在线工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 3D场景编辑器
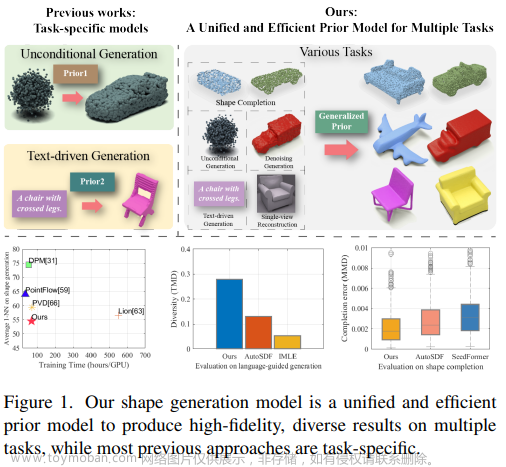
为了生成有用的图像数据集,我们使用真实世界的照片数据集作为指南针,探索即时工程的艺术。 我们的稳定扩散(Stable Diffusion)实验显示了生成模仿现实世界场景的多样化且令人信服的图像的复杂性。
由于很难手动确定某些即时修改何时会改善我们的合成数据集或使其变得更糟,因此我们引入了一个包含4个指标的定量框架来对任何合成数据集的质量进行评分。 本文逐步演示了这些质量分数如何指导及时的工程工作以生成更好的综合数据集。 同样的系统评估还可以帮助你优化合成数据生成器的其他方面。
如果你的机器学习任务需要自动标注局部区域,比如目标检测,那么用稳定扩散就不容易实现自动标注,更好的方法是使用 UnrealSynth这样的基于游戏引擎的合成数据生成器,能够自动生成包含标注的图像集,非常方便:

https://tools.nsdt.cloud/UnrealSynth
1、评估合成数据集的质量
根据任何提示生成合成数据后,你会想知道合成数据集的优点/缺点。 虽然可以通过简单地逐一查看生成的样本来获得想法,但这既费力又不系统。 Cleanlab Studio 提出了一种自动化方法来定量评估合成数据集的质量。 当你提供真实数据和应该增强它的合成数据时,该方法会计算四个分数,从不同方面对比你的合成数据与真实数据:
- 不真实(Unrealistic):此分数衡量合成数据与真实数据的难以区分程度。 高值表明存在许多看起来不切实际的合成样本,这些样本显然是假的。 从数学上讲,该分数的计算方法为 1 减去具有真实或合成二进制标签的联合数据集中所有合成图像的平均标签问题分数。
- 不具有代表性(Unrepresentative):该分数衡量真实数据在合成数据样本中的代表性程度。 高值表明可能存在合成样本分布无法捕获的真实数据分布的尾部(或罕见事件)。 从数学上讲,该分数的计算方式为 1 减去具有真实或合成二进制标签的联合数据集中所有真实图像的平均标签问题分数。
- 变化太少(Unvaried):该分数衡量合成样本之间的差异程度。 高值表明合成数据生成器过于重复,生成了许多看起来彼此相似的样本。 从数学上讲,该分数的计算方式为 1 减去与其他合成样本接近重复的合成样本的比例。
- 非原创(Unoriginal):该分数衡量合成数据的新颖性。 高值表明许多合成样本看起来像是真实数据集中发现的内容的副本,即合成数据生成器可能过于紧密地记忆真实数据而无法泛化。 从数学上讲,该分数的计算方式为 1 减去与真实数据集中的示例几乎重复的合成样本的比例。

这些的具体例子是它们所揭示的分数和缺点,将在本文中进一步介绍。 你可以按照本教程计算自己的合成图像/文本/表格数据的这些分数(并了解它们的数学细节)。 这四个定量分数可通过单一 Python 方法计算,帮助你严格比较不同的合成数据生成器(即提示模板),特别是当通过手动检查样本无法立即清楚差异时。
2、零食数据集
在本文中,我们在合成图像生成方面的工作基于 Snacks 数据集。 该数据集包含 20 种不同类别食品的 4838 张实际照片。
来自 Snacks 数据集的随机照片
该数据集描述了广泛的零食类型(从水果到饮料)并且具有丰富的深度(每一类食物都以多种方式描述,具有不同的外观/背景)。 我们的目标是生成一个合成数据集,该数据集可用于:代替真实的 Snacks 数据集,或者使用额外的合成图像来增强原始数据。 正如我们将看到的,正确捕捉这些图像的丰富性并非易事(即使在这个有限的零食领域)。
3、根据提示生成图像
稳定扩散(Stable Diffusion)是一种随机文本到图像模型,可以生成从同一文本提示采样的不同图像。 为稳定扩散设计一个好的提示来生成合成图像数据集需要考虑我们试图模仿的真实图像的几个特征。
3.1 输出格式
首先要考虑的是所需的输出格式。 这涉及图像的媒介和风格,这会影响生成图像的整体外观和感觉。 鉴于我们的零食数据集中的所有图像都是零食的照片,因此在生成的图像中保留这种摄影风格非常重要。 我们可以通过在提示中加入诸如“……的照片”之类的指令来做到这一点。
我们通过使用基本提示生成大量 992 个图像来开始我们的实验。 对于我们的零食图像数据集,它很简单:
prompt = "A photo of a snack"

