Eliminating Cross-modal Conflicts in BEV Space for LiDAR-Camera 3D Object Detection
摘要
近期,3D目标检测器通常利用多传感器数据和在共享的鸟瞰图(BEV)表示空间中统一多模态特征。然而,我们的实证研究发现,以前的方法在生成无跨模态冲突的融合BEV特征方面存在局限性。这些冲突包括由BEV特征构建引起的外在冲突和源于异质传感器信号的内在冲突。
因此,提出了一种新颖的消除冲突融合(ECFusion)方法,以明确消除BEV空间中的外在/内在冲突,并生成改进的多模态BEV特征。具体而言,设计了一个语义引导的基于流的对齐(SFA)模块,在融合之前通过统一BEV空间中的空间分布来解决外在冲突。此外,我们设计了一个消解查询恢复(DQR)机制,通过保留在融合BEV特征中丢失的目标性线索来弥补内在冲突。
总体而言,ECFusion最大化了每种模态的有效信息利用,并利用了模态间的互补性。ECFusion在竞争激烈的nuScenes 3D目标检测数据集上取得了最先进的表现。
Introduction
三维目标检测对于实现安全高效的自动驾驶至关重要,它让车辆能够准确地在现实世界的三维环境中定位和识别物体。为了达到精确可靠的三维目标检测,一些方法通过多种多模态融合策略结合来自激光雷达点云和摄像头RGB图像的信息。具体来说,点云提供了准确的3D定位信息,而RGB图像则提供了丰富的上下文细节。因此,结合这些互补的模态提高了三维目标检测的准确性和鲁棒性。最近,先进的方法[1, 2]试图在统一的鸟瞰图(BEV)空间中融合激光雷达-相机特征。
通常,鸟瞰图(BEV)空间为多模态特征融合提供了一个合适的中间表示。然而,现有的融合策略仅考虑了模态间互补BEV特征所带来的好处,而忽略了跨模态冲突所引起的干扰。然而,我们认为,受异构跨模态特征间冲突影响的多模态融合操作可能会损害准确预测。特别是,跨模态冲突主要来自两个方面,即外在冲突和内在冲突。
外在冲突源于在不同模态构建BEV特征过程中的变异性。具体来说,由于LiDAR和摄像头模态是由独立编码器分别提取并使用不同的投影方法映射到BEV的,因此它们表现出空间上错位的BEV特征分布。因此,这些错位在合并时不可避免地导致错误的物体信息。例如,图1(a)所示,在LiDAR预测中可以正确定位的汽车,在摄像头BEV中却明显存在空间特征错位,因为基于不确定深度的冗余物体被投影。这种来自特征投影的外在冲突导致融合预测中出现假阳性。
内在冲突源于模态间传感器信号的差异模式。具体而言,由于物体距离、光照、天气状况、遮挡情况等因素的影响,多模态特征对不同物体表现出不对称的感知能力。先前的方法预期具有更优越感知能力的模态将主导融合过程。然而,我们发现另一个模态过弱的物体置信度同样会阻碍正确结果。如图1(b)所示,由于丰富的图像视觉线索,摄像头可以召回远距离和小型的行人和交通锥,而在LiDAR预测中却因稀疏点结构而遗漏。这种来自传感器信号的内在冲突导致融合预测中出现假阴性。因此,在使用多模态特征实现准确和鲁棒检测时,跨模态冲突是一个不容忽视的因素。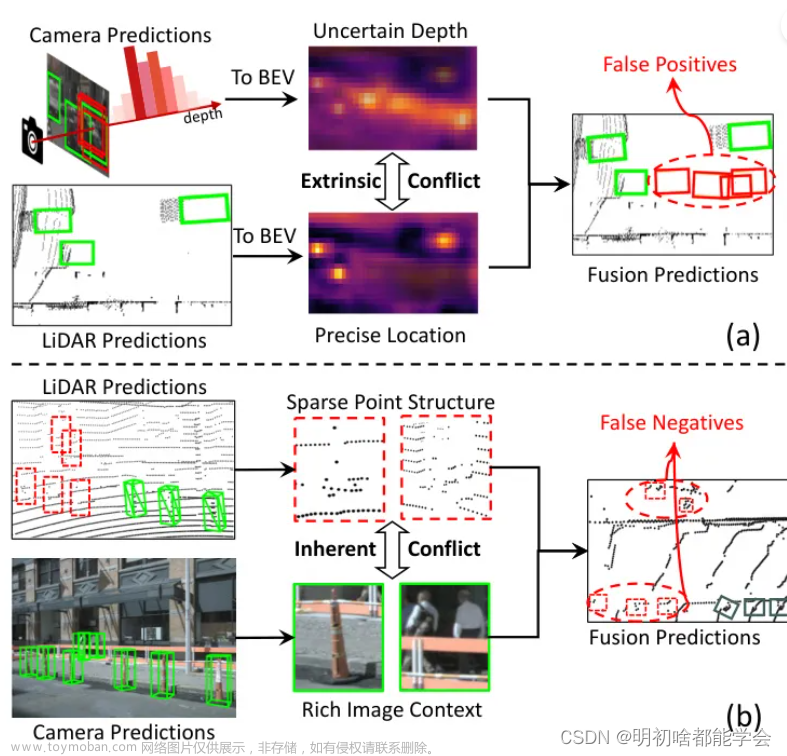
在本文中,我们提出了一种消除冲突融合(ECFusion)方法,以避免融合过程中因冲突造成的感知能力退化。首先,为了消除外在冲突,我们提出了一个基于流的对齐的语义引导(SFA)模块,该模块通过使用从语义对应中导出的空间流,将激光雷达和相机鸟瞰图(BEV)特征对齐到一致的分布。
