目录
设计模式七大原则:
开闭原则:
单一职责原则:
里氏替换原则:
依赖倒转原则:
接口隔离原则:
迪米特原则(最少知道原则):
合成复用原则:
三大模式及其特点:
创建型模式:
结构型模式:
行为模式:
--------------------我是一个分界线,接下来是创造型模式-----------------------
解释器模式:
优点:
缺点:
适用场景:
实现代码:
建造者模式:
缺点:
优点:
与工厂模式相比:
适用场景:
实现代码:
简单工厂模式:
优点:
缺点:
工厂方法:
实现代码:
原型模式:
优点:
缺点:
适用场景:
实现代码:
单例模式:
优点:
缺点:
步骤:
细节:
实现代码:
--------------------我是一个分界线,接下来是结构型模式-----------------------
适配器模式:
优点:
缺点:
适用场景:
注意事项:
实现代码:
桥接模式:
优点:
缺点:
适用场景:
实现代码:
组合实体模式:
优点:
缺点:
适用场景:
实现代码:
装饰器模式:
优点:
缺点:
适用场景:
实现代码:
外观模式(门面模式):
优点:
缺点:
适用场景:
实现代码:
享元模式:
优点:
缺点:
适用场景:
实现代码:
代理模式:
优点:
缺点:
适用场景:
实现代码:
---------------------我是一个分界线,接下来是行为模式------------------------
责任链模式:
优点:
缺点:
适用场景:
实现代码:
命令模式:
优点:
缺点:
适用场景:
实现代码:
解释器模式:
优点:
缺点:
适用场景:
实现代码:
迭代器模式:
优点:
缺点:
适用场景:
实现代码:
中介者模式:
优点:
缺点:
适用场景:
代码实现:
备忘录模式:
优点:
缺点:
适用场景:
实现代码:
观察者模式:
优点:
缺点:
适用场景:
代码实现:
状态模式:
优点:
缺点:
适用场景:
代码实现:
策略模式:
优点:
缺点:
适用场景:
注意事项:
代码实现:
模板模式:
优点:
缺点:
适用场景:
代码实现:
访问者模式:
优点:
缺点:
适用场景:
代码实现:
参考:
设计模式七大原则:
开闭原则:
对扩展开放,对修改关闭。在程序需要进行拓展的时候不能去修改原有的代码,而是拓展原有代码,实现热插拔的效果。
单一职责原则:
不要存在多于一个导致类变更的原因,也就是说每个类应该实现单一的职责,如若不然,就应该把类拆分。
里氏替换原则:
是面向对象设计的基本原则之一。任何基类可以出现的地方,子类一定可以出现。它是继承复用的基石,只有当衍生类可以替换掉基类,软件单位功能不受到影响的时候,基类才能真正被复用,而衍生类也能够在积累的基础上增加新的行为。是对“开闭原则”的补充。实现开闭原则的关键步骤就是抽象化,而基类与子类的继承关系就是抽象化的具体实现,所以里氏替换原则是对实现抽象化的具体步骤的规范。
依赖倒转原则:
这个是开闭原则的基础,具体内容:面向接口编程,依赖于抽象而不依赖于具体。写代码时用到具体类时,不与具体类交互,而是与具体类的上层接口交互。
接口隔离原则:
每个接口中不存在子类用不到却必须实现的方法,如果不然,就要将接口拆分。使用多个隔离的接口,比使用单个接口要好。
迪米特原则(最少知道原则):
一个类对自己依赖的类知道的越少越好。无论被依赖的类多复杂,都应该将逻辑封装在方法的内部,通过public方法提供给外部。这样当被依赖的类变化时,才能最小影响该类。
合成复用原则:
尽量使用合成/聚合的方式,而不是使用继承。
三大模式及其特点:
创建型模式:
抽象了实例化过程。它们帮助一个系统独立于如何创建、组合和表示它的那些对象。
(抽象工厂模式,建造者模式,工厂模式,原型模式,单例模式)
结构型模式:
涉及到如何组合类和对象以获得更大的结构。创建型模式关注一个类或对象的实例化;结构型模式关注多个类或对象组合成更复杂的对象,是为了更灵活的构造对象。
(适配器模式,桥接模式,组合实体模式,装饰器模式,外观模式,享元模式,代理模式)
行为模式:
涉及到算法和对象间职责的分配。不仅描述对象和类的模式,还描述它们之间的通信模式。使用继承机制在类间分派行为。
(责任链模式,命令模式,解释器模式,迭代器模式,中介者模式,备忘录模式,观察者模式,状态模式,策略模式,模板模式,访问者模式)
--------------------我是一个分界线,接下来是创造型模式-----------------------
解释器模式:
是指给定一个语言(表达式),定义它的文法的一种表示,并定义一个解释器,使用该解释器来解释语言中的句子(表达式)
优点:
1.具有良好的扩展性。语法的翻译通过类来实现,扩展类可以扩展其解释能力
2.实现难度低,语法树中每个表达式节点类具备一定相似性,实现起来相对容易
缺点:
1.执行效率低。解释器中通常有大量循环和递归语句,当被解释句子较复杂的时候,程序的性能受到较大影响
2.类膨胀问题。规则较多时,类数量也膨胀
适用场景:
当某个特定类型问题发生频率足够高的时候,例如,简单语法解释,编译器,运算表达式计算,正则表达式,日志处理:使用脚本语言或者编程语言处理日志时,
会产生大量报表,需要对日志进行解析,生成报表
各个服务的日志格式不同,数据中的要素相同,这种情况下,通过程序解决上述问题,主要解决方案就是使用解释器模式,日常项目中使用解释器模式很少
与适配器模式对比:两个模式类似,但是适配器模式不需要预先知道适配器的规则。解释器模式需要预先将规则写好,根据规则执行解释。
实现代码:
#include<iostream>
#include<list>
#include<vector>
#include<algorithm>
class Context{
public:
Context(int num){
m_num=num;
}
void setNum(int num){
m_num=num;
}
int getNum(){
return m_num;
}
void setRes(int res){
m_res=res;
}
int getRes(){
return m_res;
}
private:
int m_num,m_res;
};
class Expression{
public:
virtual void interpreter(Context* context) =0;
};
class PlusExpression :public Expression{
public:
virtual void interpreter(Context* context){
int num=context->getNum();
num++;
context->setNum(num);
context->setRes(num);
}
};
class MinusExpression :public Expression{
public:
virtual void interpreter(Context* context){
int num =context->getNum();
num--;
context->setNum(num);
context->setRes(num);
}
};
int
main(){
Context* pcxt =new Context(10);
Expression* e1=new PlusExpression();
e1->interpreter(pcxt);
std::cout<<"PlusExpression:"<<pcxt->getRes()<<std::endl;
Expression* e2 =new MinusExpression();
e2->interpreter(pcxt);
std::cout<<"MinusExpression:"<<pcxt->getRes()<<std::endl;
delete e1,e2,pcxt;
return 0;
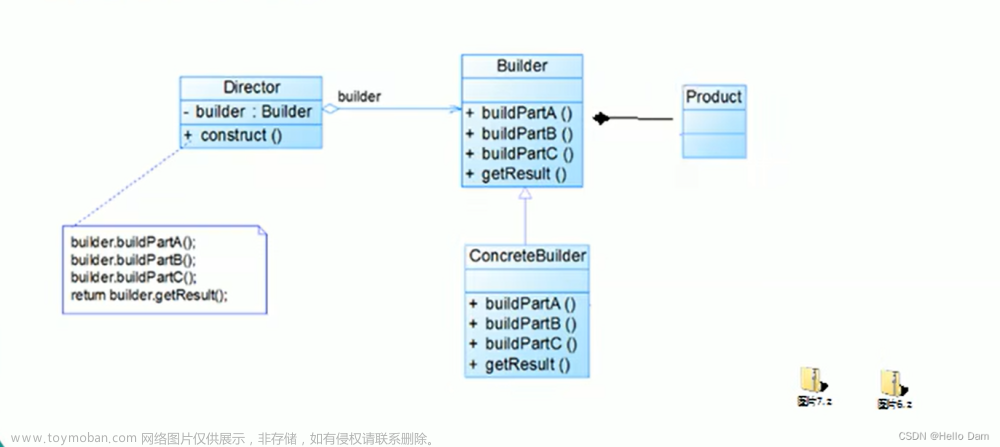
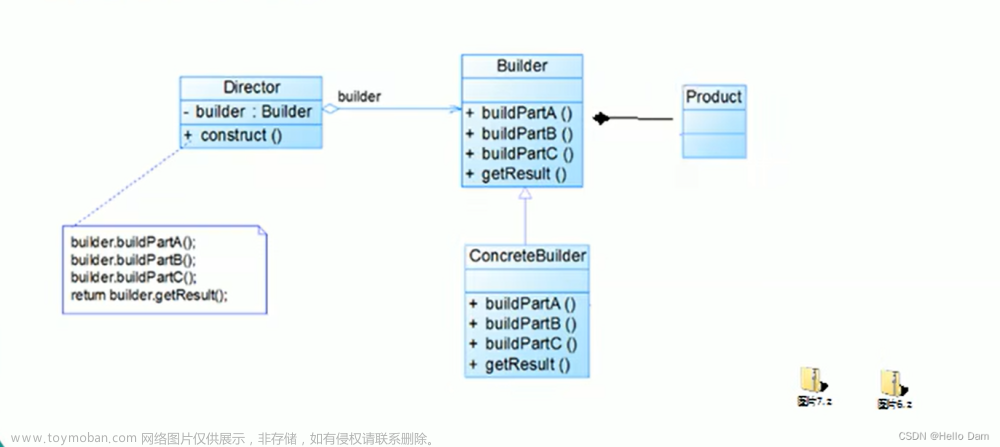
}建造者模式:
将一个复杂对象的构建过程与其表示分离,使得同样的构建过程,可以创建不同的表示。
用户只需要指定需要建造的类型就可以得到该类型对应的产品实例,不关心建造过程细节
也就是如何逐步构建包含多个组件的对象,相同的构建过程,可以创建不同的产品
缺点:
1.增加了类的数量:产生多余的Builder对象
2.内部修改困难:如果产品内部发生变化,建造者也要相应修改
优点:
1.封装性好:创建和使用分离
2.扩展性好:建造类之间相互独立,在一定程度上解耦
与工厂模式相比:
注重点不同:建造者模式更注重于方法的调用过程;工厂模式注重于创建产品,不关心方法掉用的顺序。
创建对象力度不同:创建对象的力度不同,建造者模式可以创建复杂的产品,由各种复杂的部件组成,工厂模式创建出来的都是相同的实例对象
适用场景:
结构复杂:对象有非常复杂的内部结构有很多属性。分离创建和使用:想把复杂对象创建和使用分离。
当创建一个对象需要很多步骤时,适合使用建造者模式。当创建一个对象只需要一个简单方法就可以完成,适合使用工厂模式。
实现代码:
#include<iostream>
#include<memory.h>
#include<string>
class PersonBuilder {
public:
virtual void buildHead() {}
virtual void buildBody() {}
virtual void buildArm() {}
virtual void buildLeg() {}
PersonBuilder(){}
PersonBuilder(std::string g, std::string p) {
this->g = g;
this->p = p;
}
virtual ~PersonBuilder() {};
std::string g, p;
};
class PersonThinBuilder : public PersonBuilder {
public:
PersonThinBuilder(std::string g, std::string p){
this->g = g;
this->p = p;
}
void buildHead() {
std::cout << "瘦子 画头" << std::endl;
}
void buildBody() {
std::cout << "瘦子 画身体" << std::endl;
}
void buildArm() {
std::cout << "瘦子 画胳膊" << std::endl;
}
void buildLeg() {
std::cout << "瘦子 画大腿" << std::endl;
}
};
class PersonFatBuilder : public PersonBuilder {
public:
PersonFatBuilder() {}
PersonFatBuilder(std::string g, std::string p) {
this->g = g;
this->p = p;
}
void buildHead() {
std::cout << "胖子 画头" << std::endl;
