句,然后上传到HDFS的“/user/zhangsan”目录下;
[root@bigdata zhc]# cd /home/zhc
[root@bigdata zhc]# vi test.txt
[root@bigdata zhc]# hdfs dfs -put /home/zhc/test.txt /user/zhctest.txt 文件内容如下:
welcome to linux
hello hadoop
spark is fast
hdfs is good
start pyspark
use python
scala and R
great success
I love spark
ten

这里可以看到上传成功了。
(3)把HDFS中“/user/zhangsan”目录下的test.txt文件,下载到Linux系统的本地文件系统中的“/tmp”目录下;
[root@bigdata zhc]# hdfs dfs -get /user/zhc/test.txt /tmp/
(4)将HDFS中“/user/zhangsan”目录下的test.txt文件的内容输出到终端中进行显示;
[root@bigdata zhc]# hdfs dfs -cat /user/zhc/test.txt
(5)在HDFS中的“/”目录下,创建子目录input,把HDFS中“/user/zhangsan”目录下的test.txt文件,复制到“/input”目录下;
[root@bigdata zhc]# hdfs dfs -cp /user/zhc/test.txt /input/
(6)删除HDFS中“/user/zhangsan”目录下的test.txt文件;
[root@bigdata zhc]# hdfs dfs -rm -f /user/zhc/test.txt
(7)查找HDFS中所有的 .txt文件;
[root@bigdata zhc]# hdfs dfs -ls -R / | grep -i '\.txt$'
(8)使用hadoop-mapreduce-examples-3.1.3.jar程序对/input目录下的test.txt文件进行单词个数统计,写出运行命令,并验证运行结果。
注意:在做这一步之前,要先启动yarn进程;
指定输出结果的路径/output,该路径不能已存在。
先切换到 /usr/local/servers/hadoop/share/hadoop/mapreduce 路径下,然后再开始统计单词个数。
[root@bigdata zhc]# cd /usr/local/servers/hadoop/share/hadoop/mapreduce
[root@bigdata mapreduce]# hadoop jar hadoop-mapreduce-examples-3.1.3.jar wordcount /input/test.txt /output
输入命令查看HDFS文件系统中/output目录下的结果。
[root@bigdata mapreduce]# hdfs dfs -ls /output
[root@bigdata mapreduce]# hdfs dfs -cat /output/part-r-00000
3、Spark读取文件系统的数据
先在终端启动Spark。
[root@bigdata zhc]# pyspark
(1)在pyspark中读取Linux系统本地文件“/home/zhangsan/test.txt”,然后统计出文件的行数;
>>> textFile=sc.textFile("file:///home/zhc/test.txt")
>>> linecount=textFile.count()
>>> print(linecount)
(2)在pyspark中读取HDFS系统文件“/user/zhangsan/test.txt”(如果该文件不存在,请先创建),然后统计出文件的行数;
注意:由于在第2题的(6)问中,已经删除了HDFS中“/user/zhangsan”目录下的test.txt文件,所以这里要重新将test.txt文件从本地系统上传到HDFS中。
[root@bigdata zhc]# hdfs dfs -put /home/zhc/test.txt /user/zhc
>>> textFile=sc.textFile("hdfs://localhost:9000/user/zhc/test.txt")
>>> linecount=textFile.count()
>>> print(linecount)

(3)编写独立应用程序,读取HDFS系统文件“/user/zhangsan/test.txt”,然后统计出文件的行数;通过 spark-submit 提交到 Spark 中运行程序。
[root@bigdata mycode]# vi CountLines_hdfs.py
[root@bigdata mycode]# spark-submit CountLines_hdfs.py CountLines_hdfs.py文件内容如下:
from pyspark import SparkContext
FilePath = "hdfs://localhost:9000/user/zhc/test.txt"
sc = SparkContext("local","Simple App")
data = sc.textFile(FilePath).cache( )
print("文件行数:",data.count()) 文章来源:https://www.toymoban.com/news/detail-850665.html
文章来源:https://www.toymoban.com/news/detail-850665.html
四、结果分析与实验体会
通过本次Spark实验,学会了如何安装、启动Hadoop和Spark,并掌握了HDFS的基本使用方法,使用Spark访问本地文件和HDFS文件的方法。在Linux系统的本地文件系统和在HDFS中分别进行各种文件操作,然后在Spark中读取文件系统的数据,并能统计文件的行数。
在做第三题(2)时,在pyspark中读取HDFS系统文件“/user/zhangsan/test.txt”,要将第二题(6)中删除的test.txt文件重新上传到HDFS中,注意文件路径要写正确, file_path=“hdfs:///user/zhc/test.txt”。在第三题(3)中,可以修改如下路径中的文件 /usr/local/spark/conf/log4j.properties.template,将文件中内容 “log4j.rootCategory=INFO” 改为 “log4j.rootCategory=ERROR”,这样在输出结果时,就不会显示大量的INFO信息,使得结果更简化。文章来源地址https://www.toymoban.com/news/detail-850665.html
到了这里,关于Spark编程实验一:Spark和Hadoop的安装使用的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!