爬虫基本原理介绍、实现以及问题解决
一、爬虫的意义
1. 前言
爬虫作为网络数据采集的重要工具,在当今互联网时代具有不可替代的作用。通过爬虫,我们可以获取到丰富的网络数据,用于各种用途,包括数据分析、业务决策、舆情监测等。
2. 爬虫能做什么
爬虫可以用于获取互联网上的各种数据,无论是文字、图片、视频还是音频等,只要是网络上公开可访问的内容,都可以通过爬虫来获取。
3. 爬虫有什么意义
爬虫不仅可以帮助企业进行市场调研和竞品分析,还可以用于舆情监测、新闻资讯、商品价格跟踪等方面。对于数据分析人员来说,爬虫更是获取数据的重要途径,为后续的数据分析工作提供了丰富的数据源。
二、爬虫的实现
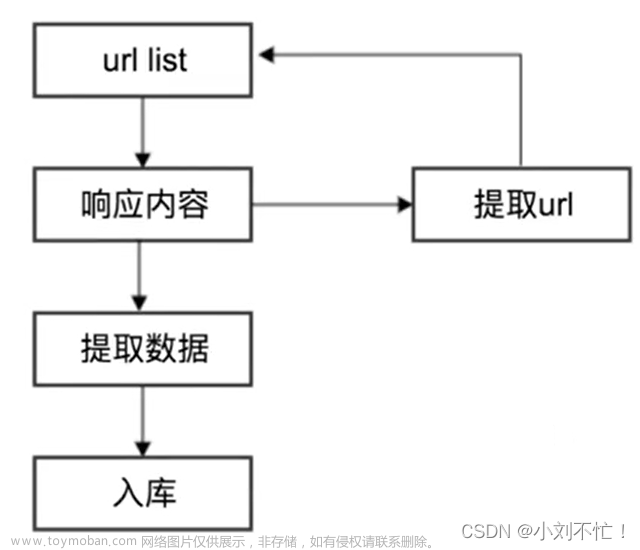
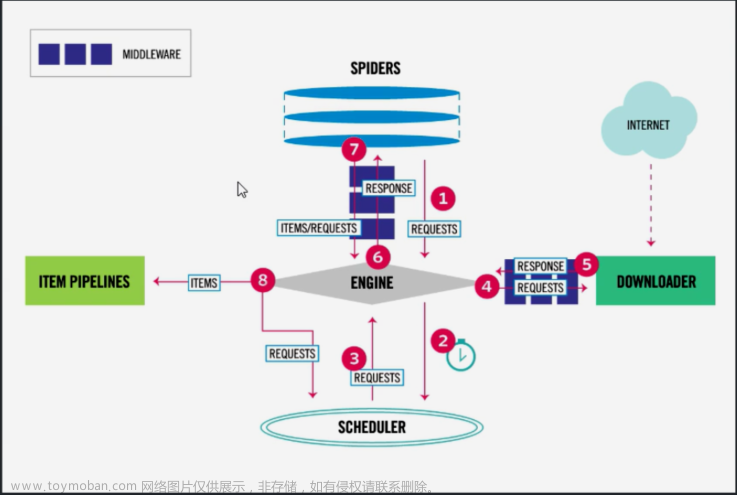
1. 爬虫的基础原理
爬虫的基本原理是模拟浏览器发送HTTP请求,获取网页内容,并解析提取所需信息。其中,HTTP请求可以通过Python中的Requests库来实现,而网页内容的解析则可以使用Beautiful Soup等库来实现。
2. API的获取
除了直接爬取网页内容外,有些网站还提供了API接口,可以直接调用获取数据。相比于直接爬取网页内容,通过API获取数据更加规范和稳定。
3. 爬虫实现
Python中有很多爬虫框架可以使用,例如Scrapy、Beautiful Soup等,也可以直接使用Requests库进行简单的爬取。下面是一个使用Requests库获取网页内容的示例代码:
import requests
url = 'https://example.com'
response = requests.get(url)
html = response.text
print(html)
三、反爬解决方案
1. 反爬的实现方式
为了防止被爬取,网站可能会采取一些反爬手段,例如设置验证码、IP限制、User-Agent检测等。
2. 反爬的解决方法
针对不同的反爬手段,可以采取相应的解决方法,例如使用代理IP、设置随机User-Agent、使用Cookies池等。
3. 反爬的实现代码
下面是一个简单的使用代理IP进行反爬的示例代码:
import requests
def get_html(url):
proxies = {
'http': 'http://127.0.0.1:1080',
'https': 'https://127.0.0.1:1080'
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
response = requests.get(url, headers=headers, proxies=proxies)
return response.text
html = get_html('https://example.com')
print(html)
4. IP代理还能做什么
除了用于反爬之外,IP代理还可以用于隐藏真实IP地址、提高访问速度、突破网络限制等。
总结
通过本文的介绍,我们了解了爬虫的基本原理、实现方法以及解决反爬问题的方案。爬虫在当今互联网时代具有重要意义,希望本文能对您有所帮助。文章来源:https://www.toymoban.com/news/detail-851368.html
感谢您阅读本篇博客!如果有任何文章来源地址https://www.toymoban.com/news/detail-851368.html
到了这里,关于爬虫基本原理介绍、实现以及问题解决的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!