}
void buildBody() {
std::cout << "胖子 画身体" << std::endl;
}
void buildArm() {
std::cout << "胖子 画胳膊" << std::endl;
}
void buildLeg() {
std::cout << "胖子 画大腿" << std::endl;
}
};
class PersonDirector {
public:
PersonDirector(PersonBuilder* pb) {
this->pb = pb;
}
void createPerson() {
pb->buildHead();
pb->buildBody();
pb->buildArm();
pb->buildLeg();
}
private:
PersonBuilder* pb;
};
int
main() {
PersonThinBuilder* pt = new PersonThinBuilder("画瘦子", "红笔");
PersonDirector* pd = new PersonDirector(pt);
pd->createPerson();
return 0;
}简单工厂模式:
通过参数控制可以生产任何产品
优点:
简单粗暴,直观易懂。使用一个工厂生产同一等级结构下的任意产品
缺点:
1. 所有东西生产在一起,产品太多会导致代码量庞大
2. 开闭原则遵循(开放拓展,关闭修改)的不是太好,要新增产品就必须修改工厂方法。
工厂方法:
定义一个创建对象的接口,但是由子类来决定创建哪种对象,使用多个工厂分别生产指定的固定产品。
实现代码:
#include <iostream>
#include <string>
#include <memory>
class Fruit {
public:
Fruit(){}
virtual void show() = 0;
};
class Apple : public Fruit {
public:
Apple() {}
virtual void show() {
std::cout << "我是⼀个苹果" << std::endl;
}
};
class Banana : public Fruit {
public:
Banana() {}
virtual void show() {
std::cout << "我是⼀个⾹蕉" << std::endl;
}
};
class FruitFactory {
public:
static std::shared_ptr<Fruit> create(const std::string &name) {
if (name == "苹果") {
return std::make_shared<Apple>();
}else if(name == "⾹蕉") {
return std::make_shared<Banana>();
}
return std::shared_ptr<Fruit>();
}
};
int main()
{
std::shared_ptr<Fruit> fruit = FruitFactory::create("苹果");
fruit->show();
fruit = FruitFactory::create("⾹蕉");
fruit->show();
return 0;
}原型模式:
原型模式也正是提供了自我复制的功能,就是说新对象的创建可以通过已有对象进行创建。
优点:
1.可以克隆对象,而无需与他们所属的具体类相耦合
2.可以克隆预生成原型,避免反复运行初始化代码
3.可以更方便地生成复杂对象
4.可以用继承以外的方式来处理复杂对象的不同配置
缺点:
1.需要为每一个类都配置一个clone方法
2.clone方法位于类的内部,当对已有类进行改造时,需要修改代码,违背了开闭原则
3.当进行深拷贝的时候,需要编写较为复杂的代码,而且当对象之间存在多重嵌套时,为了实现深克隆,每一层对象对应的类都必须支持深克隆,实现复杂。
适用场景:
1.对象之间相同或相似,及只是个别的几个属性不同时
2.创建对象成本较大,例如初始化时间长,占用CPU太多,或者占用网络资源太多,需要优化资源
3.创建一个对象需要频繁的数据准备或访问权限等,需要提高性能或者提高安全性
4.系统中大量使用该类对象,且各个调用者都需要给它的属性重新赋值
实现代码:
#include<iostream>
#include<memory.h>
#include<string>
class Prototype{
public:
virtual ~Prototype(){}
virtual Prototype* Clone()const=0;
protected:
Prototype(){}
};
class ConcretePrototype:public Prototype{
public:
ConcretePrototype(){}
ConcretePrototype(const ConcretePrototype& cp){
std::cout<<"ConcretePrototype copy ..."<<std::endl;
}
~ConcretePrototype();
Prototype* Clone()const{
return new ConcretePrototype(*this);
}
};
int
main(){
Prototype* p=new ConcretePrototype();
Prototype* p1=p->Clone();
return 0;
}单例模式:
一个类只创建一个唯一的对象,即一次创建多次使用。
优点:
1.提供了对唯一实例的受控访问
2.由于在系统中只存在一个对象,因此可以节约系统资源,对于一些需要频繁创建和销毁的对象,单例模式无疑可以提高对系统的性能。
3.允许可变数目的实例
缺点:
1.由于单例模式中没有抽象层,因此单例类的扩展有很大的困难。
2.单例类的指责过重,在一定程度上违背了“单一职责原则”。
3.滥用单例将带来一些负面问题,如为了节省资源将数据库连接池对象设计为单例类,可能会导致共享连接池对象的程序过多
而出现连接池溢出;如果实例化对象长时间不被利用,系统就会认为是垃圾而被回收,这将导致对象状态的丢失。
步骤:
1.构造函数私有化
2.增加静态私有的当前类的指针变量
3.提供静态对外接口,可以让用户获得单例模式
细节:
1.饿汉模式:在类被加载的时候就将自己实例化,它的优点在于无须考虑多线程访问问题,可以确保实例的唯一性
由于一开始就得以创建,从调用速度和反应时间角度来讲要优于懒汉式。但是无论系统在运行时是否需要使用该实例对象
类在加载时该对象就会被创建,从资源利用效率来说饿汉式不及懒汉式,而且系统加载时由于要创建单例对象,加载时间比较长
2.懒汉模式:在第一次使用时创建,无需一直占用系统资源,实现了延迟加载,但是必须处理好多个线程同时访问的问题,特别是当
单例类作为资源控制器,在实例化时必然涉及资源初始化,而资源初始化很有可能耗费大量时间,这意味着出现多线程同时首次
引用类此类的几率变得更大,需要通过双重检查机制进行控制,可能会导致系统性能受到影响。
实现代码:
#include<iostream>
#include<memory.h>
#include<string>
//饿汉式
class SingletonHungry{
public:
static SingletonHungry* getInstance(){
return pSingleton;
}
private:
SingletonHungry(){}
static SingletonHungry* pSingleton;
};
SingletonHungry* SingletonHungry::pSingleton=new SingletonHungry;//在加载的时候就创建
class SingletonLazy{
public:
static SingletonLazy* getInstance(){
if(pSingleton==nullptr){
pSingleton=new SingletonLazy;
}
return pSingleton;
}
private:
SingletonLazy(){}
static SingletonLazy* pSingleton;
};
SingletonLazy* SingletonLazy::pSingleton=nullptr;
int
main(){
SingletonHungry* test1=SingletonHungry::getInstance();
SingletonHungry* test2=SingletonHungry::getInstance();
if(test1==test2) std::cout<<"饿汉单例模式"<<std::endl;
else std::cout<<"Not 饿汉单例模式"<<std::endl;
SingletonLazy* test3=SingletonLazy::getInstance();
SingletonLazy* test4=SingletonLazy::getInstance();
if(test3==test4) std::cout<<"懒汉单例模式"<<std::endl;
else std::cout<<"Not 懒汉单例模式"<<std::endl;
return 0;
}--------------------我是一个分界线,接下来是结构型模式-----------------------
适配器模式:
它结合了两个独立接口的功能,将一个类的接口转换成客户期望的另一个接口,让原本不兼容的类或者函数可以协同运作,是两个不兼容的接口之间的桥梁。
优点:
1.可以有效地解决接口的兼容性问题
2.灵活性强
缺点:
1.过多地使用适配器,会让系统非常零乱,不易整体进行把握。
比如,明明看到调用的是 A 接口,其实内部被适配成了 B 接口的实现,一个系统如果太多出现这种情况,无异于一场灾难。
因此如果不是很有必要,可以不使用适配器,而是直接对系统进行重构。
适用场景:
1.软件迭代过程中,出现接口不兼容的情况。
2.想要建立一个可以重复使用的类,用于与一些彼此之间没有太大关联的一些类,包括一些可能在将来引进的类一起工作,这些源类不一定有一致的接口。
3.通过接口转换,将一个类插入另一个类系中。
(比如老虎和飞禽,现在多了一个飞虎,在不增加实体的需求下,增加一个适配器,在里面包容一个虎对象,实现飞的接口。)
注意事项:
适配器不是在程序设计时添加的,而是为了解决正在服役的项目的问题
实现代码:
#include<iostream>
#include<memory.h>
#include<string>
class Target{
public:
Target(){}
virtual ~Target(){}
virtual void Request(){
std::cout<<"Target::Request"<<std::endl;
}
};
class Adaptee{
public:
Adaptee(){}
~Adaptee(){}
void SpecificRequest(){