具体来说,首先将具有类别感知Heatmap语义信息的对应位置与另一种模态进行关联。然后,将这种对应转换为流场,用于传播BEV特征以便对齐。通过这种方式,可以在融合之前通过对齐来减轻由外在冲突引起的融合干扰。其次,为了消除内在冲突,引入了一种消解查询恢复(DQR)机制,旨在发现因内在冲突而在融合Heatmap中溶解的目标查询,并从单独的激光雷达和相机BEVHeatmap中恢复它们。
具体而言,除了像先前方法那样从融合Heatmap中生成目标查询外,我们还探索潜在的单模态目标查询。我们通过Mask Heatmap策略关注那些与融合特征不一致地表现出高对象性的位置。我们的设计旨在确保最大限度地利用单模态特征中的感知能力。
贡献总结如下:
研究了在将多模态特征融合到统一鸟瞰图(BEV)空间时被忽略的跨模态冲突,以及它们如何阻碍激光雷达-相机三维目标检测。
提出了ECFusion方法,以消除多模态BEV特征之间的冲突,包括在融合前进行空间对齐的SFA模块,以及融合后恢复有用对象查询的DQR机制。
广泛的实验表明,ECFusion在nuScenes数据集上实现了激光雷达-相机3D目标检测的最先进性能。
本文方法
如图4所示,ECFusion方法首先利用激光雷达和相机BEV特征提取分支,从各个模态生成特定模态的BEV特征。然后,利用多模态BEV特征融合分支整合激光雷达和相机BEV特征,形成一个统一的融合BEV特征。
在融合分支中,我们提出了一种基于语义引导的流式对齐(SFA)模块,首先减少激光雷达和相机BEV特征之间的空间分布差异(即外在与冲突),然后再进行融合。接着,基于激光雷达、相机和融合的BEV特征,我们设计了一个消解式查询(Dissolved Query)。
恢复(DQR)机制以生成全面的对象查询。具体来说,DQR机制旨在恢复由于两种模态之间不对称的感知能力(即固有冲突)导致的分解对象查询,这种感知能力来自单模态特征。最后,使用Transformer解码器根据导出的对象查询来预测最终的3D边界框。
Single-Modal BEV Feature Extraction
激光雷达和相机BEV特征提取分支的细节展示在图2中,其中激光雷达和相机BEV特征是分别产生的。
激光雷达鸟瞰图特征提取。对于输入的点云数据
X
p
X_p
Xp,如图2(a)所示,我们首先将它们划分为规则体素
V
p
∈
R
X
u
×
X
×
Z
V_p \in \mathbb{R}^{X_u \times X \times Z}
Vp∈RXu×X×Z,并使用带有3D稀疏卷积的体素编码器来提取特征
F
p
∈
R
X
∗
×
Y
×
Z
×
C
F_p \in \mathbb{R}^{X^* \times Y \times Z \times C}
Fp∈RX∗×Y×Z×C,其中
(
X
,
Y
,
Z
)
(X,Y,Z)
(X,Y,Z) 表示3D体素网格的大小。然后,我们沿着Z轴将
F
p
F_p
Fp 投影到鸟瞰图(BEV)上,并采用几个2D卷积层来获得激光雷达鸟瞰图特征图
B
p
∈
R
X
×
Y
×
C
B_p \in \mathbb{R}^{X \times Y \times C}
Bp∈RX×Y×C。
EF
相机BEV特征提取。对于给定的输入N,视角图像Xr,如图2(b)所示,我们首先通过图像编码器提取特征Fr ∈ RN×HxW×C,其中(H,W)表示图像特征图的大小。为了构建相机BEV特征图Br ∈ RX×Y×C,我们通过Lift-Splat-Shoot (LSS)模块对每个视角的图像特征应用2D →3D视图变换。最后,相同BEV网格内的特征通过BEVPool操作进行聚合。
Semantic-guided Flow-based Alignment
