前言
网络爬虫,又称网络爬虫、网络蜘蛛、网络机器人等,是一种按照一定的规则自动地获取万维网信息的程序或者脚本。它可以根据一定的策略自动地浏览万维网,并将浏览到的有用信息进行提取、解析和存储。网络爬虫在互联网发展早期就已经出现,并随着互联网的不断发展而得到了广泛的应用。
当谈到网络爬虫时,网络爬虫在各种领域都有着广泛的应用,从搜索引擎的索引建立到数据挖掘和市场分析等方面。本文将深入探讨网络爬虫的工作原理、应用领域、技术挑战以及相关伦理问题,旨在帮助读者更全面地了解这一技术。

网络爬虫的工作原理
网络爬虫的工作原理可以简单描述为以下几个步骤:
-
选择起始网址:爬虫程序需要一个起始点,通常是一个或多个初始网址列表。网络爬虫通常从一个或多个初始网址开始,这些网址可以是用户输入的种子URL,也可以是预定义的列表。
-
下载网页内容:爬虫程序会根据设定的策略下载网页内容,包括 HTML、CSS、JavaScript 和其他相关资源。
-
解析网页:爬虫会解析下载的网页内容,提取其中的链接、文本和其他信息。,并进一步分析网页结构。
-
存储数据:爬虫将提取的数据存储在本地数据库或索引中,以备后续处理和分析。
-
重复步骤:爬虫会根据设定的规则不断重复上述步骤,直到满足停止条件为止。
网络爬虫的应用领域
网络爬虫在各个领域都有着重要的应用,包括但不限于:
-
搜索引擎优化(SEO):搜索引擎利用爬虫程序来抓取网页并建立索引,以提供更准确的搜索结果。
-
数据挖掘:爬虫可以帮助企业收集竞争对手的信息、市场趋势和用户反馈等数据,用于决策和分析。
-
舆情监控:政府和企业可以利用网络爬虫来监控舆情动向,及时了解社会舆论和公众反馈。
-
价格比较:消费者可以利用爬虫来比较不同电商平台的价格和产品信息,以获得最优的购物体验。

网络爬虫的技术挑战
尽管网络爬虫在各领域有着广泛应用,但也面临着一些技术挑战,例如:
-
反爬虫技术:网站所有者为了保护数据和资源,会采取反爬虫技术,如验证码、IP封锁等手段,阻止爬虫程序的访问。
-
数据去重与更新:爬虫需要考虑如何去重重复数据,并及时更新页面内容,以确保获取的信息是最新和准确的。
-
大规模数据处理:当爬取的网页数量庞大时,如何高效地处理和存储海量数据是一个挑战。

网络爬虫的伦理问题
随着网络爬虫技术的发展,也引发了一些伦理问题,包括但不限于:
-
隐私问题:爬虫可能会收集用户个人信息而未经允许,存在侵犯隐私的风险。
-
侵权问题:爬虫在抓取网页内容时,可能侵犯版权和知识产权,需要遵守相关法律法规。
-
网络流量:过度的爬虫活动可能导致网络流量过大,影响网站正常运行。