std::cout<<"Adaptee::SpecificRequest"<<std::endl;
}
};
class Adapter:public Target{
public:
Adapter(Adaptee* ade){
_ade=ade;
}
~Adapter(){}
void Request(){
_ade->SpecificRequest();
}
private:
Adaptee* _ade;
};
int
main(){
Adaptee* ade=new Adaptee;
Target* adt =new Adapter(ade);
adt->Request();
return 0;
}桥接模式:
将抽象化与实现化分离,使得二者可以独立地变化。桥接模式是把继承关系转化成了组合关系。实现了抽象与实现分离
优点:
1.将现实抽离出来,再实现抽象,使得对象的具体实现依赖于抽象,满足了依赖倒转原则
2.将可以共享的变化部分,抽离出来,减少了代码的重复信息
3.对象的具体实现可以更加灵活,可以满足多个因素的要求
4.提高了系统可扩展性,某个维度需要扩展只需要增加实现类接口或者具体实现类,而且不影响另一个维度,符合开闭原则
缺点:
1.会增加系统的理解与设计难度,因为关联关系建立在抽象层,需要一开始就在抽象层进行设计与编程
2.要求正确识别出系统中两个或多个独立变化的维度,如何准确识别系统中的两个维度是应用桥接模式的难点
适用场景:
1.系统需要在抽象化和具体化之间增加更多的灵活性,避免两个层次之间建立静态的继承关系,通过桥接模式可以使它们在抽象层中建立一个关联关系。
2.一个类存在两个或多个独立变化的维度,且这两个或多个维度都需要独立进行拓展
3.对于那些不希望使用继承或者因为多层继承导致系统类的个数急剧增加的系统
//以 windows 的画图软件为例子。pen 为基类对外暴露 drow接口,画出的线为 粗、中、细。颜色分为 红黄蓝。若以继承的方式实现。则需要 3*3 = 9个子类进行排列组合。而使用桥接模式。 只需要6个即可。显然粗细和颜色种类越多越大优势越明显。
实现代码:
#include<iostream>
#include<string>
class AbstractionImp {
public:
virtual ~AbstractionImp() {}
virtual void Operation() = 0;
protected:
AbstractionImp() {}
};
class Abstraction {
public:
virtual ~Abstraction() {}
virtual void Operation() = 0;
protected:
Abstraction() {}
};
class RefinedAbstaction :public Abstraction {
public:
RefinedAbstaction(AbstractionImp* imp) {
_imp = imp;
}
~RefinedAbstaction() {}
void Operation() {
_imp->Operation();
}
private:
AbstractionImp* _imp;
};
class ConcreteAbstractionImpA : public AbstractionImp {
public:
ConcreteAbstractionImpA() {}
~ConcreteAbstractionImpA() {}
virtual void Operation() {
std::cout << "ConcreteAbstractionImpA...." << std::endl;
}
};
class ConcreteAbstractionImpB : public AbstractionImp {
public:
ConcreteAbstractionImpB() {}
~ConcreteAbstractionImpB() {}
virtual void Operation() {
std::cout << "ConcreteAbstractionImpB...." << std::endl;
}
};
int
main() {
AbstractionImp* imp = new ConcreteAbstractionImpA();
Abstraction* abs = new RefinedAbstaction(imp);
abs->Operation();
return 0;
}组合实体模式:
是一种结构型设计模式,可以使用它将对象组合成树状结构,并且能像使用独立对象一样使用它们。
优点:
1.可以让客户端以统一的方式处理单个对象和组合对象
2.可以让你更加容易地增加新类型的组件
缺点:
1.可能使你的设计变得过于通用。有时候只有叶子组件需要定义某些操作,但是由于通用性,你不得不在所有组件中定义这些操作
适用场景:
例如:在图形用户界面中,许多图形用户界面都使用了组合模式来组织和管理窗口、面板等组件。文件系统,通常使用组合模式来表示文件和文件夹的层次结构,
XML/HTML文档也可以使用组合模式来表示其树形结构
实现代码:
#include<iostream>
#include<algorithm>
#include<memory.h>
#include<string>
#include<list>
class Component{
public:
Component(){}
virtual ~Component(){}
virtual void Operation()=0;
virtual void Add(Component* pChild){};
virtual void Remove(Component* pChild){};
virtual Component* GetChild(int nIndex){
return nullptr;
};
};
class Leaf: public Component{
public:
Leaf(){}
virtual ~Leaf(){}
virtual void Operation(){
std::cout<<"Operation by leaf\n";
}
};
class Composite:public Component{
public:
Composite(){}
virtual ~Composite(){
std::list<Component*>::iterator iter1,iter2,temp;
for(iter1 =m_ListOfComponent.begin(),iter2=m_ListOfComponent.end();iter1!=iter2;){
temp=iter1;
++iter1;
delete *temp;
}
}
virtual void Operation(){
std::cout<<"Operation by Composite\n";
std::list<Component*>::iterator iter1,iter2;
for( iter1=m_ListOfComponent.begin(), iter2=m_ListOfComponent.end(); iter1!=iter2; ++iter1){
(*iter1)->Operation();
}
}
virtual void Add(Component* pChild){
m_ListOfComponent.push_back(pChild);
}
virtual void Remove(Component* pChild){
std::list<Component*>::iterator iter;
iter=find(m_ListOfComponent.begin(),m_ListOfComponent.end(),pChild);
if(m_ListOfComponent.end()!=iter){
m_ListOfComponent.erase(iter);
}
}
virtual Component* GetChild(int nIndex){
if(nIndex <=0 ||nIndex > m_ListOfComponent.size()) return nullptr;
std::list<Component*>::iterator iter1,iter2;
int i;
for(i=1,iter1=m_ListOfComponent.begin(),iter2=m_ListOfComponent.end() ; iter1!=iter2 ; ++iter1, ++i){
if(i == nIndex) break;
}
return *iter1;
}
private:
std::list<Component*> m_ListOfComponent;
};
int
main(){
Leaf* pLeaf1=new Leaf();
Leaf* pLeaf2=new Leaf();
Composite* pComposite=new Composite;
pComposite->Add(pLeaf1);
pComposite->Add(pLeaf2);
pComposite->Operation();
pComposite->GetChild(2)->Operation();
return 0;
}装饰器模式:
在不改变原类文件或使用继承的前提下,动态的拓展一个对象,进而达到增强或者增加对象的目的
优点:
1.灵活性好,相比继承,装饰器模式拓展对象功能更加灵活
2.扩展性好,不同装饰组合,可以创造出各式各样的对象,且避免了类爆炸
3.满足设计模式要求的开闭原则和复用原则
4.透明性好,客户端针对抽象操作,对具体实现的内容不可见
缺点:
1.复杂性高。装饰器的设计往往具备较高复杂度,对开发者的水平要求高
适用场景:
例如图形用户界面:许多图形用户界面都使用了装饰器模式来动态地添加新的行为和样式。数据压缩,日志记录等
实现代码:
#include<iostream>
#include<memory>
#include<string>
class AbstractHero{
public:
virtual void showStatus()=0;
int mHp,mMp,mAt,mDf;
};
class HeroA:public AbstractHero{
public:
HeroA(){
mHp=0,mMp=0,mAt=0,mDf=0;
}
virtual void showStatus(){
std::cout<<"血量:"<<mHp<<std::endl;
std::cout<<"魔法:"<<mMp<<std::endl;
std::cout<<"攻击:"<<mAt<<std::endl;
std::cout<<"防御:"<<mDf<<std::endl;
}
};
//英雄穿上某个装饰物,那么也还是一个英雄
class AbstractEquipment: public AbstractHero{
public:
AbstractEquipment(AbstractHero* hero){
pHero=hero;
}
virtual void showStatus(){}