在多模态的鸟瞰图(BEV)特征融合分支中,我们旨在将激光雷达的鸟瞰图特征Bp和相机的鸟瞰图特征B结合起来,构建融合的鸟瞰图特征 Br。然而,先前的方法忽略了这两种鸟瞰图特征之间的外在冲突,即不一致的空间/语义分布模式,并直接将两种鸟瞰图特征拼接作为融合结果。
请注意,这种外在冲突是由原始信号坐标的差异、鸟瞰图特征提取流程以及投影过程中的不同造成的。例如,将图像特征投影到鸟瞰图空间需要解决病态的单目深度估计问题,这不可避免地会导致预测的对象深度不准确。因此,由于这种不准确的对象深度,投影的相机鸟瞰图特征将包含错误位置上不存在的/冗余的对象,与激光雷达的鸟瞰图特征形成明显的错位。
因此,详细阐述了一个基于语义引导流的对齐(SFA)模块,用于对齐激光雷达和相机鸟瞰(BEV)特征,以在融合前获得一致的空间分布。受到光学流方法的启发,通过在不一致区域应用适当的流变换来修正空间差异。
具体来说,如图3所示,首先建立两种模态之间的空间对应关系。由于激光雷达和相机鸟瞰图特征
B
p
,
B
r
B_p, B_r
Bp,Br 是从两个独立/异构的分支生成的,直接在
B
p
B_p
Bp 和
B
r
B_r
Br 之间建立对应关系是不可行的。因此利用归一化的激光雷达和相机鸟瞰图 Heatmap
H
p
,
H
r
∈
R
X
×
Y
×
N
H_p, H_r \in \mathbb{R}^{X \times Y \times N}
Hp,Hr∈RX×Y×N,其中
N
N
N 是物体类别的数量,来捕捉逐像素的空间对应关系。在技术上基于
q
×
q
q \times q
q×q 邻域内的跨模态语义相似性,为每个像素构建空间对应关系。
首先,从 H p , H r H_p, H_r Hp,Hr 中获得跨模态代价体积 C p , C r ∈ R X × Y × q 2 C_p, C_r \in \mathbb{R}^{X \times Y \times q^2} Cp,Cr∈RX×Y×q2,它们可以表示为:
C p ( i , j ) = ∑ o H p ( i , j ) ⋅ T H ( i + m , j + n ) , C r ( i , j ) = ∑ u H r ( i , j ) ⋅ T H ( i + m , j + n ) . C_p(i,j) = \sum_{o} H_p(i,j) \cdot T_H(i+m,j+n), \\ C_r(i,j) = \sum_{u} H_r(i,j) \cdot T_H(i+m,j+n). Cp(i,j)=o∑Hp(i,j)⋅TH(i+m,j+n),Cr(i,j)=u∑Hr(i,j)⋅TH(i+m,j+n).
其中 m ∈ [ − q / 2 , q / 2 ) , n ∈ [ − q / 2 , q / 2 ) m \in [-q/2, q/2), n \in [-q/2, q/2) m∈[−q/2,q/2),n∈[−q/2,q/2)。
然后使用一个轻量级的卷积块来估计流场 Δ p , Δ r ∈ R X × Y × 2 \Delta_p, \Delta_r \in \mathbb{R}^{X \times Y \times 2} Δp,Δr∈RX×Y×2,它们在模态间起到空间对应关系的作用:
{ Δ p , Δ r } = Conv ( Concat ( B p , C p , B r , C r ) ) . \{ \Delta_p, \Delta_r \} = \text{Conv}(\text{Concat}(B_p, C_p, B_r, C_r)). {Δp,Δr}=Conv(Concat(Bp,Cp,Br,Cr)).
