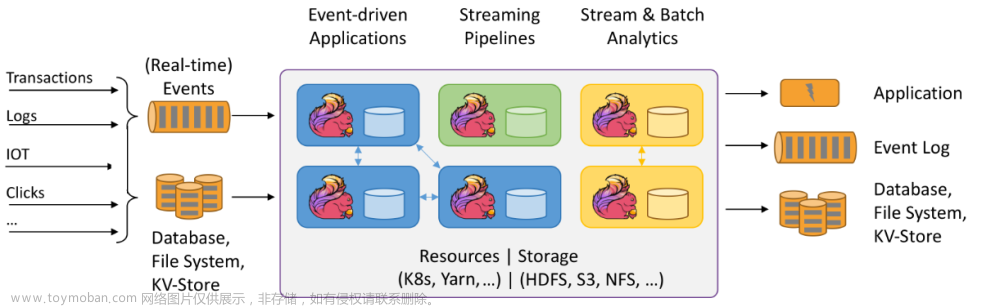
使用Flink实现Kafka到MySQL的数据流转换
在现代数据处理架构中,Kafka和MySQL是两种非常流行的技术。Kafka作为一个高吞吐量的分布式消息系统,常用于构建实时数据流管道。而MySQL则是广泛使用的关系型数据库,适用于存储和查询数据。在某些场景下,我们需要将Kafka中的数据实时地写入到MySQL数据库中,本文将介绍如何使用Apache Flink来实现这一过程。

环境准备
在开始之前,请确保你的开发环境中已经安装并配置了以下组件:
Apache Flink 准备相关pom依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>EastMoney</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId>
<version>1.14.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-scala-bridge_2.11</artifactId>
<version>1.14.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.11</artifactId>
<version>1.14.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-scala_2.11</artifactId>
<version>1.14.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_2.11</artifactId>
<version>1.14.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-csv</artifactId>
<version>1.14.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>1.14.0</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.25</version>
</dependency>
</dependencies>
</project>
Kafka消息队列
1. 启动zookeeper
zkServer start
2. 启动kafka服务
kafka-server-start /opt/homebrew/etc/kafka/server.properties
3. 创建topic
kafka-topics --create --bootstrap-server 127.0.0.1:9092 --replication-factor 1 --partitions 1 --topic east_money
6. 生产数据
kafka-console-producer --broker-list localhost:9092 --topic east_money
MySQL数据库
初始化mysql表
CREATE TABLE `t_stock_code_price` (
`id` bigint NOT NULL AUTO_INCREMENT,
`code` varchar(64) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT '股票代码',
`name` varchar(64) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT '股票名称',
`close` double DEFAULT NULL COMMENT '最新价',
`change_percent` double DEFAULT NULL COMMENT '涨跌幅',
`change` double DEFAULT NULL COMMENT '涨跌额',
`volume` double DEFAULT NULL COMMENT '成交量(手)',
`amount` double DEFAULT NULL COMMENT '成交额',
`amplitude` double DEFAULT NULL COMMENT '振幅',
`turnover_rate` double DEFAULT NULL COMMENT '换手率',
`peration` double DEFAULT NULL COMMENT '市盈率',
`volume_rate` double DEFAULT NULL COMMENT '量比',
`hign` double DEFAULT NULL COMMENT '最高',
`low` double DEFAULT NULL COMMENT '最低',
`open` double DEFAULT NULL COMMENT '今开',
`previous_close` double DEFAULT NULL COMMENT '昨收',
`pb` double DEFAULT NULL COMMENT '市净率',
`create_time` varchar(64) NOT NULL COMMENT '写入时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=5605 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
步骤解释
获取流执行环境:首先,我们通过StreamExecutionEnvironment.getExecutionEnvironment获取Flink的流执行环境,并设置其运行模式为流处理模式。
创建流表环境:接着,我们通过StreamTableEnvironment.create创建一个流表环境,这个环境允许我们使用SQL语句来操作数据流。
val senv = StreamExecutionEnvironment.getExecutionEnvironment
.setRuntimeMode(RuntimeExecutionMode.STREAMING)
val tEnv = StreamTableEnvironment.create(senv)
定义Kafka数据源表:我们使用一个SQL语句创建了一个Kafka表re_stock_code_price_kafka,这个表代表了我们要从Kafka读取的数据结构和连接信息。
tEnv.executeSql(
"CREATE TABLE re_stock_code_price_kafka (" +
"`id` BIGINT," +
"`code` STRING," +
"`name` STRING," +
"`close` DOUBLE NULL," +
"`change_percent` DOUBLE," +
"`change` DOUBLE," +
"`volume` DOUBLE," +
"`amount` DOUBLE," +
"`amplitude` DOUBLE," +
"`turnover_rate` DOUBLE," +
"`operation` DOUBLE," +
"`volume_rate` DOUBLE," +
"`high` DOUBLE ," +
"`low` DOUBLE," +
"`open` DOUBLE," +
"`previous_close` DOUBLE," +
"`pb` DOUBLE," +
"`create_time` STRING," +
"rise int"+
") WITH (" +
"'connector' = 'kafka'," +
"'topic' = 'east_money'," +
"'properties.bootstrap.servers' = '127.0.0.1:9092'," +
"'properties.group.id' = 'mysql2kafka'," +
"'scan.startup.mode' = 'earliest-offset'," +