根据我们的基本提示生成的一些合成图像
这个提示很简单,并且产生视觉上连贯的图像。 然而,这些图像往往是通用的,并且常常缺乏对零食类型的明确定义。
为了定量评估从此提示生成的合成图像数据(与真实 Snacks 数据集的图像进行比较),我们使用一种简洁的方法来计算 Cleanlab Studio 的 Python API 中提供的合成数据集问题分数:
scores = score_synthetic_dataset(real_and_synthetic_dataset)
根据上述提示生成的合成图像数据集的最终分数(值越高越差)为:
| 实验 | 不具代表性 | 不真实 | 缺少变化 | 非原创 |
|---|---|---|---|---|
| 基线提示 | 0.98223 | 0.95918 | 0.0 | 0.0 |
这些分数揭示了有关我们的提示生成的合成数据集的见解:
- 不真实的分数较高表明合成图像与真实图像之间存在明显差异(见下文)。
- 不具代表性的高分表明合成图像没有捕捉到 Snacks 数据集的多样性和细微差别。
- 缺少变化和非原创的分数为0表明我们生成的图像不重复,并且与真实数据相比显得足够新颖。 这是有道理的,因为稳定扩散具有高度的不确定性,并且尚未在我们的 Snacks 数据集上进行明确的微调。

Cleanlab Studio 检测到的基线实验中的合成图像看起来明显是假的(不真实的高分)。
总体而言,从这个单一提示生成的图像几乎没有变化,并且所描绘的零食类型通常不清楚。 值得注意的是,稳定扩散的图像生成过程并不提供有关其旨在生成的零食类型的直接信息。 从像这样的单个提示模板中不太可能获得丰富且具有代表性的合成数据集。
3.2 主题
图像的主题是我们的提示工程策略中要考虑的下一个方面。 我们可以通过合并有关目标分类的信息来使提示更加具体。 这使我们能够更好地控制生成的图像内容,旨在使合成数据集与原始数据集中的类分布保持一致。
对于我们的零食数据集,主题与每张图像中显示的特定零食类型直接相关。
# Pseudocode
for each class_name in class_names:
if class_name starts with a vowel:
prompt = "A photo of an " + class_name
else:
prompt = "A photo of a " + class_name
通过以这种方式包含主题,每个提示都变得更有针对性。 我们现在不再使用通用的“零食照片”,而是使用“香蕉照片”或“苹果照片”等明确提示。 通过使用这些特定于类别的提示为每个类别生成 96 个图像,我们的目标是创建更准确地代表 Snacks 数据集中找到的各个类别的图像。 为了使此方法顺利运行,类名应该清晰、具体且一致。 如果它们不明确或模糊,生成的图像可能与预期主题不准确匹配。

一些根据基于主题的提示生成的合成图像
为了评估基于类别的提示生成的合成数据,我们再次采用自动质量评分方法:
scores = score_synthetic_dataset(real_and_synthetic_dataset)
我们的新实验生成的合成数据集得出以下分数:
| 实验 | 不具代表性 | 不真实 | 缺少变化 | 非原创 |
|---|---|---|---|---|
| 主题聚焦提示 | 0.99674 | 0.95775 | 0.0261 | 0.0 |
-
不真实的分数的边际下降表明,在以类别为中心的提示驱动下,特定的合成图像现在紧密地反映了同一类型的真实图像,并且总体上显得更加真实。
-
尽管提示侧重于类别,但不具有代表性的分数的增加表明,由提示“……的照片”产生的合成图像集合并不能完全捕获 Snacks 数据集中更广泛的多样性。
-
缺少变化的分数增加表明一些合成图像可能是彼此几乎相同的版本(这并不意外,因为我们的新提示不太开放)。 这是使提示更加具体的危险,生成的合成数据将变得不那么多样化!

