实验2 熟悉常用的HDFS操作
目录
实验2 熟悉常用的HDFS操作
一、实验目的
二、实验平台
三、实验步骤(每个步骤下均需有运行截图)
(一)编程实现以下功能,并利用Hadoop提供的Shell命令完成相同任务:
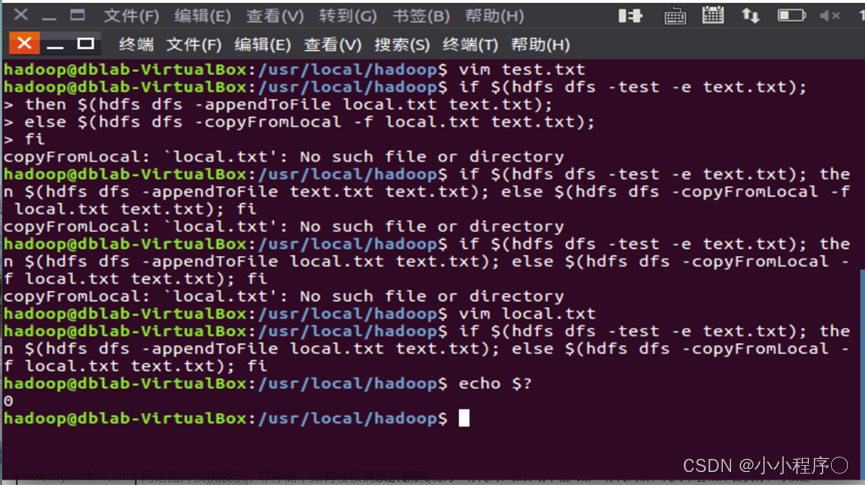
(1)向HDFS中上传任意文本文件,如果指定的文件在HDFS中已经存在,则由用户来指定是追加到原有文件末尾还是覆盖原有的文件;
(2)从HDFS中下载指定文件,如果本地文件与要下载的文件名称相同,则自动对下载的文件重命名;
(3)将HDFS中指定文件的内容输出到终端中;
(4)显示HDFS中指定的文件的读写权限、大小、创建时间、路径等信息;
(5)给定HDFS中某一个目录,输出该目录下的所有文件的读写权限、大小、创建时间、路径等信息,如果该文件是目录,则递归输出该目录下所有文件相关信息;
(6)提供一个HDFS内的文件的路径,对该文件进行创建和删除操作。如果文件所在目录不存在,则自动创建目录;
(7)提供一个HDFS的目录的路径,对该目录进行创建和删除操作。创建目录时,如果目录文件所在目录不存在,则自动创建相应目录;删除目录时,由用户指定当该目录不为空时是否还删除该目录;
(8)向HDFS中指定的文件追加内容,由用户指定内容追加到原有文件的开头或结尾;
(9)删除HDFS中指定的文件;
(10)在HDFS中,将文件从源路径移动到目的路径。
(二)编程实现一个类“MyFSDataInputStream”,该类继承“org.apache.hadoop.fs.FSDataInputStream”,要求如下:实现按行读取HDFS中指定文件的方法“readLine()”,如果读到文件末尾,则返回空,否则返回文件一行的文本。
(三)查看Java帮助手册或其它资料,用“java.net.URL”和“org.apache.hadoop.fs.FsURLStreamHandlerFactory”编程完成输出HDFS中指定文件的文本到终端中。
四、实验总结
一、实验目的
1. 理解HDFS在Hadoop体系结构中的角色;
2. 熟练使用HDFS操作常用的Shell命令;
3. 熟悉HDFS操作常用的Java API。
二、实验平台
1. 操作系统:Linux(建议Ubuntu16.04或Ubuntu18.04);
2. Hadoop版本:3.1.3;
3. JDK版本:1.8;
4. Java IDE:Eclipse。
三、实验步骤(每个步骤下均需有运行截图)
(一)编程实现以下功能,并利用Hadoop提供的Shell命令完成相同任务:
(1)向HDFS中上传任意文本文件,如果指定的文件在HDFS中已经存在,则由用户来指定是追加到原有文件末尾还是覆盖原有的文件;


(2)从HDFS中下载指定文件,如果本地文件与要下载的文件名称相同,则自动对下载的文件重命名;


(3)将HDFS中指定文件的内容输出到终端中;


(4)显示HDFS中指定的文件的读写权限、大小、创建时间、路径等信息;


(5)给定HDFS中某一个目录,输出该目录下的所有文件的读写权限、大小、创建时间、路径等信息,如果该文件是目录,则递归输出该目录下所有文件相关信息;




(6)提供一个HDFS内的文件的路径,对该文件进行创建和删除操作。如果文件所在目录不存在,则自动创建目录;



(7)提供一个HDFS的目录的路径,对该目录进行创建和删除操作。创建目录时,如果目录文件所在目录不存在,则自动创建相应目录;删除目录时,由用户指定当该目录不为空时是否还删除该目录;



(8)向HDFS中指定的文件追加内容,由用户指定内容追加到原有文件的开头或结尾;




(9)删除HDFS中指定的文件;


(10)在HDFS中,将文件从源路径移动到目的路径。


(二)编程实现一个类“MyFSDataInputStream”,该类继承“org.apache.hadoop.fs.FSDataInputStream”,要求如下:实现按行读取HDFS中指定文件的方法“readLine()”,如果读到文件末尾,则返回空,否则返回文件一行的文本。

(三)查看Java帮助手册或其它资料,用“java.net.URL”和“org.apache.hadoop.fs.FsURLStreamHandlerFactory”编程完成输出HDFS中指定文件的文本到终端中。


四、实验总结
在本次实验中,我进一步理解了HDFS在Hadoop体系结构中的角色并能使用HDFS操作常用的Shell命令以及HDFS操作常用的Java API。
在本次实验的第一题我采用了Hadoop提供的Shell命令以及Java API来解答。学习了当向HDFS中上传任意文本文件,如果指定的文件在HDFS中已经存在,由用户指定是追加到原有文件末尾还是覆盖原有的文件。能够从 HDFS 中下载指定文件,懂得了若是本地文件与要下载的文件名称相同,自动对下载的文件重命名等等内容。
在二三题中,主要是通过虚拟机的IDEA采用HDFS操作常用的Java API来运行解答。在第二三题被困住了很久,深刻感觉到对HDFS操作常用的Java API还不够熟练,还需要加强学习。
五、优化及改进(选做)文章来源:https://www.toymoban.com/news/detail-851220.html
【提出你觉得解决这个问题更好的算法,并加以说明】文章来源地址https://www.toymoban.com/news/detail-851220.html
到了这里,关于大数据技术原理及应用课实验2 :熟悉常用的HDFS操作的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!