结语
然而,网络爬虫的应用也面临着一些技术挑战和伦理问题。首先,网站所有者为了保护其数据和资源,常常采取反爬虫技术,如验证码、IP封锁等,增加了爬虫的访问难度。其次,大规模数据处理和存储也是网络爬虫所面临的挑战之一,需要考虑数据清洗、去重和分布式存储等技术手段。此外,网络爬虫在抓取数据过程中,可能会涉及个人隐私信息的收集,版权和知识产权的侵犯,以及对网络资源消耗的影响,因此需要严格遵守相关法律法规,尊重用户权益,确保合法合规的数据获取和使用。
为了推动网络爬虫的良性发展,我们需要加强对网络爬虫技术的研究和应用,提高其抓取效率和数据处理能力,同时加强对其合理使用和监管。在实际应用中,用户和开发者应该遵守网络道德和法律规定,尊重他人的隐私和知识产权,防止滥用网络爬虫带来的负面影响。同时,政府和监管部门也应建立健全的监管机制,加强对网络爬虫活动的监督和管理,促进网络爬虫在信息获取和利用方面发挥积极作用,为互联网信息的整合和共享提供支持。
总之,网络爬虫作为一种重要的数据抓取工具,在当前信息化社会中发挥着越来越重要的作用。通过合理应用和科学管理,网络爬虫将为各行各业带来更多的机遇和挑战,助力于信息的传播、共享和创新。
爬虫在信息检索、数据分析和商业决策等领域发挥着重要作用。然而,使用网络爬虫也需要遵守法律法规和伦理标准,保护用户隐私和网络资源。随着技术的不断进步,我们相信网络爬虫将继续发挥其重要作用,并带来更多的创新和发展。同时,我们也需要共同努力,保护网络环境的健康发展,维护用户和数据的合法权益,促进网络爬虫技术的可持续发展和进步。文章来源:https://www.toymoban.com/news/detail-851032.html
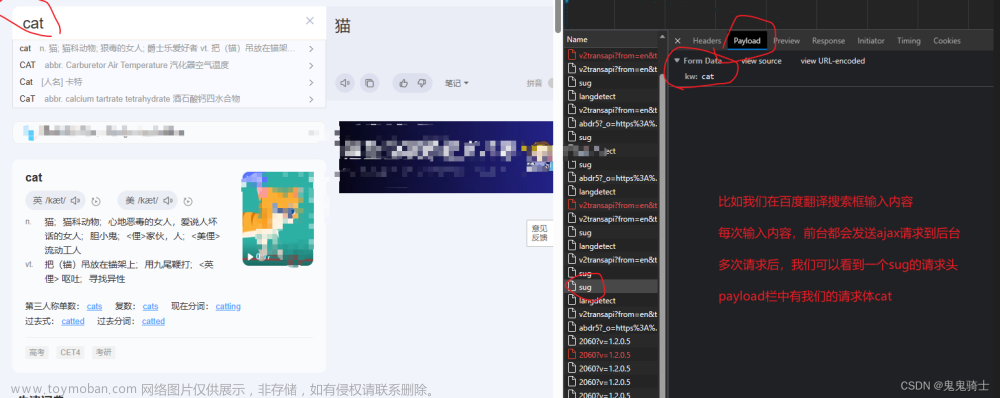
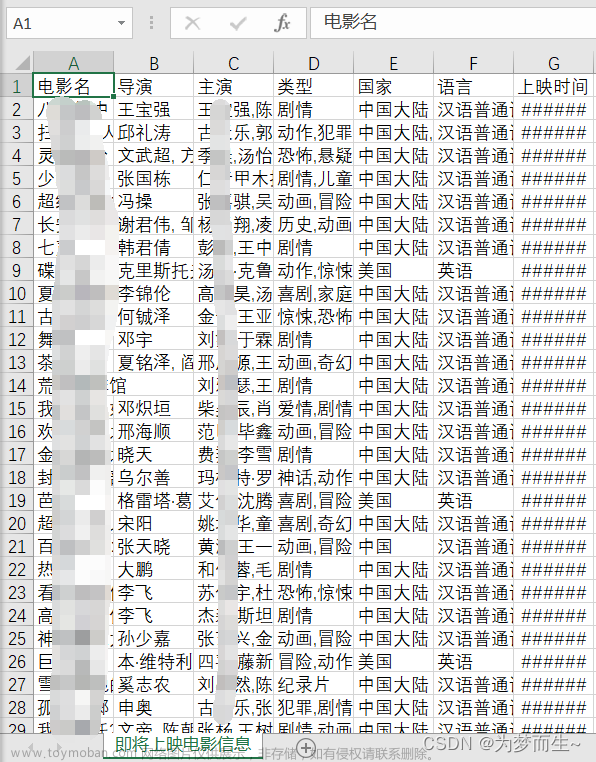
福利
 文章来源地址https://www.toymoban.com/news/detail-851032.html
文章来源地址https://www.toymoban.com/news/detail-851032.html
到了这里,关于【Python爬虫】网络爬虫:信息获取与合规应用的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!