AbstractHero* pHero;
};
//给英雄穿上狂徒铠甲
class KuangtuEquipment:public AbstractEquipment{
public:
KuangtuEquipment(AbstractHero* hero):AbstractEquipment(hero){}
//增加新的功能
void AddKuangtu(){
std::cout<<"新英雄穿上狂徒之后"<<std::endl;
this->mHp=this->pHero->mHp;
this->mMp=this->pHero->mMp;
this->mAt=this->pHero->mAt;
this->mDf=this->pHero->mDf+30;
}
virtual void showStatus(){
AddKuangtu();
std::cout<<"血量:"<<mHp<<std::endl;
std::cout<<"魔法:"<<mMp<<std::endl;
std::cout<<"攻击:"<<mAt<<std::endl;
std::cout<<"防御:"<<mDf<<std::endl;
}
};
int main(){
AbstractHero* hero=new HeroA;
hero->showStatus();
std::cout<<"------------------------"<<std::endl;
//给英雄穿上狂徒
hero=new KuangtuEquipment(hero);
hero->showStatus();
return 0;
}外观模式(门面模式):
是指外部与子系统的通信必须通过一个统一的外观对象进行,
为子系统中的一组接口提供一个一致的界面,定义一个高层接口,这个接口使得这一子系统更加容易使用
优点:
1.简化客户端与子系统之间的交互,使得客户端更容易使用子系统
2.可以降低客户端与子系统之间的耦合度,使得客户端不需要直接与子系统交互
3.可以在不影响客户端的情况下改变子系统的实现
缺点:
1.可能会限制客户端对子系统的访问,因为客户端只能通过外观类来访问子系统
2.如果设计不仔细,可能会成为一个庞大和复杂的类,难以维护
适用场景:
1.在软件开发中,经常会使用外观模式来封装底层的库或者框架,为上一层提供一个简单的接口。这样可以降低上层应用与底层库之间的耦合度,使得上层应用更加容易开发维护
2.在操作系统中,外观模式也被经常广泛使用。例如,操作系统为应用程序提供了一个简单的接口,使得应用程序可以方便访问硬件资源,而无需直接与硬件驱动程序交互
3.在Web开发中,Web框架通常会为开发人员提供了一个简单接口,使得开发人员可以方便地开发Web应用,而无需关心底层的http协议和服务器配置
实现代码:
#include<iostream>
#include<string>
#include<memory>
class Television{
public:
void on(){
std::cout<<"电视机打开"<<std::endl;
}
void off(){
std::cout<<"电视机关闭"<<std::endl;
}
};
class Light{
public:
void on(){
std::cout<<"灯打开"<<std::endl;
}
void off(){
std::cout<<"灯关闭"<<std::endl;
}
};
class DVDplayer{
public:
void on(){
std::cout<<"DVD打开"<<std::endl;
}
void off(){
std::cout<<"DVD关闭"<<std::endl;
}
};
//外观模式
class KTVMode{
public:
KTVMode(){
pTV=new Television;
pLight=new Light;
pDvD=new DVDplayer;
}
void onKTV(){
pTV->on();
pLight->on();
pDvD->on();
}
~KTVMode(){
pTV->off();
pLight->off();
pDvD->off();
delete pTV,pLight,pDvD;
}
private:
Television* pTV;
Light* pLight;
DVDplayer* pDvD;
};
int
main(){
KTVMode* ktv1=new KTVMode;
ktv1->onKTV();
delete ktv1;
return 0;
}享元模式:
是轻量级的意思,中文翻译成享元。通过共享技术实现相同或相似的重用。运用共享技术有效地支持大量细颗粒对象的复用
优点:
1.可以减少内存占用,提高程序的性能。它通过共享对象来减少对象的数量,从而减少内存占用
2.它可以提高程序的执行速度。由于对象减少,程序在运行时需要处理的对象也减少了,因此程序的执行速度会加快
缺点:
1.享元模式会增加程序的复杂性。您需要将对象的状态分为内部状态和外部状态,并在实现享元对象时考虑如何共享内部状态。
2.它可能会增加程序的维护成本,由于享元模式将对象的创建和使用分离,您需要在客户端代码中管理外部状态,并使用享元模式对象时将外部状态传递给它。这可能会增加程序的维护成本
适用场景:
1.一个应用程序使用大量相同或者相似的对象,造成很大的存储开销。
2.对象的大部分状态都可以外部化,可以将这些外部状态传入对象中
3.如果删除对象的外部状态,那么可以用相对较少的共享对象取代很多组对象
4.应用程序不依赖于对象标识。由于享元对象可以被共享,对于概念上有明显的别的对象,标识测试将返回真值
5.使用享元模式需要维护一个存储享元对象的享元池,而这需要消耗资源,因此,应当在多次重复使用享元对象时才值得使用享元模式。
实现代码:
#include<iostream>
#include<list>
#include<algorithm>
class ConcreateFlyweight;
class Flyweight{
public:
virtual ~Flyweight(){}
std::string GetIntrinsicState(){
return m_State;
}
virtual void Operation(std::string& ExtrinsicState)=0;
protected:
Flyweight(const std::string& state):m_State(state){}
private:
std::string m_State;
};
class ConcreateFlyweight:public Flyweight{
public:
ConcreateFlyweight(const std::string& state):Flyweight(state){}
virtual ~ConcreateFlyweight(){}
virtual void Operation(std::string& ExtrinsicState){}
};
class FlyweightFactory{
public:
FlyweightFactory(){}
~FlyweightFactory(){
for(std::list<Flyweight*>::iterator iter1=m_ListFlyweight.begin(), temp; iter1!=m_ListFlyweight.end(); ){
temp=iter1;
++iter1;
delete *temp;
}
m_ListFlyweight.clear();
}
Flyweight* GetFlyweight(const std::string& key){
for(std::list<Flyweight*>::iterator iter1=m_ListFlyweight.begin(); iter1!=m_ListFlyweight.end(); ++iter1){
if((*iter1)->GetIntrinsicState() == key){
std::cout<<"The Flyweight:"<< key<<" already exits " <<std::endl;
return (*iter1);
}
}
std::cout<<"Creating a new Flyweight:"<<key <<std::endl;
Flyweight* flyweight =new ConcreateFlyweight(key);
m_ListFlyweight.push_back(flyweight);
}
private:
std::list<Flyweight*> m_ListFlyweight;
};
int
main(){
FlyweightFactory flyweightfactory;
flyweightfactory.GetFlyweight("hello");
flyweightfactory.GetFlyweight("world");
flyweightfactory.GetFlyweight("hello");
return 0;
}代理模式:
在不改变软件的前提下提供一个代理,以控制对原对象的访问
优点:
1.指责清晰,真实对象专注于自身业务逻辑,不用考虑其他非本职内容,交给代理完成
2.高扩展性,真实对象的改变不影响代理
3.解耦,将客户端与真实对象分离,降低系统耦合度
4.提高性能,虚拟代理可以减少系统资源的消耗
5.高安全性和稳定性,代理能更好地控制访问,提高系统安全
缺点:
1.增加系统复杂度。代理的职责冗杂
2.请求速度低。客户端与真实对象中加入代理,一定程度上会降低整个系统流程的运行效率
适用场景:
当需要对原对象进行访问控制、提供额外功能、较少客户端代码复杂性等都可以使用代理模式
实现代码:
#include<iostream>
#include<string>
#include<memory>
class AbstractCommonInterface{
public:
virtual void run() =0;
};
class MySystem:public AbstractCommonInterface{
public:
virtual void run(){
std::cout<<"系统启动"<<std::endl;
}
};
class MySystemProxy:public AbstractCommonInterface{
public:
MySystemProxy(std::string username,std::string password){
mUserName=username;
mPassWord=password;
pMySystem=new MySystem;
}
bool Check(){
if(mUserName=="admin" && mPassWord=="admin"){
return true;
}
return false;
}
virtual void run(){
if(Check()==true){
std::cout<<"启动成功"<<std::endl;
pMySystem->run();
}else{