-
Cleanlab Studio 检测到的合成图像之间几乎重复,导致较高的缺少变化分数。
非原创分数仍然很低,表明我们的合成样本似乎都不是直接从真实数据复制的(这是预期的,因为我们从未在本文中使用真实数据训练稳定扩散生成器)。
3.3 上下文
我们可以用来改进提示的另一件事是上下文。 指主体所处的背景或周围情况。 通过稳定扩散,模型在很大程度上决定了生成图像的背景或设置。 但是,通过在之前的课堂提示中添加“上下文规则”,我们可以尝试影响图像的这一部分。
我们的增强提示如下所示:
prompt = class_prompt + " " + context_rule
就我们的零食数据集而言,我们对零食通常可能出现的可想象场景或上下文进行了启发式选择。 对于实际应用,建议基于对现有数据的分析(例如不同背景的相对频率),有条理地选择上下文。
context_rules = [
"in a bowl",
"on a plate",
"in a bag",
"at the supermarket",
"in a basket",
"on a shelf",
]

一些根据我们的上下文增强提示生成的合成图像
我们生成了一个包含 4800 张来自不同类别 + 上下文组合的图像的合成数据集。 为了衡量上下文增强提示的有效性,我们再次使用 Cleanlab 的自动质量评分:
scores = score_synthetic_dataset(real_and_synthetic_dataset)
我们的合成数据集本次迭代的得分为:
| 实验 | 不具代表性 | 不真实 | 缺少变化 | 非原创 |
|---|---|---|---|---|
| 上下文提示 | 0.99931 | 0.99604 | 0.0117 | 0.0 |
分析结果如下:
- 不具代表性的分数的进一步增加强调,虽然上下文驱动的提示提供了一个新的角度,但期望它们自己捕获全部可能的图像是不合理的。

描述 Cleanlab Studio 检测到的场景的真实图像在合成数据集中代表性不足。 第一行显示了几张真实的图像,其中包括人们和零食。 底行显示在合成数据集中没有很好地表示的欠光图像。
- 不真实分数的增加表明,某些合成图像在受到我们的上下文规则约束时,显得不太自然,从而使它们与真实图像更容易区分。 并非每个上下文规则都适合每个类; 想象“盘子里的果汁”或“篮子里的冰淇淋”可能会产生与现实不一致的荒谬图像。
稳定扩散在图像生成方面表现出色,但捕捉现实世界的全部多样性仍然是一个挑战。 虽然我们的基线数据集是多种多样的,但它在监督学习环境中却表现不佳。 另一方面,课堂提示提高了真实感,但留下了许多真实图像的代表性不足。 令人惊讶的是,特定的背景提示加剧了这种代表性不足的情况。 我们的外卖? 课堂提示是我们获得更丰富的合成数据集的最佳选择。 为了真正超越并填补这些空白,完善我们的上下文提示是前进的方向。
在所有提示中,不切实际且不具代表性的分数都相当高。 稳定扩散倾向于在提示中对主题进行精美、理想化的描述。 这与真实数据集的自发性和多变性形成鲜明对比,真实数据集包含了我们在合成图像中无法真正观察到的各种照明条件、复杂的背景和模糊的上下文。
4、你的提示能激发出一千张独特的图像吗?
如今,提示工程(Prompt Engineering)是有效生成合成图像的关键。 本文演示了一种使用稳定扩散模型和 Snacks 数据集生成多样化且真实的合成图像数据集的方法。 这些策略也可以应用于许多其他环境。 设计有效提示的艺术是一种微妙的平衡——阐明太多细节可能会导致过于具体的图像,而保持太模糊可能会导致缺乏多样性。
Cleanlab Studio提出的对合成数据质量的定量评估对这一迭代过程有很大帮助。 通过自动化评估阶段,它使你能够更加专注于完善提示和改进合成图像(而不是费力地了解自己是否取得了进展)。文章来源:https://www.toymoban.com/news/detail-851933.html
原文链接:稳定扩散合成数据的评估 — BimAnt文章来源地址https://www.toymoban.com/news/detail-851933.html
到了这里,关于用扩散AI生成的合成数据的质量评估方法【4个指标】的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!


![深度学习应用篇-计算机视觉-OCR光学字符识别[7]:OCR综述、常用CRNN识别方法、DBNet、CTPN检测方法等、评估指标、应用场景](https://imgs.yssmx.com/Uploads/2024/02/705153-1.png)