如何去定位页面上动态加载动态变化的元素?
正文
xpath实用的元素定位方法
CSS实用的元素定位方法
总结
css 和 xpath 定位各自优缺点?
====================
xpath :是 XML 文档中查找结点的语法,换句话就是通过元素的路径来查找这个元素。他分绝对路径和相对路径,xpath 比较强大,所有元素它都能定位到,但是他定位相对比较慢,
css 选择器 :在性能上更优,运行速度更快,语法上更简洁。
Xpath能通过子元素搜索父元素, Css无法实现,Css只能从父级往下级搜索。
Xpath能按文本搜索元素,Css不能。
Css比Xpath更简单易读,执行速度更快
篇外话
===
如何定位一组元素?
以百度为例:
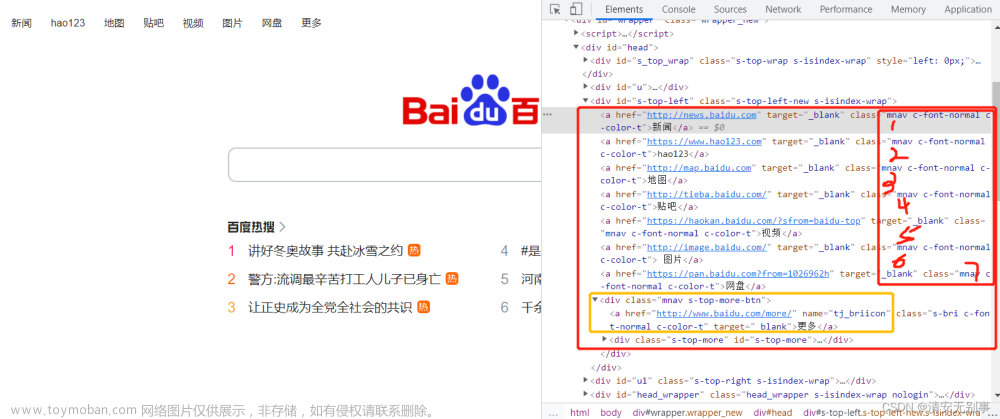
from selenium import webdriver
fox = webdriver.Firefox()
fox.get(‘https://baidu.com’)
s = fox.find_elements_by_class_name(‘mnav’)
for i in s:
print(i.get_attribute(‘href’))
fox.quit()
看图,我标注了数字,为什么要标注数字,跑了看结果就知道了。
http://news.baidu.com/
https://www.hao123.com/
http://map.baidu.com/
http://tieba.baidu.com/
https://haokan.baidu.com/?sfrom=baidu-top
http://image.baidu.com/
https://pan.baidu.com/?from=1026962h
None
得出的结果是这样的。为什么会有一个None值呢,看到了我标注的黄色框了吗,元素也是mnav开头的,这里是模糊匹配,所以黄色框中的div也输出了,它又没有href,所以为None。
.get_attribute(‘href’)获取元素的给定属性或属性,它将返回具有相同名称的属性的值,我需要获取href属性对应的值,所以说,输出了一个个链接。
如何定位父子/兄弟/相邻节点的定位元素?
这里做了解就好
父->子

串联查找,这一项可以理解为父级元素的基础上直接查找所需的子元素。当元素定位不到的时候可以尝试此方法,不过比较的笨拙,但是实在。
from selenium import webdriver
fox = webdriver.Firefox()
fox.get(‘http://39.98.138.157/shopxo/public/index.php?s=/index/user/logininfo.html’)
ele = fox.find_element_by_class_name(‘am-u-sm-12.am-u-md-6.am-u-lg-4.container-right’).find_element_by_link_text(‘忘记密码?’).text
print(ele)
fox.quit()
子->父

find_element_by_xpath(‘//div[@id=’u’]/…/…’)
这里就是子元素先定位到父元素再定位到父元素的父元素
如何二次定位元素?
这里的二次定位其实就是串联查找,所以,这里看上面的父级>子元素的查找即可
如何去定位页面上动态加载动态变化的元素?
这里介绍三种方法,解决你对定位的困扰。
contains(a, b) 如果 a 中含有字符串 b,则返回 true,否则返回 false(包含什么)
starts-with(a, b) 如果 a 是以字符串 b 开头,返回 true,否则返回 false(以什么开始)
ends-with(a, b) 如果 a 是以字符串 b 结尾,返回 true,否则返回 false(以什么结束)
driver.find_element_by_xpath (“//div[contains(@id, ‘accounts’)]”)

感谢每一个认真阅读我文章的人,看着粉丝一路的上涨和关注,礼尚往来总是要有的:
① 2000多本Python电子书(主流和经典的书籍应该都有了)
② Python标准库资料(最全中文版)
③ 项目源码(四五十个有趣且经典的练手项目及源码)
④ Python基础入门、爬虫、web开发、大数据分析方面的视频(适合小白学习)
⑤ Python学习路线图(告别不入流的学习)
小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数初中级Python工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Python爬虫全套学习资料》送给大家,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频文章来源:https://www.toymoban.com/news/detail-851166.html
如果你觉得这些内容对你有帮助,可以添加下面V无偿领取!(备注:python)
技术停滞不前!**
因此收集整理了一份《2024年Python爬虫全套学习资料》送给大家,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频
如果你觉得这些内容对你有帮助,可以添加下面V无偿领取!(备注:python)
[外链图片转存中…(img-NwWlL3vU-1711202723979)]文章来源地址https://www.toymoban.com/news/detail-851166.html
到了这里,关于selenium-XPATH以及CSS的便捷使用,源码解析的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!