std::cout<<"用户名或密码错误\n";
}
}
~MySystemProxy(){
if(pMySystem !=nullptr){
delete pMySystem;
}
}
private:
std::string mUserName,mPassWord;
MySystem* pMySystem;
};
int
main(){
MySystemProxy* proxy =new MySystemProxy("admin","admin");
proxy->run();
return 0;
}---------------------我是一个分界线,接下来是行为模式------------------------
责任链模式:
为请求创建了一个接收者对象的链。这种模式给予请求的类型,对请求的发送者和接收者进行解耦。
优点:
1.降低耦合度,他将请求的发送者和接收者解耦
2.增强了给对象指派职责的灵活性:通过改变链内的成员或调动他们的次序,允许动态地新增或删除责任
3.增加新的请求处理类很方便
缺点:
1.不能保证请求处理一定被处理,因为请求没有明确的接收者
2.系统性能将受到一定影响,而且在进行代码调试时不太方便;可能会造成循环调用
3.可能不容易观察运行时的特征,有碍于出错
适用场景:
例如在Java中的异常处理机制,当一个方法抛出异常时,如果该方法内部没有处理该异常,则会将异常传递给调用该方法的上层方法进行处理,直到被处理或者抛出到程序的最外层
JavaScript中的事件冒泡机制
Servlet开发中的过滤器链
实现代码:
#include<iostream>
#include<algorithm>
#include<vector>
#include<string>
class PurchaseRequest{
public:
int getType()const{
return type;
}
float getPrice()const{
return price;
}
int getId()const{
return id;
}
PurchaseRequest(const int type,const float price,const int id):type(type),price(price),id(id){
}
private:
int type,id;
float price;
};
class Approver{
public:
void setApprover(Approver* const approver){
this->approver=approver;
}
explicit Approver(const std::string& name):name(name){}
virtual void processRequest(PurchaseRequest* purchaseRequest)=0;
protected:
Approver* approver;
std::string name;
};
class DepartmentApprover:public Approver{
public:
explicit DepartmentApprover(const std::string& name):Approver(name){}
void processRequest(PurchaseRequest* purchaseRequest)override{
if(purchaseRequest->getPrice()<=5000){
std::cout<<"请求编号id= "<<purchaseRequest->getId()<<"被"<<this->name<<"处理"<<std::endl;
}else{
approver->processRequest(purchaseRequest);
}
}
};
class CollegeApprover:public Approver{
public:
explicit CollegeApprover(const std::string& name):Approver(name){}
void processRequest(PurchaseRequest* purchaseRequest)override{
if(purchaseRequest->getPrice()>5000 && purchaseRequest->getPrice()<=10000){
std::cout<<"请求编号id= "<<purchaseRequest->getId()<<"被"<<this->name<<"处理"<<std::endl;
}else{
approver->processRequest(purchaseRequest);
}
}
};
class ViceSchoolMasterApprover:public Approver{
public:
explicit ViceSchoolMasterApprover(const std::string& name):Approver(name){}
void processRequest(PurchaseRequest* purchaseRequest)override{
if(purchaseRequest->getPrice()>10000 && purchaseRequest->getPrice()<=30000){
std::cout<<"请求编号id= "<<purchaseRequest->getId()<<"被"<<this->name<<"处理"<<std::endl;
}else{
approver->processRequest(purchaseRequest);
}
}
};
int
main(){
PurchaseRequest* purchaseRequest =new PurchaseRequest(1,10005,1);
DepartmentApprover* department =new DepartmentApprover("庄主任");
CollegeApprover* college=new CollegeApprover("李院长");
ViceSchoolMasterApprover* viceSchoolMaster =new ViceSchoolMasterApprover("王副校长");
department->setApprover(college);
college->setApprover(viceSchoolMaster);
department->processRequest(purchaseRequest);//部长审批不了转交给学院,学院审批不来转交给副校长,副校长能审批批下来了
return 0;
}命令模式:
将一个请求封装为一个对象,使发出请求的责任和执行请求的责任分割开。
优点:
1.封装性好,每个命令都被封装起来,对于客户端来说,需要什么功能就去调用相应的命令,而无需知道命令具体是怎么执行的
缺点:
1.可能会导致某些系统有过多的具体命令类。因为针对每一个命令都需要设计一个具体命令类,因此某些系统可能需要大量具体命令类,这将影响命令模式使用
适用场景:
系统需要将请求者和请求接收者解耦,使得调用者和接收者不直接交互
系统需要在不同的时间指定请求,将请求排队和执行请求
系统需要支持命令的撤销操作和恢复操作
(认为是命令的地方都可以使用命令模式)
实现代码:
#include<iostream>
#include<vector>
#include<List>
#include<memory>
#include<queue>
#include<windows.h>
class HandleClinetProtocal{
public:
void AddMoney(){
std::cout<<"给玩家增加金币"<<std::endl;
}
void AddDiamond(){
std::cout<<"给玩家增加钻石"<<std::endl;
}
};
class AbstractCommand{
public:
virtual void handle()=0;
};
class AddMoneyCommand:public AbstractCommand{
public:
AddMoneyCommand(HandleClinetProtocal* protocal){
this->pProtocol=protocal;
}
virtual void handle(){
this->pProtocol->AddMoney();
}
HandleClinetProtocal* pProtocol;
};
class AddDiamondCommand:public AbstractCommand{
public:
AddDiamondCommand(HandleClinetProtocal* protocal){
this->pProtocol=protocal;
}
virtual void handle(){
this->pProtocol->AddMoney();
}
HandleClinetProtocal* pProtocol;
};
//服务器程序(命令调用类)
class Server{
public:
void addRequest(AbstractCommand* command){
mCommands.push(command);
}
//启动处理程序
void startHandle(){
while(!mCommands.empty()){
Sleep(1000);
AbstractCommand* command =mCommands.front();
command->handle();
mCommands.pop();
}
}
std::queue<AbstractCommand*> mCommands;
};
int
main(){
HandleClinetProtocal* protocal=new HandleClinetProtocal;
//客户端增加金币的请求
AbstractCommand* addmoney =new AddMoneyCommand(protocal);
//客户端增加钻石的请求
AbstractCommand* adddiamond =new AddDiamondCommand(protocal);
//将客户端的请求加入到请求队列中
Server* server =new Server;
server->addRequest(addmoney);
server->addRequest(adddiamond);
//服务器开始处理请求
server->startHandle();
return 0;
}解释器模式:
是指给定一个语言(表达式),定义它的文法的一种表示,并定义一个解释器,使用该解释器来解释语言中的句子(表达式)
优点:
1.具有良好的扩展性。语法的翻译通过类来实现,扩展类可以扩展其解释能力
2.实现难度低,语法树中每个表达式节点类具备一定相似性,实现起来相对容易
缺点:
1.执行效率低。解释器中通常有大量循环和递归语句,当被解释句子较复杂的时候,程序的性能受到较大影响
2.类膨胀问题。规则较多时,类数量也膨胀
适用场景:
当某个特定类型问题发生频率足够高的时候,例如,简单语法解释,编译器,运算表达式计算,正则表达式,日志处理:使用脚本语言或者编程语言处理日志时,
会产生大量报表,需要对日志进行解析,生成报表
各个服务的日志格式不同,数据中的要素相同,这种情况下,通过程序解决上述问题,主要解决方案就是使用解释器模式,日常项目中使用解释器模式很少
与适配器模式对比:两个模式类似,但是适配器模式不需要预先知道适配器的规则。解释器模式需要预先将规则写好,根据规则执行解释
实现代码:
#include<iostream>
#include<list>
#include<vector>
#include<algorithm>
class Context{
public:
Context(int num){
m_num=num;
}
void setNum(int num){
m_num=num;
}
int getNum(){
return m_num;
}
void setRes(int res){
m_res=res;
}
int getRes(){
return m_res;
}
private:
int m_num,m_res;
};
class Expression{
public:
virtual void interpreter(Context* context) =0;
};
class PlusExpression :public Expression{
public:
virtual void interpreter(Context* context){
int num=context->getNum();
num++;
context->setNum(num);
context->setRes(num);
}
};
class MinusExpression :public Expression{
public:
virtual void interpreter(Context* context){
int num =context->getNum();
num--;
context->setNum(num);
context->setRes(num);
}
};
int
main(){
Context* pcxt =new Context(10);
Expression* e1=new PlusExpression();
e1->interpreter(pcxt);
std::cout<<"PlusExpression:"<<pcxt->getRes()<<std::endl;
Expression* e2 =new MinusExpression();
e2->interpreter(pcxt);
std::cout<<"MinusExpression:"<<pcxt->getRes()<<std::endl;
delete e1,e2,pcxt;
return 0;
}迭代器模式:
提供一种遍历集合元素的统一接口,用一致的方法遍历集合元素,不需要知道集合对象的底层表示。而且不管这些对象是什么都需要遍历的时候,就应该选择使用迭代器模式
优点:
1.它支持以不同的方式遍历一个聚合对象,而无需暴露它的内部表示
2.迭代器简化了聚合类
3.在迭代器模式中,由于引入了抽象类,增加新的聚合类和迭代器都很方便,无需修改原有代码
缺点:
1.由于多了一个抽象层,会增加系统的复杂性
2.对于简单的遍历(如数组),使用迭代器方式遍历较为繁琐
适用场景:
常用于遍历各种容器,如链表,数组,树等。在STL容器中,就广泛使用了迭代器模式,
STL中容器(vector,list,set)等都提供了迭代器,可以使用迭代器来遍历访问容器中所有元素
实现代码:
#include<iostream>
#include<algorithm>
#include<string>
#include<vector>
#include<list>
class Iterator{//迭代抽象类,用于定义得到开始对象、得到下一个对象、判断是否到结尾、当前对象等抽象方法,统一接口
public:
Iterator(){}
virtual ~Iterator(){}
virtual std::string First() =0;
virtual std::string Next() =0;
virtual std::string CurrentItem() =0;
virtual bool IsDone() =0;
};
class Aggregate{//聚集抽象类
public:
virtual int Count() =0;
virtual void Push(const std::string& strValue) =0;
virtual std::string Pop(const int nIndex) =0;
virtual Iterator* CreateIterator() =0;
};
class ConcreteIterator:public Iterator{
public:
ConcreteIterator(Aggregate* pAggregate):m_nCurrent(0),Iterator(){
m_Aggregate =pAggregate;
}
std::string First(){
return m_Aggregate->Pop(0);
}
std::string Next(){
std::string strRet;
m_nCurrent++;
if(m_nCurrent < m_Aggregate->Count()){
strRet =m_Aggregate->Pop(m_nCurrent);
}
return strRet;
}
std::string CurrentItem(){
return m_Aggregate->Pop(m_nCurrent);
}
bool IsDone(){
return ((m_nCurrent >= m_Aggregate->Count()) ? true :false);
}
private:
Aggregate* m_Aggregate;
int m_nCurrent;
};
class ConcreteAggregate:public Aggregate{
public:
ConcreteAggregate():m_pIterator(nullptr){
m_vecItems.clear();
}
~ConcreteAggregate(){
if(m_pIterator){
delete m_pIterator;
m_pIterator=nullptr;
}
}
Iterator* CreateIterator(){
if(!m_pIterator){
m_pIterator=new ConcreteIterator(this);
}
return m_pIterator;
}
int Count(){
return m_vecItems.size();
}
void Push(const std::string& strValue){
m_vecItems.push_back(strValue);
}
std::string Pop(const int nIndex){
std::string strRet;
if(nIndex < Count()){
strRet =m_vecItems[nIndex];
}
return strRet;
}
private:
std::vector<std::string> m_vecItems;
Iterator* m_pIterator;
};
int
main(){
ConcreteAggregate* pName=new ConcreteAggregate();
if(pName){
pName->Push("hello");
pName->Push("word");
pName->Push("cxue");
}
Iterator* iter =nullptr;
iter= pName->CreateIterator();
if(iter){
std::string strItem =iter->First();
while(!iter->IsDone()){
std::cout<< iter->CurrentItem()<<" is ok "<<std::endl;
iter->Next();
}
}
return 0;
}中介者模式:
是一种行为型的软件设计模式,也称为仲裁者模式,顾名思义,该模式的作用就是中介,帮助其他类进行良好的交流。
优点:
1.解耦,中介的存在使得同事对象间的强耦合关系解除,他们可以独立地变化而不会影响到整体,便于复用
2.良好扩展性。交互行为发生改变,只需要扩展中介即可
3.集中交互,便于管理
缺点:
1.中介者的职责很重要,并且复杂。
适用场景:
当多个类之间相互耦合,形成网状结构,需要将网状结构分离为星型结构时
代码实现:
#include<iostream>
#include<string>
#include<memory>
#include<vector>
class Mediator{
public:
virtual void send(std::string message,Colleague* colleague) =0;
virtual void add(Colleague* colleague)=0;
};
class Colleague{
public:
Mediator* getMediator(){
return mediator;
}
void setMediator(Mediator* const mediator){
this->mediator=mediator;
}
Colleague(Mediator* mediator){
this->mediator =mediator;
this->mediator->add(this);
}
virtual void Notify(std::string message)=0;
private:
Mediator* mediator;
};
class ConcreteColleague1:public Colleague{
public:
ConcreteColleague1(Mediator* mediator):Colleague(mediator){}
void send(std::string message){
getMediator()->send(message,this);
}
void Notify(std::string message){
std::cout<<"同事1收到信息:"+message<<std::endl;
}
};
class ConcreteColleague2:public Colleague{
public:
ConcreteColleague2(Mediator* mediator):Colleague(mediator){}
void send(std::string message){
getMediator()->send(message,this);
}
void Notify(std::string message){
std::cout<<"同事2收到信息:"+message<<std::endl;