接下来,采用可微的双线性采样操作,基于 { Δ p , Δ r } \{ \Delta_p, \Delta_r \} {Δp,Δr} 对特征进行扭曲,这种操作线性插值了扭曲位置周围邻域的特征。正式地说,对齐的鸟瞰图(BEV)特征 B p , B r B_p, B_r Bp,Br 获取方式如下:
B p ( p ) = Interp ( B ( p + Δ p ) ) , B r ( p ) = Interp ( B ( p + Δ r ) ) , B_p(p) = \text{Interp}(B(p + \Delta_p)), \quad B_r(p) = \text{Interp}(B(p + \Delta_r)), Bp(p)=Interp(B(p+Δp)),Br(p)=Interp(B(p+Δr)),
其中, p ∈ { P , I } p \in \{ P, I \} p∈{P,I},在这里, Interp ( ⋅ ) \text{Interp}(\cdot) Interp(⋅) 表示邻域双线性插值。然后将它们融合为:
B p = Conv ( Concat ( B p , B r ) ) . B_p = \text{Conv}(\text{Concat}(B_p, B_r)). Bp=Conv(Concat(Bp,Br)).
得益于融合前的基于流的空间对齐,它避免了由外部冲中突引起的特征不协调。
Dissolved Query Recovering Mechanism
基于融合的鸟瞰图(BEV)特征
B
p
B_p
Bp,遵循[3]的方法,大多数先前方法直接生成类特定的融合 Heatmap
H
p
∈
R
X
×
Y
×
N
e
H_p \in \mathbb{R}^{X \times Y \times N_e}
Hp∈RX×Y×Ne 并选择 Top-Kp 局部最大候选索引。所选候选者的信息用于初始化对象查询
Q
r
∈
R
K
r
×
C
Q_r \in \mathbb{R}^{K_r \times C}
Qr∈RKr×C 的上下文特征和位置嵌入,这些查询通过 DETR 风格的解码层用于聚合相关的上下文和预测框参数。
因此,确保初始查询的高质量对准确检测至关重要,因为如果没有相应的查询,对象是不太可能被回忆起来的。从理论上讲,我们期望融合查询 能够整合来自点云和图像模态的所有有价值的目标性线索,使它们能够继承每种模态的独特检测能力。
然而,我们发现当前的方法
(
{
G
T
p
∪
G
T
r
}
)
( \{GT_p \cup GT_r\} )
({GTp∪GTr}),如图5所示,这意味着在
(
{
G
T
p
∪
G
T
r
}
)
( \{GT_p \cup GT_r\} )
({GTp∪GTr}) 中的许多对象,如果未被融合查询匹配,可以通过模态特定查询来回忆。我们的研究显示,尽管当前方法学到的融合策略确实可以识别新对象,但它将牺牲不可忽视的单模态检测能力的一部分。因此,研究如何在利用跨模态互补的同时保持单模态检测能力是至关重要的。文章来源:https://www.toymoban.com/news/detail-851925.html
因此,我们提出了一个溶解查询恢复(Dissolved Query Recovering, DQR)机制,以明确保持单一模态的检测能力。我们的基本概念围绕着探索那些因冲突而溶解在融合Heatmap中的查询,但可以从单一模态Heatmap中恢复的查询。此外,我们还全面整合了多源查询,以提高召回率。
在训练过程中,我们采用了文献[1]中提出的匹配成本和损失函数。具体来说,我们优化了所有边界框预测的检测损失
L
p
L_p
Lp,这包括对所有结果的分类损失以及与GT框匹配的正样本对的位置回归损失。此外,我们还使用了Focal Loss
L
H
z
∈
F
L_{Hz} \in F
LHz∈F,用于三种Heatmap预测,这些预测由GT框中心生成的具有高斯分布的GT图。需要注意的是,对于
L
p
L_p
Lp 和
L
H
z
L_{Hz}
LHz,GT图应该通过融合掩码
M
M
M 同步进行遮蔽。总损失定义为
L
=
L
d
e
t
+
L
H
L = L_{det} + L_{H}
L=Ldet+LH。文章来源地址https://www.toymoban.com/news/detail-851925.html
到了这里,关于消除 BEV 空间中的跨模态冲突,实现 LiDAR 相机 3D 目标检测的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!



![C#【疑难杂症篇】请考虑使用 app.config 将程序集“xxx“从版本“4.0.0.0”[xxx]重新映射到版本“4.0.1.0”[xxx],以解决冲突并消除警告。](https://imgs.yssmx.com/Uploads/2024/02/441257-1.png)