"'format' = 'csv'," +
"'csv.field-delimiter' = ','" +
")"
)
val result = tEnv.executeSql("select * from re_stock_code_price_kafka")
定义MySQL目标表:然后,我们定义了一个MySQL表re_stock_code_price,指定了与MySQL的连接参数和表结构。
val sink_table: String =
"""
|CREATE TEMPORARY TABLE re_stock_code_price (
| id BIGINT NOT NULL,
| code STRING NOT NULL,
| name STRING NOT NULL,
| `close` DOUBLE,
| change_percent DOUBLE,
| change DOUBLE,
| volume DOUBLE,
| amount DOUBLE,
| amplitude DOUBLE,
| turnover_rate DOUBLE,
| peration DOUBLE,
| volume_rate DOUBLE,
| hign DOUBLE,
| low DOUBLE,
| `open` DOUBLE,
| previous_close DOUBLE,
| pb DOUBLE,
| create_time STRING NOT NULL,
| rise int,
| PRIMARY KEY (id) NOT ENFORCED
|) WITH (
| 'connector' = 'jdbc',
| 'url' = 'jdbc:mysql://localhost:3306/mydb',
| 'driver' = 'com.mysql.cj.jdbc.Driver',
| 'table-name' = 're_stock_code_price',
| 'username' = 'root',
| 'password' = '12345678'
|)
|""".stripMargin
tEnv.executeSql(sink_table)
数据转换和写入:最后,我们执行了一个插入操作,将从Kafka读取的数据转换并写入到MySQL中。文章来源:https://www.toymoban.com/news/detail-851655.html
tEnv.executeSql("insert into re_stock_code_price select * from re_stock_code_price_kafka")
result.print()
全部代码
package org.east
import org.apache.flink.api.common.RuntimeExecutionMode
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.table.api.bridge.scala.StreamTableEnvironment
object Kafka2Mysql {
def main(args: Array[String]): Unit = {
val senv = StreamExecutionEnvironment.getExecutionEnvironment
.setRuntimeMode(RuntimeExecutionMode.STREAMING)
val tEnv = StreamTableEnvironment.create(senv)
tEnv.executeSql(
"CREATE TABLE re_stock_code_price_kafka (" +
"`id` BIGINT," +
"`code` STRING," +
"`name` STRING," +
"`close` DOUBLE NULL," +
"`change_percent` DOUBLE," +
"`change` DOUBLE," +
"`volume` DOUBLE," +
"`amount` DOUBLE," +
"`amplitude` DOUBLE," +
"`turnover_rate` DOUBLE," +
"`operation` DOUBLE," +
"`volume_rate` DOUBLE," +
"`high` DOUBLE ," +
"`low` DOUBLE," +
"`open` DOUBLE," +
"`previous_close` DOUBLE," +
"`pb` DOUBLE," +
"`create_time` STRING," +
"rise int"+
") WITH (" +
"'connector' = 'kafka'," +
"'topic' = 'east_money'," +
"'properties.bootstrap.servers' = '127.0.0.1:9092'," +
"'properties.group.id' = 'mysql2kafka'," +
"'scan.startup.mode' = 'earliest-offset'," +
"'format' = 'csv'," +
"'csv.field-delimiter' = ','" +
")"
)
val result = tEnv.executeSql("select * from re_stock_code_price_kafka")
val sink_table: String =
"""
|CREATE TEMPORARY TABLE re_stock_code_price (
| id BIGINT NOT NULL,
| code STRING NOT NULL,
| name STRING NOT NULL,
| `close` DOUBLE,
| change_percent DOUBLE,
| change DOUBLE,
| volume DOUBLE,
| amount DOUBLE,
| amplitude DOUBLE,
| turnover_rate DOUBLE,
| peration DOUBLE,
| volume_rate DOUBLE,
| hign DOUBLE,
| low DOUBLE,
| `open` DOUBLE,
| previous_close DOUBLE,
| pb DOUBLE,
| create_time STRING NOT NULL,
| rise int,
| PRIMARY KEY (id) NOT ENFORCED
|) WITH (
| 'connector' = 'jdbc',
| 'url' = 'jdbc:mysql://localhost:3306/mydb',
| 'driver' = 'com.mysql.cj.jdbc.Driver',
| 'table-name' = 're_stock_code_price',
| 'username' = 'root',
| 'password' = '12345678'
|)
|""".stripMargin
tEnv.executeSql(sink_table)
tEnv.executeSql("insert into re_stock_code_price select * from re_stock_code_price_kafka")
result.print()
print("数据打印完成!!!")
}
}
如有遇到问题可以找小编沟通交流哦。另外小编帮忙辅导大课作业,学生毕设等。不限于python,java,大数据,模型训练等。 文章来源地址https://www.toymoban.com/news/detail-851655.html
文章来源地址https://www.toymoban.com/news/detail-851655.html
到了这里,关于使用Flink实现Kafka到MySQL的数据流转换:一个基于Flink的实践指南的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!