}
};
class ConcreteMediator:public Mediator{
public:
void add(Colleague* colleague){
colleaguesList.push_back(colleague);
}
void send(std::string message,Colleague* colleague){
for(auto value:colleaguesList){
if(value!=colleague){
value->Notify(message);
}
}
}
private:
std::vector<Colleague*> colleaguesList;
};
int
main(){
Mediator* mediator =new ConcreteMediator();
ConcreteColleague1* colleague1 =new ConcreteColleague1(mediator);
ConcreteColleague2* colleague2 =new ConcreteColleague2(mediator);
colleague1->send("早上好啊");
colleague2->send("早安!");
return 0;
}备忘录模式:
在不破坏封装性的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态。这样以后就可以将该对象恢复到原先的状态
优点:
1.当发起人角色的状态有改变时,有可能是个错误的改变,我们使用备忘录模式就可以把这个错误改变还原。
2.备份的状态是保存在发起人角色之外的,这样,发起人角色就不需要对各个备份的状态进行管理
缺点:
1.如果备份的对象存在大量的信息或者创建、恢复操作非常频繁,则可能造成很大的性能开销
适用场景:
必须保存一个对象在某一时刻的状态,这样可以以后在需要的时候恢复到当前的状态
如果让其他对象直接保存当前对象的状态,将会暴露对象的实现细节,破坏对象的封装
实现代码:
#include<iostream>
#include<list>
#include<memory>
#include<string>
#include<vector>
class Memento{
public:
explicit Memento(const std::string& state):state(state){}
std::string getState()const{
return state;
}
private:
std::string state;
};
class Originator{
public:
std::string getState()const{
return state;
}
void setState(const std::string& state){
this->state=state;
}
Memento SaveStateMemento(){
return Memento(state);
}
void getStateFromMemento(Memento memento){
state=memento.getState();
}
private:
std::string state;
};
class Caretaker{
public:
void add(Memento memento){
mementoList.push_back(memento);
}
Memento get(int index){
return mementoList[index];
}
private:
std::vector<Memento> mementoList;
};
int
main(){
Originator originator;
Caretaker caretaker;
originator.setState("状态1,攻击力为100");
//保存当前状态
caretaker.add(originator.SaveStateMemento());
//受到debuff,攻击力下降
originator.setState("状态2,攻击力为80");
//保存状态
caretaker.add(originator.SaveStateMemento());
std::cout<<"当前状态:"<<originator.getState()<<std::endl;
std::cout<<"debuff状态结束,回到状态1"<<std::endl;
originator.getStateFromMemento(caretaker.get(0));
std::cout<<"恢复到状态1后的状态"<<originator.getState();
return 0;
}观察者模式:
定义对象间一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动更新。
优点:
1.松散耦合:观察者模式提供了一种松散耦合的设计,使得当一个对象的状态发生变化时,它不需要知道其他对象是如何使用这些信息的。是的系统更容易扩展和维护
2.动态关联:观察者模式允许在运行时动态地添加或删除观察者,而无需修改主题或其他观察者的代码。
3.抽象解耦:由于主题和观察者之间仅通过抽象接口进行通信,因此他们之间的耦合是抽象的,而不是具体的
缺点:
1.可能导致意外的更新,如果一个观察者在接收到通知后执行了一些操作,这些操作又导致了主题状态的变化,那么就可能会导致意外的更新
2.可能导致性能问题,如果有大量的观察者需要更新,那么通知所有观察者可能会导致性能问题
3.可能增加复杂性,如果没有正确实现,观察者模式可能会增加系统的复杂性
适用场景:
当一个对象的状态发生变化时,需要通知其他对象。当一个对象的状态发生变化时,需要执行一些操作。当需要在多个对象之间实现松散耦合的设计时候
代码实现:
#include<iostream>
#include<string>
#include<memory>
#include<list>
class AbstractHero{//抽象的英雄,抽象的观察者
public:
virtual void Update() =0;
};
class HeroA :public AbstractHero{//具体的英雄,具体的观察者
public:
HeroA(){
std::cout<<"英雄A正在撸BOSS"<<std::endl;
}
virtual void Update(){
std::cout<<"英雄A停止撸,待机状态"<<std::endl;
}
};
class HeroB :public AbstractHero{
public:
HeroB(){
std::cout<<"英雄B正在撸BOSS"<<std::endl;
}
virtual void Update(){
std::cout<<"英雄B停止撸,待机状态"<<std::endl;
}
};
class AbstractBoss{//定义抽象的观察目标
public:
virtual void addHero(AbstractHero* hero) =0;//添加观察者
virtual void deleteHero(AbstractHero* hero)=0;//删除观察者
virtual void notifv()=0;
};
class BOSSA:public AbstractBoss{
public:
virtual void addHero(AbstractHero* hero){
pHeroList.push_back(hero);
}
virtual void deleteHero(AbstractHero* hero){
pHeroList.remove(hero);
}
virtual void notifv(){
for(std::list<AbstractHero*>::iterator it=pHeroList.begin();it!=pHeroList.end();it++){
(*it)->Update();
}
}
std::list<AbstractHero*> pHeroList;
};
int
main(){
//创建观察者
AbstractHero* heroA=new HeroA;
AbstractHero* heroB=new HeroB;
//创建观察目标
AbstractBoss* bossA=new BOSSA;
bossA->addHero(heroA);
bossA->addHero(heroB);
std::cout<<"heroA 阵亡"<<std::endl;
bossA->deleteHero(heroA);
std::cout<<"Boss死了,通知其他英雄停止攻击"<<std::endl;
bossA->notifv();
delete heroA,heroB,bossA;
return 0;
}状态模式:
允许一个对象在其内部改变时改变它的行为,对象看起来似乎修改了它的类。它可视为策略的拓展。二者都基于组合机制
它们都通过将部分工作委派给“帮手”对象来改变其在不同情景下的行为。策略使得这些对象之间完全独立,他们不知道对象的存在。
但状态模式没有限制具体状态之间的依赖,且允许他们自行改变在不同情景下的状态
优点:
1.封装了转换规则,还枚举可能的状态,在枚举状态之前需要确认状态种类
2.符合开闭原则。无需修改已有状态类和上下文就能引入新状态
3.通过消除臃肿的状态机条件语句简化上下文代码
缺点:
1.如果状态机只有很少的几个状态,或者很少发生改变,反而会增加系统的复杂度
2.对“开闭原则”的支持不太好,对于可以切换状态的状态模式,增加新的状态类需要修改那些负责转换的源代码,否则无法切换到新增状态
适用场景:
1.一个对象的行为取决于它的状态,并且它必须在运行时刻根据状态改变它的行为
2.代码中包含大量的与对象状态有关的条件语句
代码实现:
#include<iostream>
#include<string>
#include<memory>
class War;
class State{
public:
virtual void Prophase(){}
virtual void Metaphase(){}
virtual void Anaphase(){}
virtual void End(){}
virtual void CurrentState(War* war){}
};
class War{
private:
State* m_state;//目前状态
int m_days;//战争持续时间
public:
War(State* state):m_state(state),m_days(0){}
~War(){ delete m_state; }
int GetDays(){ return m_days; }
void SetDays(int days){ m_days = days; }
void SetState(State* state){ delete m_state; m_state = state; }
void GetState(){ m_state->CurrentState(this); }
