伪元素的定义:
不是真正的页面元素,html没有对应的元素,但是其所有用法和表现行为与真正的页面元素一样,可以对其使用诸如页面元素一样的css样式,表面上看上去貌似是页面的某些元素来展现,实际上是css样式展现的行为,因此被称为伪元素。
前端有些页面,可能会见到::before、::after元素
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>::before 和 ::after 示例</title>
<style>
.container {
position: relative;
}
.container::before {
content: "前置文本 ";
font-weight: bold;
color: blue;
}
.container::after {
content: " 后置文本";
font-weight: bold;
color: red;
}
/* 可以根据需要添加其他样式 */
</style>
</head>
<body>
<div class="container">
这是一个带有伪元素的示例。
</div>
</body>
</html>
像上面的页面,打开之后显示的是这样的

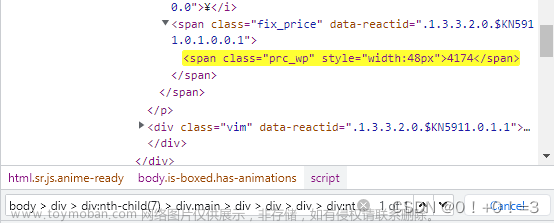
使用8种定位元素方式,是无法定位并获取到“前置文本”、“后置文本”的值的

可以看到,页面元素只展示了::before、::after 伪元素,并没有显示文本值
文本值是放在CSS样式中的,通过content属性进行设置
我们可以通过JavaScript可以进行提取content的值
若是想获取其他属性的值,将content改为其他属性即可
window.getComputedStyle(document.querySelector('CSS表达式'),':before').getPropertyValue('content')window.getComputedStyle(document.querySelector('CSS表达式'),':after').getPropertyValue('content')代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
chrome_option = Options()
chrome_option.add_experimental_option("debuggerAddress", "127.0.0.1:9222")
chrome_service = Service()
chrome_service.executable_path = r'../chromedriver.exe'
driver = webdriver.Chrome(options=chrome_option, service=chrome_service)
# 需要加上return,否则无法获取元素文本
js_before = "return window.getComputedStyle(document.querySelector('.container'),':before').getPropertyValue('content')"
js_after = "return window.getComputedStyle(document.querySelector('.container'),':after').getPropertyValue('content')"
print(driver.execute_script(js_before))
print(driver.execute_script(js_after))结果截图:文章来源:https://www.toymoban.com/news/detail-851260.html
 文章来源地址https://www.toymoban.com/news/detail-851260.html
文章来源地址https://www.toymoban.com/news/detail-851260.html
到了这里,关于Selenium 定位伪元素,获取伪元素中的文本的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!