目录
一、PageRank算法
二、TextRank算法
1. 关键词抽取(keyword extraction)
2. 关键短语抽取(keyphrase extration)
3. 关键句抽取(sentence extraction)
三、TextRank算法实现
1. 基于Textrank4zh的TextRank算法实现
2. 基于jieba的TextRank算法实现
3. 基于SnowNLP的TextRank算法实现
四、PageRank算法与TextRank算法的区别
TextRank 算法是一种基于谷歌的 PageRank 算法的用于文本的基于图的排序算法,通过把文本分割成若干组成单元(单词、句子)并建立图模型,利用投票机制对文本中的重要成分进行排序,常用于关键词提取和文本摘要。和 LDA、HMM 等模型不同, TextRank 不需要事先对多篇文档进行学习训练, 因其简洁有效而得到广泛应用。
我们知道,关键词是能够表达文档中心内容的词语,常用于计算机系统标引论文内容特征、信息检索、系统汇集以供读者检阅。关键词提取是文本挖掘领域的一个分支,是文本检索、文档比较、摘要生成、文档分类和聚类等文本挖掘研究的基础性工作。
一、PageRank算法
PageRank 算法通过计算网页链接的数量和质量来粗略估计网页的重要性,算法创立之初即应用在谷歌的搜索引擎中,对网页进行排名。 PageRank 算法的核心思想如下:
- 链接数量:如果一个网页被越多的其他网页链接,说明这个网页越重要,即该网页的PR值(PageRank值)会相对较高;
- 链接质量:如果一个网页被一个越高权值的网页链接,也能表明这个网页越重要,即一个PR值很高的网页链接到一个其他网页,那么被链接到的网页的PR值会相应地因此而提高。
我们知道,PageRank (PR) 是一种用于计算网页权重的算法。我们可以把所有的网页看成一个大的有向图。在此图中,节点是网页。如果网页 A 有指向网页 B 的链接,则它可以表示为从 A 到 B 的有向边。构建完整个图后,我们可以通过以下公式为网页分配权重:
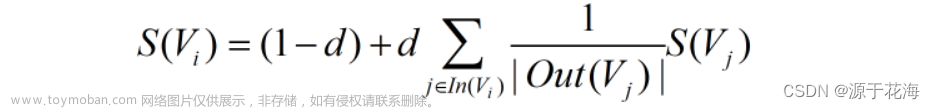
其中,是网页的重要性(PR 值),是阻尼系数,一般为 0.85,是整个互联网中所存在的有指向网页的链接的网页集合,是网页中存在的指向所有外部网页的链接的集合,该集合中元素的个数。

这是一个示例,可以更好地理解上面的符号。我们有一个图表来表示网页如何相互链接。每个节点代表一个网页,箭头代表边。我们想得到网页 的权重。
我们可以将上述函数中的求和部分重写为更简单的版本:

我们可以通过下面的函数得到网页 的权重:

我们可以看到网页 的权重取决于其入站页面的权重。我们需要多次运行此迭代才能获得最终权重。初始化时,每个网页的重要性为 1。
二、TextRank算法
TextRank 算法是一种基于图的用于关键词抽取和文档摘要的排序算法,由谷歌的网页重要性排序算法 PageRank 算法改进而来,它利用一篇文档内部的词语间的共现信息(语义)便可以抽取关键词,它能够从一个给定的文本中抽取出该文本的关键词、关键词组,并使用抽取式的自动文摘方法抽取出该文本的关键句。TextRank 算法的基本思想是将文档看作一个词的网络,该网络中的链接表示词与词之间的语义关系。
TextRank 算法计算公式:

其中, 表示句子 的权重,右侧的求和表示每个相邻句子对本句子的贡前程度在单文档中,我们可以粗略的认为所有句子都是相邻的,无需像多文档一样进行多个窗的生成和抽取,仅需单一文档窗口即可, 表示两个句子的相似度 代表上次选代出的句子 的权重。 是阻尼系数,一般为0.85。
TextRank算法主要包括:关键词抽取、关键短语抽取、关键句抽取。
1. 关键词抽取(keyword extraction)
关键词抽取是指从文本中确定一些能够描述文档含义的术语的过程。对关键词抽取而言,用于构建顶点集的文本单元可以是句子中的一个或多个字;根据这些字之间的关系(比如:在一个框中同时出现)构建边。根据任务的需要,可以使用语法过滤器(syntactic filters)对顶点集进行优化。语法过滤器的主要作用是将某一类或者某几类词性的字过滤出来作为顶点集。
2. 关键短语抽取(keyphrase extration)
关键词抽取结束后,我们可以得到的 N 个关键词,在原始文本中相邻的关键词构成关键短语。因此,从 get_keyphrases 函数的源码中我们可以看到,它先调用 get_keywords 抽取关键词,然后分析关键词是否存在相邻的情况,最后确定哪些是关键短语。
3. 关键句抽取(sentence extraction)
句子抽取任务主要针对的是自动摘要这个场景,将每一个 sentence 作为一个顶点,根据两个句子之间的内容重复程度来计算他们之间的“相似度”,以这个相似度作为联系,由于不同句子之间相似度大小不一致,在这个场景下构建的是以相似度大小作为 edge 权重的有权图。
三、TextRank算法实现
1. 基于Textrank4zh的TextRank算法实现
#!/usr/bin/env python
# -*- coding:utf-8 -*-
"""
@Project : 关键词提取
@File : 基于Textrank4zh的TextRank算法实现.py
@IDE : PyCharm
@Author : 源于花海
@Date : 2023/10/10 21:24
"""
from textrank4zh import TextRank4Keyword
def keywords_extraction(text):
tr4w = TextRank4Keyword()
tr4w.analyze(text, window=2, lower=True)
keywords = tr4w.get_keywords(6, word_min_len=2)
return keywords
if __name__ == "__main__":
text = "自然语言处理是一门涉及计算机科学、人工智能和语言学等多个领域的交叉学科。"
keywords = keywords_extraction(text)
print(keywords)
2. 基于jieba的TextRank算法实现
#!/usr/bin/env python
# -*- coding:utf-8 -*-
"""
@Project : 关键词提取
@File : 基于jieba的TextRank算法实现.py
@IDE : PyCharm
@Author : 源于花海
@Date : 2023/10/10 22:12
"""
import jieba
from jieba.analyse import textrank
# 定义待处理文本
text = "自然语言处理是一门涉及计算机科学、人工智能和语言学等多个领域的交叉学科。"
# 使用jieba库的TextRank算法提取关键词
keywords = textrank(text, topK=3)
print("关键词提取结果:", keywords)关键词提取结果:
分词结果: ['自然', '语言', '处理', '是', '一门', '涉及', '计算机', '科学', '、', '人工智能', '和', '语言学', '等', '多个', '领域', '的', '交叉', '学科', '。']
关键词提取结果: ['计算机科学', '语言学', '人工智能']3. 基于SnowNLP的TextRank算法实现
#!/usr/bin/env python
# -*- coding:utf-8 -*-
"""
@Project : 关键词提取
@File : 基于SnowNLP的TextRank算法实现.py
@IDE : PyCharm
@Author : 源于花海
@Date : 2023/10/10 22:24
"""
from snownlp import SnowNLP
from snownlp import seg
# 定义待处理文本
text = "自然语言处理是一门涉及计算机科学、人工智能和语言学等多个领域的交叉学科。"
# 使用SnowNLP的分词功能对文本进行分词
words = SnowNLP(text).words
# 使用SnowNLP的TextRank算法提取关键词
keywords = SnowNLP(text).keywords(3)
print("分词结果:", words)
print("关键词提取结果:", keywords)输出结果如下:文章来源:https://www.toymoban.com/news/detail-850763.html
分词结果: ['自然', '语言', '处理', '是', '一门', '涉及', '计算机', '科学', '、', '人工智能', '和', '语言学', '等', '多个', '领域', '的', '交叉', '学科', '。']
关键词提取结果: ['语言', '处理', '自然']可以看到,我们成功地使用 SnowNLP 的 TextRank 算法提取出了该文本中的关键词:语言、处理、自然。文章来源地址https://www.toymoban.com/news/detail-850763.html
四、PageRank算法与TextRank算法的区别
- PageRank 算法根据网页之间的链接关系构造网络,TextRank 算法根据词之间的共现关系构造网络;
- PageRank 算法构造的网络中的边是有向无权边,TextRank 算法构造的网络中的边是无向有权边。
到了这里,关于关键词提取 | 基于Textrank算法的两种关键词提取的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!