};
//战争结束状态
class EndState: public State{
public:
void End(War* war){
std::cout<<"战争结束"<<std::endl;
}
void CurrentState(War* war){
End(war);
}
};
//后期
class AnaphaseState: public State{
public:
void Anaphase(War* war){//后期具体的行为
if(war->GetDays() < 30){
std::cout<<"第"<<war->GetDays()<<"天:战争后期,双方拼死一搏"<<std::endl;
}else{
war->SetState(new EndState());
war->GetState();
}
}
void CurrentState(War* war){ Anaphase(war); }
};
int
main(){
War* war=new War(new AnaphaseState());
for(int i=1;i<50;i+=5){
war->SetDays(i);
war->GetState();
}
return 0;
}策略模式:
对算法进行封装,处理问题的时候就会有多个算法,与Template模式是相似的,都是为了给业务逻辑具体实现和抽象接口之间的解耦
优点:
1.提供了对“开闭原则”的完美支持,用户可以在不修改原有代码的基础上选择算法或行为,也可以灵活地增加新的算法或行为
2.可避免使用多重条件判断,降低程序维护难度
3.可拓展性强
4.提供了算法的复用机制,不同的环境类可以方便的复用这些策略类
缺点:
1.会导致策略类增多(类爆炸),后期维护困难
2.所有策略类都对外暴露,客户端的权限太大,安全性弱
适用场景:
1.如果在一个系统里面有许多类,它们之间区别仅在于它们的行为,使用策略模式可以动态地让一个对象在许多行为中选择行为
2.一个系统需要动态地在几种算法里面选择一种
3.如果一个对象有很多的行为,如果不用恰当的模式,这些行为就只好使用多重的条件选择语句来实现
注意事项:
如果一个系统的策略多于四个,就需要考虑使用混合模式,解决策略类爆炸问题
代码实现:
#include<iostream>
#include<string>
#include<memory>
class WeaponStrategy{
public:
virtual void UseWeapon()=0;
};
class Knife :public WeaponStrategy{
public:
virtual void UseWeapon(){
std::cout<<"使用匕首"<<std::endl;
}
};
class AK47 :public WeaponStrategy{
public:
virtual void UseWeapon(){
std::cout<<"使用AK47"<<std::endl;
}
};
class Character{
public:
WeaponStrategy* pWeapon;
void setWeapon(WeaponStrategy* pWeapon){
this->pWeapon=pWeapon;
}
void ThrowWeapon(){
this->pWeapon->UseWeapon();
}
};
int
main(){
Character* character=new Character;
WeaponStrategy* knife=new Knife;
WeaponStrategy* ak47=new AK47;
character->setWeapon(ak47);
character->ThrowWeapon();
character->setWeapon(knife);
character->ThrowWeapon();
delete character,knife,ak47;
return 0;
}模板模式:
定义一个操作中的算法的骨架,而将一些步骤延迟到子类中。模板方法使得子类可以不改变一个算法的结构即可重定义该算法的某些特定步骤。
优点:
1.封装不变部分,扩展可变部分
2.提取公共代码,便于维护
3.行为由父类控制,子类实现(实现代码复用)
缺点:
1.每个不同的实现都需要一个子类来实现,导致类的个数增加,使得系统更加庞大
适用场景:
对于某一个业务逻辑在不同对象中有不同的细节实现,但是逻辑的框架是相同的
代码实现:
#include<iostream>
#include<algorithm>
#include<string>
class DrinkTemplate{//做饮料模板
public:
virtual void BoildWater()=0;
virtual void Brew()=0;
virtual void PourInCup()=0;
virtual void AddSomething()=0;
void Make(){
BoildWater();
Brew();
PourInCup();
AddSomething();
}
};
class Coffee :public DrinkTemplate{
virtual void BoildWater(){
std::cout<<"煮山泉水"<<std::endl;
}
virtual void Brew(){
std::cout<<"冲泡咖啡"<<std::endl;
}
virtual void PourInCup(){
std::cout<<"咖啡加入杯中"<<std::endl;
}
virtual void AddSomething(){
std::cout<<"加糖加牛奶"<<std::endl;
}
};
class Tea :public DrinkTemplate{
virtual void BoildWater(){
std::cout<<"煮自来水"<<std::endl;
}
virtual void Brew(){
std::cout<<"冲泡铁观音"<<std::endl;
}
virtual void PourInCup(){
std::cout<<"茶水加入杯中"<<std::endl;
}
virtual void AddSomething(){
std::cout<<"加下雨天氛围"<<std::endl;
}
};
int
main(){
Tea* tea = new Tea;
tea->Make();
Coffee* coffee=new Coffee;
coffee->Make();
return 0;
}访问者模式:
封装一些作用于某种数据结构的各元素的操作,它可以在不改变数据结构的前提下定义作用于这些元素的新的操作。
优点:
1.扩展性良好。扩展对元素的操作,只需要添加访问者
2.满足单一职责原则。相关的操作封装为一个访问者,使得访问者指责单一
3.解耦,数据结构自身和作用于它的操作解耦合
缺点:
1.不易增加类。每增加一个元素类,访问者的接口和实现都要进行变化
2.违背了依赖倒置原则,访问者提供的时具体元素而不是抽象元素
3.破坏封装。访问者可以获取被访问元素的细节
适用场景:
适合数据结构相对稳定且算法又易变化的系统。
代码实现:
#include<iostream>
#include<algorithm>
#include<string>
#include<queue>
#include<List>
class Man;
class Woman;
class Action{
public:
virtual void getManResult(Man* man) =0;
virtual void getWomanResult(Woman* woman) =0;
};
class Success:public Action{
public:
void getManResult(Man* man) override{
std::cout<<"男人的给的评价该歌手是很成功"<<std::endl;
}
void getWomanResult(Woman* woman) override{
std::cout<<"女人给的评价是该歌手很成功"<<std::endl;
}
};
class Fail:public Action{
public:
void getManResult(Man* man) override{
std::cout<<"男人的给的评价该歌手是很失败"<<std::endl;
}
void getWomanResult(Woman* woman) override{
std::cout<<"女人给的评价是该歌手很失败"<<std::endl;
}
};
class Person{
public:
virtual void accept(Action* action) =0;
};
class Man:public Person{
public:
void accept(Action* action)override{
action->getManResult(this);
}
};
class Woman:public Person{
public:
void accept(Action* action)override{
action->getWomanResult(this);
}
};
class ObjectStructure{
public:
void attach(Person* p){
persons.push_back(p);
}
void detach(Person* p){
persons.remove(p);
delete p;
}
//显示测评情况
void display(Action* action){
for(auto value:persons){
value->accept(action);
}
}
private:
std::list<Person*> persons;
};
int
main(){
ObjectStructure* objectStructure =new ObjectStructure;
objectStructure->attach(new Man);
objectStructure->attach(new Woman);
return 0;
}参考:
C++设计模式(全23种)_momohola的博客-CSDN博客
C++几种常用设计模式_c++设计模式_lTimej的博客-CSDN博客
C++常用的11种设计模式_c++ 设计模型_CBoy_JW的博客-CSDN博客
大话设计模式
effective c++
《C++ 设计模式》_c++设计模式_一去丶二三里的博客-CSDN博客文章来源:https://www.toymoban.com/news/detail-851751.html
txinyu的博客_-CSDN博客文章来源地址https://www.toymoban.com/news/detail-851751.html
到了这里,关于C++设计模式(23种)汇总及代码实现的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!